

JUC之LongAdder源码分析
前言
LongAdder和LongAccumulator类是JDK8新增的原子操作类,位于java.util.concurrent.atomic包下。
LongAdder只能从0开始以1为步长做加法,而LongAccumulator提供了自定义函数操作,初始值可以不为0,步长不固定,可以做减法。
那么为什么要新增这类型呢?一般来说,JDK新增一个类都是为了解决之前类的一些痛点,例如JDK8新增的StampedLock(邮戳锁)就是对ReentrantReadWriteLock的优化,CompletableFuture是对Future的优化,而LongAdder类就是对AtomicLong的优化。
JDK中Atomic开头的类,底层原理都是通过CAS + volatile来保证原子性的。CAS是一个乐观锁的机制,认为数据不会冲突,会尝试更新,失败的话会自旋重试,这样就会引入一个问题了,就是在高并发下,自旋空转时间就会被放大,而LongAdder就是为了解决这个问题引入的。
在JDK源码的注释中提到,该类在高并发下比AtmicLong具有更好的性能。
/**
* ....
* <p>This class is usually preferable to {@link AtomicLong} when
* multiple threads update a common sum that is used for purposes such
* as collecting statistics, not for fine-grained synchronization
* control. Under low update contention, the two classes have similar
* characteristics. But under high contention, expected throughput of
* this class is significantly higher, at the expense of higher space
* consumption.
* ...
*/
在阿里的Java开发手册(1.7.1,黄山版)的编程规约的第八章的17点也推荐LongAdder。

性能测试
下面来性能测试验证下,主要对比原子类,同时加上一组Synchronized做对比。
使用JMH,版本为:1.36,8线程写2线程读,测试代码如下:
package org.lgq.juc;
import org.openjdk.jmh.annotations.*;
import org.openjdk.jmh.results.format.ResultFormatType;
import org.openjdk.jmh.runner.Runner;
import org.openjdk.jmh.runner.RunnerException;
import org.openjdk.jmh.runner.options.Options;
import org.openjdk.jmh.runner.options.OptionsBuilder;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.atomic.AtomicInteger;
import java.util.concurrent.atomic.AtomicLong;
import java.util.concurrent.atomic.LongAccumulator;
import java.util.concurrent.atomic.LongAdder;
/**
* @author DevLGQ
* @version 1.0
*/
@Fork(1) // 1一个进程进行测试,是单独运行在Processor进程里,做到完全隔离
@Threads(5) // 并行测试线程。Threads.MAX 等于机器核数
@Warmup(iterations = 3) // JIT预热。iterations迭代次数
@State(Scope.Group)
@Measurement(iterations = 5, time = 5) // 迭代10次,每次5s
@BenchmarkMode(Mode.Throughput) // 使用吞吐量
@OutputTimeUnit(TimeUnit.MILLISECONDS) // 结果所使用的时间单位
public class TestLongAdder {
/**
* 点赞类
*/
private ThumbsUp thumbsUp;
/**
* 初始化
*/
@Setup
public void init() {
thumbsUp = new ThumbsUp();
}
@Benchmark
@Group("sync")
@GroupThreads(8)
public void syncInc() throws Exception {
thumbsUp.addSync();
}
@Benchmark
@Group("sync")
@GroupThreads(2)
public int getSyncNumber() {
return thumbsUp.getSync();
}
@Benchmark
@Group("atomicInteger")
@GroupThreads(8)
public void atomicIntegerInc() throws Exception {
thumbsUp.addAtomicInteger();
}
@Benchmark
@Group("atomicInteger")
@GroupThreads(2)
public int getAtomicInteger() throws Exception {
return thumbsUp.atomicInteger.get();
}
@Benchmark
@Group("atomicLong")
@GroupThreads(8)
public void atomicLongInc() throws Exception {
thumbsUp.addAtomicLong();
}
@Benchmark
@Group("atomicLong")
@GroupThreads(2)
public long getAtomicLong() throws Exception {
return thumbsUp.atomicLong.get();
}
@Benchmark
@Group("longAdder")
@GroupThreads(8)
public void longAdderInc() throws Exception {
thumbsUp.addLongAdder();
}
@Benchmark
@Group("longAdder")
@GroupThreads(2)
public long getLongAdder() throws Exception {
return thumbsUp.longAdder.longValue();
}
@Benchmark
@Group("longAccumulator")
@GroupThreads(8)
public void longAccumulatorInc() throws Exception {
thumbsUp.addLongAccumulator();
}
@Benchmark
@Group("longAccumulator")
@GroupThreads(2)
public long getIongAccumulator() throws Exception {
return thumbsUp.longAccumulator.longValue();
}
public static void main(String[] args) throws RunnerException {
Options options = new OptionsBuilder()
.include(TestLongAdder.class.getSimpleName())
.result("./longAdder-simple.json")
.resultFormat(ResultFormatType.JSON)
.build();
new Runner(options).run();
}
}
class ThumbsUp {
int syncNumber = 0;
public synchronized void addSync() {
syncNumber++;
}
public synchronized int getSync() {
return syncNumber;
}
AtomicInteger atomicInteger = new AtomicInteger();
public void addAtomicInteger() {
atomicInteger.incrementAndGet();
}
AtomicLong atomicLong = new AtomicLong();
public void addAtomicLong() {
atomicLong.incrementAndGet();
}
LongAdder longAdder = new LongAdder();
public void addLongAdder() {
longAdder.increment();
}
LongAccumulator longAccumulator = new LongAccumulator(Long::sum, 0);
public void addLongAccumulator() {
longAccumulator.accumulate(1);
}
}
测试结果导出json格式,结果可视化使用jmh.morethan.io,这里也可以导出为csv格式,直接使用excel进行绘图。

可以看到,LongAdder的性能确实更优。
原理解析
这里直接先说实现原理,知道原理后再看源码可以更容易懂。
那为什么会更快呢?实际在JDK源码的注释上也说:
But under high contention, expected throughput of this class is significantly higher, at the expense of higher space consumption.
在高并发下,该类的吞吐量会更高,但是代价就是空间消耗会更多。其实这里就是一个很经典的思想:空间换时间。
那么如何空间换时间呢?
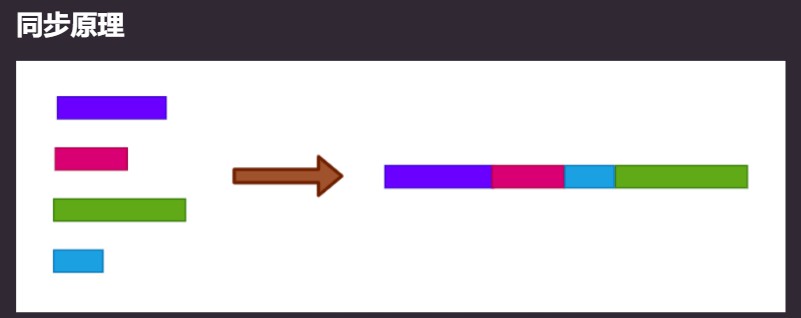
分散热点,将value值分散到一个 Cell数组 上,不同线程会命中到数组的不同槽中,各个线程只对自己槽中的那个值进行CAS操作,这样冲突概率就变小了,空旋也就减少了。当需要获取真正的long值时,只要将各个槽的变量值累加返回即可。原理图如下:

Base变量,非竞争条件下累加到该变量下;竞争条件下,累加到各个线程的槽Cell[i]上;需要结果的时候再累加:
简单的来说,就是LongAdder在无竞争的情况下,跟AtomicLong一样,对同一个value进行操作;当出现竞争时,采用分治思想,用空间换时间,将一个value拆分进一个Cells数组;要获取最终结果时,就将数组Cells的所有值和无竞争值base都加起来,也是因为这个LongAdder统计的值不是实时精确的。
源码分析
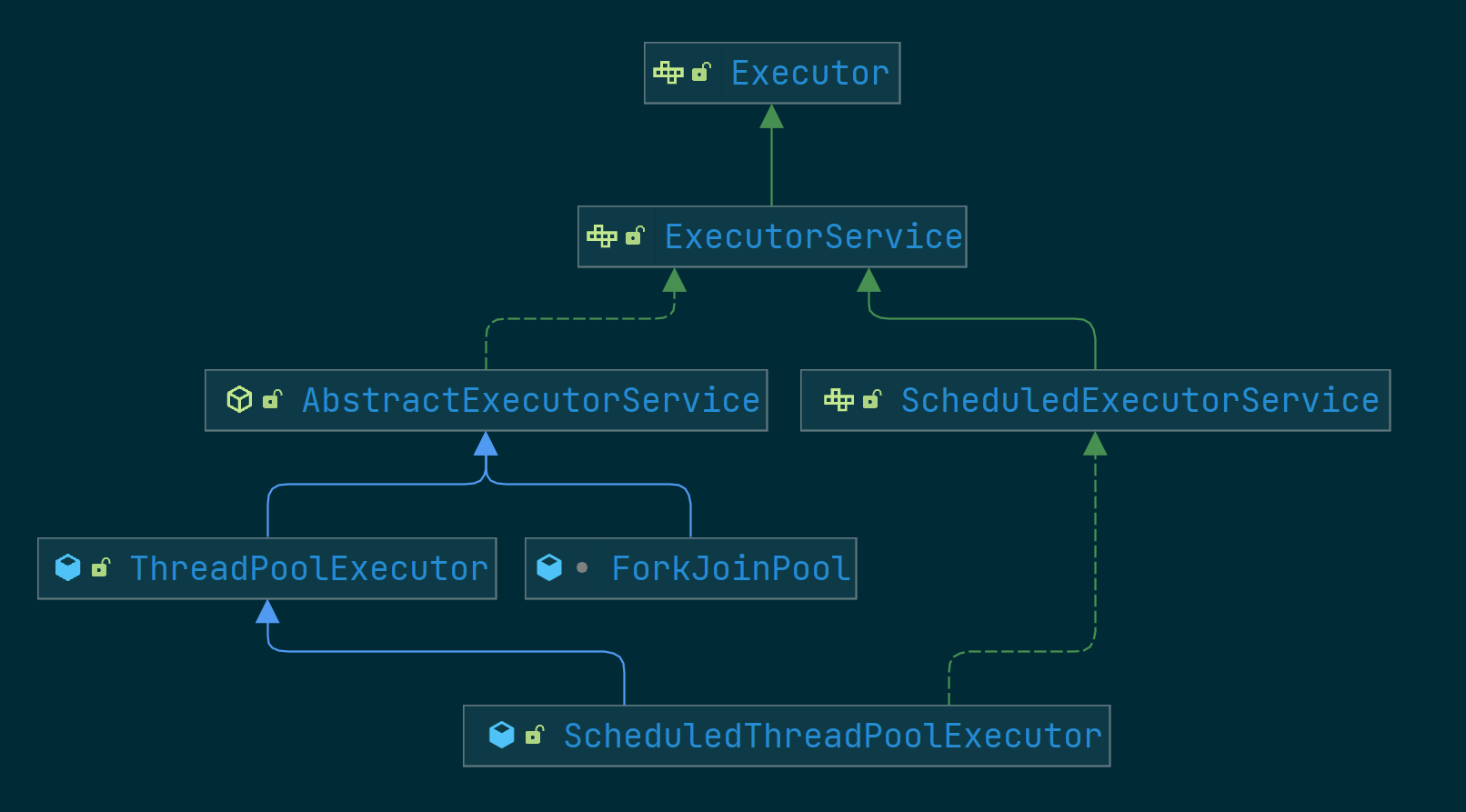
下面来分析下源码(基于JDK21,其它版本可能会不一样),继承结构如下:

可以看到,LongAdder的重要属性都在父类Striped64里:
// CPU数量,也是 cells 的最大长度,扩容时需要用到
static final int NCPU = Runtime.getRuntime().availableProcessors();
// Cell数组,长度为2的幂
transient volatile Cell[] cells;
// 基础value值,当并发较低时,只累加该值,主要用于没有竞争的情况,通过CAS更新
transient volatile long base;
// 创建或扩容cells数组时使用的自旋锁变量调整单元格大小(扩容),创建单元格时使用的锁
// 0 表示无锁;1 表示加锁了
transient volatile int cellsBusy;
// VarHandle mechanics
private static final VarHandle BASE;
private static final VarHandle CELLSBUSY;
private static final VarHandle THREAD_PROBE;
其中VarHandle类型的BASE和CELLSBUSY,其实是对base和cellsBusy变量的包装,通过BASE和CELLSBUSY对这两个值进行CAS操作,而THREAD_PROBE属性它指向Thread类的threadLocalRandomProbe属性,探测哈希值,下面用于计算数组的下标。
更早的JDK版本是使用Unsafe类进行CAS的,而VarHandle是JDK17引入的新特征,提供了一种在运行时访问和修改对象字段的安全方式,包括私有字段和 final 字段,它比Unsafe更安全。
而java.util.concurrent.atomic.Striped64.Cell源码如下:
@jdk.internal.vm.annotation.Contended static final class Cell {
// 维护了一个 value 值
volatile long value;
Cell(long x) { value = x; }
final boolean cas(long cmp, long val) {
return VALUE.weakCompareAndSetRelease(this, cmp, val);
}
final void reset() {
VALUE.setVolatile(this, 0L);
}
final void reset(long identity) {
VALUE.setVolatile(this, identity);
}
final long getAndSet(long val) {
return (long)VALUE.getAndSet(this, val);
}
// VarHandle mechanics
private static final VarHandle VALUE;
static {
try {
MethodHandles.Lookup l = MethodHandles.lookup();
VALUE = l.findVarHandle(Cell.class, "value", long.class);
} catch (ReflectiveOperationException e) {
throw new ExceptionInInitializerError(e);
}
}
}
看完结构后看逻辑,从increment方法进去,传了个1给add方法:
public void increment() {
add(1L);
}
java.util.concurrent.atomic.LongAdder#add源码:
public void add(long x) { // x 一直都是1
// cs 表示Striped64的Cells属性
// b 表示Striped64的base属性
// v 表示当前线程hash到Cell中需要存的值
// m 表示 Cells 的 长度-1,hash时作为掩码使用
// c 当前线程命中的Cell
Cell[] cs; long b, v; int m; Cell c;
// 首次第一个线程 (cs = cells) != null 一定是false,此时继续走 casBase 方法,以CAS的方式更新base值,当cas失败时,说明高并发(竞争激烈,只有一个能成功),说明这时候需要扩容或者说是需要去更新Cells数组了;如果成功,说明是低并发。
// 条件1:Cells不为空,说明出现过竞争,Cells已经创建
// 条件2:cas操作失败,说其它线程先进一步修改base,说明竞争开始激烈了
if ((cs = cells) != null || !casBase(b = base, b + x)) {
// 获取当前线程的 hash 值,返回的是线程中的 threadLocalRandomProbe 字段
// 通过随机生成的一个值,对于一个确定的线程来说,这个值是固定的
// 对应的 advanceProbe(int probe) 方法重置当前线程的hash值
int index = getProbe();
// uncontended 没有冲突之意
// true 没有竞争,false表示竞争激烈,多个线程hash到同一个Cell了,需要扩容
boolean uncontended = true;
// 条件1:Cells为空,说明正在出现竞争,Cells还没创建,从上面条件2过来的
// 条件2:应该不会出现,判断Cells的长度
if (cs == null || (m = cs.length - 1) < 0 ||
// 条件3:当线程所在的Cell为空,说明当前线程还没有更新过Cell,应该初始化一个Cell
(c = cs[index & m]) == null ||
// 条件4:更新当前所在的Cell失败,说明现在竞争很激烈,多个线程hash到同一个Cell了,需要扩容
!(uncontended = c.cas(v = c.value, v + x)) ) {
// 调用父类Striped64的longAccumulate方法处理,最多扩容到CPU核数
longAccumulate(x, null, uncontended, index);
}
}
}
// java.util.concurrent.atomic.Striped64#casBase
// CAS的方式更新值
final boolean casBase(long cmp, long val) {
return BASE.weakCompareAndSetRelease(this, cmp, val);
}
在JUC中,应该说在并发编程中,会发现方法中对成员变量的使用都是先赋值给局部变量的,这样做的原因是为了提高执行效率,是一种字节码友好的优化方式。
访问成员变量需要通过对象引用来进行,而方法内局部变量的话可以在栈上进行访问,如果需要多次访问的话,先赋值给局部变量,可以提高执行速度。下面从字节码角度分析:// 从字节码的角度 // 在赋值之后,之后访问局部变量只需要一个指令 aload_1 // 而访问成员变量需要两个指令 // 0下标就是对象本身this // 而第二个指令,根据索引去运行时常量池找到对象,明显是耗时的,所以先直接存好成员变量的地址之后复用效率可以更高 aload_0 getfield #24 <org/lgq/juc/LocalVar.user : Lorg/lgq/entities/User;>实际,这也是一种空间换时间的思想,使用局部变量,虚拟机栈的本地变量表占用也会变大。
java.util.concurrent.atomic.Striped64#longAccumulate()源码:
// x:一般都是默认1
// fn:当前传的是null
// wasUncontended:竞争标识,false标识有竞争,只有cells初始化之后,并且当前线程CAS修改失败后才会false
// index:是线程的hash值
final void longAccumulate(long x, LongBinaryOperator fn,
boolean wasUncontended, int index) {
// Probe hash value; nonzero if threadLocalRandomSeed initialized
// 0说明没有hash值,强制初始化
if (index == 0) {
// 使用ThreadLocalRandom为当前线程重新计算一个hash值,强制初始化
ThreadLocalRandom.current(); // force initialization
// hash值被重置就好比一个全新的线程一样,所以设置 wasUncontended 竞争状态为true
// 该值就是 threadLocalRandomProbe
index = getProbe();
// 重新计算了当前线程的hash后认为此次不算一次竞争,都未初始化,肯定不存在竞争激烈
wasUncontended = true;
}
// 进入自旋,总体来看,分 三个分支
// 如果hash取模映射得到的Cell单元不是null,则为true,此值可以看作是扩容意向
for (boolean collide = false;;) { // True if last slot nonempty
Cell[] cs; Cell c; int n; long v;
// Case1:Cells已经被初始化了
if ((cs = cells) != null && (n = cs.length) > 0) {
// 如果当前线程的hash值运算后映射到的Cell单元为null,说明该Cell没有被使用
if ((c = cs[(n - 1) & index]) == null) {
// Cells数组也没有正在扩容
if (cellsBusy == 0) { // Try to attach new Cell
// 创建一个Cell单元
Cell r = new Cell(x); // Optimistically create
// 双端检查,尝试加锁,成功后 cellsBusy 为 1
if (cellsBusy == 0 && casCellsBusy()) {
try { // Recheck under lock
Cell[] rs; int m, j;
// 再检查一遍之前的判断,看是否有其它线程占用这个坑了
if ((rs = cells) != null &&
(m = rs.length) > 0 &&
rs[j = (m - 1) & index] == null) {
// 将创建的Cell放进Cells数组上
rs[j] = r;
break;
}
} finally {
// 释放锁
cellsBusy = 0;
}
continue; // Slot is now non-empty
}
}
collide = false;
}
else if (!wasUncontended) // CAS already known to fail
// 表示Cells初始后,当前线程竞争修改失败,一开始传进来就是 false
// 这里只是将该值设置为true,然后重置当前线程的hash,重新循环
wasUncontended = true; // Continue after rehash
else if (c.cas(v = c.value,
(fn == null) ? v + x : fn.applyAsLong(v, x)))
// 进行写的操作,fn当前传null
// 说明当前线程的数组中已经有数据了,也重置过hash值
// 这时候就通过CAS操作尝试把当前数中的value值进行累加1,成功就跳出循环
break;
else if (n >= NCPU || cells != cs)
// 如果n大于CPU的最大数量了,不可再扩容
// 然后通过后面的 advanceProbe 方法修改线程的 probe 值后再尝试
collide = false; // At max size or stale
else if (!collide)
// 没有达到最大值,可以扩容,设置为 true
// 然后重新计算线程的hash值后继续循环
collide = true;
else if (cellsBusy == 0 && casCellsBusy()) {
// 开始扩容
try {
// 当前Cells数组和最先赋值的是同一个,说明没有被其他线程扩容过
if (cells == cs) // Expand table unless stale
cells = Arrays.copyOf(cs, n << 1); // 左移一位,扩容为原来的2倍
} finally {
// 释放锁
cellsBusy = 0;
}
// 设置为不需要扩容
collide = false;
continue; // Retry with expanded table
}
// 重置当前线程的hash值
index = advanceProbe(index);
}
// Case2:Cells没有加锁且没有初始化,则尝试对它进行加锁,并初始化Cells数组
// cellsBusy:锁,0:表示无锁,1:表示其它线程持有锁了
// casCellsBusy:通过CAS获取锁
// cs:方法内部创建的 Cells 数组,这时候应该是null,cells是成员变量,如果等于cs,说明引用没有修改
else if (cellsBusy == 0 && cells == cs && casCellsBusy()) {
try { // Initialize table 新建Cells数组
// 双端检查,判断是否被上一个获取到锁的线程修改了
if (cells == cs) {
// 默认长度为2
Cell[] rs = new Cell[2];
// 找到当前线程对应的位置创建Cell
rs[index & 1] = new Cell(x); // x -> 1
// 把成员变量cells指向新创建的数组
cells = rs;
break;
}
} finally {
// 释放锁
cellsBusy = 0;
}
}
// Fall back on using base
// Case3:cells正在初始化,则尝试直接在基数base上进行累加操作
else if (casBase(v = base,
(fn == null) ? v + x : fn.applyAsLong(v, x)))
break;
}
}
// java.util.concurrent.atomic.Striped64#getProbe
// 获取线程的hash值
static final int getProbe() {
return (int) THREAD_PROBE.get(Thread.currentThread());
}
// java.util.concurrent.atomic.Striped64#advanceProbe
// 重置线程的hash值
static final int advanceProbe(int probe) {
probe ^= probe << 13; // xorshift
probe ^= probe >>> 17;
probe ^= probe << 5;
THREAD_PROBE.set(Thread.currentThread(), probe);
return probe;
}
总结:
- 一开始没有竞争时只更新
base。 - 如果
base通过CAS更新失败后,首次会新建Cell[]数组。 - 当多个线程竞争同一个
Cell[]比较激烈时,可能就需要对Cellp[]扩容了。
下面看获取值的方法java.util.concurrent.atomic.LongAdder#longValue:
public long longValue() {
// 可以看到调用的是 sum() 方法,注意 toString() 也会调用 sum() 方法来打印结果
return sum();
}
// 把 base 和 cells 里的值合计返回
public long sum() {
Cell[] cs = cells;
long sum = base;
if (cs != null) {
for (Cell c : cs)
if (c != null)
sum += c.value;
}
return sum;
}
可以知道,这个值是非实时非精确的,也就是LongAdder不是强一致性的,而是最终一致性的。
总结
AtomicLong:
- 线程安全,要求高精度时可使用。
- 保证获取结果精度,性能代价。
- 多线程针对单个热点值value进行原子操作。
- 高并发后会性能会有所下降,因为自旋会成为瓶颈,失败不断自旋到成功,大量失败会占用大量CPU。
LongAdder:
- 当在高并发下需要有更好的性能且对精确度要求不高时,可以使用。
- 保证性能,结果精度和空间作为代价。
- 每个线程都拥有自己对应的槽,各个线程一般只对自己槽中的value值进行CAS操作。
每次看JUC相关类的源码,总会被大神的写法所惊艳,能从中学到很多,想要快速提高编程技巧,最快的方式还是多阅读高手的源码。
博客内容遵循 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 协议
本文永久链接是:https://blog.lgq51233.xyz/2023/11/20/JUC%E4%B9%8BLongAdder%E6%BA%90%E7%A0%81%E5%88%86%E6%9E%90/