
服务治理实战
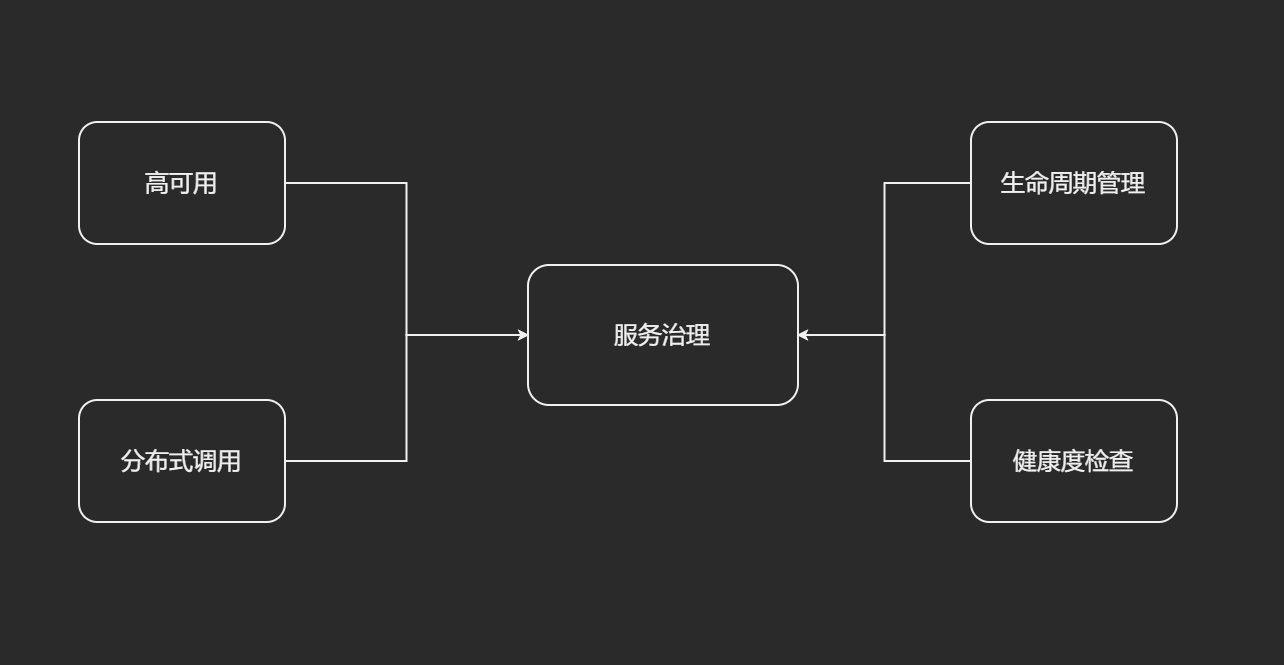
服务治理
服务治理全链路: 服务注册, 服务发现, 心跳和续约, 服务下线, 剔除和自保
服务治理目标
- 高可用性. 在服务治理麾下的所有微服务节点, 不论是被闪电击中还是被挖掘机铲断了电源, 即使战至最后一个存活节点, 服务治理框架也要保证服务的可用性.
- 分布式调用. 微服务的节点通常散落在不同的网络环境中, 大型互联网公司甚至会使用两地三机房或跨洲际机房做异地容灾. 这就要求服务治理框架具备在复杂网络环境下准确获知服务节点网络地址(IP, 端口以及服务名称)的能力. 作为服务消费者, 就可以借助服务治理框架的精准制导能力, 向服务节点发起请求.
- 生命周期管理. 万物都在轮回之中, 在Spring的世界更是如此. 微服务也把自己平凡而充实的一生, 交给了服务治理框架, 从服务上线、持续运行直到临终关怀, 服务治理始终贯穿整个微服务生命周期.
- 健康度检查. 微服务的节点都是任劳任怨的执行996, 当然, 如果一个节点因为任何原因不再能996的辛勤工作, 那就不再是哥的兄弟了. 服务治理框架要精准识别这些节点, 将其从自己的兄弟会中剔除.
四个问题(3W1H)
- Who are you 三个维度.
- IP和端口.
- 服务名称.
- 健康状况, 是可用还是下线状态.
- Where are you from 服务调用方要知道服务提供方来自哪里的.
- How are doing 服务节点的状态.
- When you die 服务节点下线(系统升级重启), 短时间内不会在线, 那么服务治理框架也要做出相应的回应.
服务治理解决方案
- Who are you - 服务注册 - 服务提供方自报家门
- Where are you from - 服务发现 - 服务消费者拉取注册数据
- How are you doing - 心跳检测, 服务续约和服务剔除 一套由服务提供方和注册中心配合完成的去伪存真的过程
- When you die - 服务下线 - 服务提供方发起主动下线
分布式系统CAP定理
- C: 强一致性.
- 强一致性 一次更新, 终身有效
- 弱一致性 更新后, 有部分或者所有请求都拿不到更新后的数据
- 最终一致性 经过一段时间, 在未来的某个时间点后访问的数据都能取到访问的值
- A: 可用性. 宕机时长占全年的总服务时长的比例. 99.999%, 宕机 < 5min
- P: 分区容错性. 异地机房, 容灾, 这些机型会互相同步, 备份. 如果同步渠道被切断了, 就会出现数据不一致的现象. 所以分区容错性的系统, 只能满足C/A中的其中一个.
- 一个分布式系统里面, 节点组成的网络本来应该是连通的. 然而可能因为一些故障, 使得有些节点之间不连通了, 整个网络就分成了几块区域. 数据就散布在了这些不连通的区域中. 这就叫分区.
- 当你一个数据项只在一个节点中保存, 那么分区出现后, 和这个节点不连通的部分就访问不到这个数据了. 这时分区就是无法容忍的.
- 提高分区容忍性的办法就是一个数据项复制到多个节点上, 那么出现分区之后, 这一数据项就可能分布到各个区里. 容忍性就提高了.
然而, 要把数据复制到多个节点, 就会带来一致性的问题, 就是多个节点上面的数据可能是不一致的. 要保证一致, 每次写操作就都要等待全部节点写成功, 而这等待又会带来可用性的问题. 总的来说就是, 数据存在的节点越多, 分区容忍性越高, 但要复制更新的数据就越多, 一致性就越难保证. 为了保证一致性, 更新所有节点数据所需要的时间就越长, 可用性就会降低.
CAP大定理, 分布式系统只能二选一, 不能全选.
服务治理三大门派
- Eureka
- Consul
- Nacos
服务治理组件对比
| Eureka | Consul | Nacos | |
|---|---|---|---|
| 一致性 | 弱一致性(AP) | 弱一致性(AP) | AP/CP |
| 性能 | 快 | 慢(RAFT协议 Leader选举 半数成功) | 快 |
| 网络协议 | HTTP | HTTP&DNS | HTTP,DNS,UDP |
| 应用广度 | 目前主流 | 目前非主流 | 稳中有升, 有待观察 |
架构选型
- 对当前业务的支持, 做POC
- 未来研发支持(社区, 商业公司)
- 团队的技术栈&学习成本
- 替换成本&运维成本
注册中心
服务注册是为了解决Who are you这个问题, 即获取所有服务节点的身份信息和服务名称, 从注册中心的角度来说我们有以下两种比较直观的解决方案:
- 由注册中心主动访问网络节点中所有机器
- 注册中心坐等服务节点上门注册
第一种方案弊端
- 模型复杂:网络环境浩如烟海, 轮询每个节点的做法通常是注册中心发局域网广播, 客户端响应的方式, 这种方式就像你对着全世界喊我爱你, 顿时感到有种无力感. 现实中对于跨局域网的分布式系统来说, 响应模型更加复杂.
- 网络消耗大: 整个网络环境里会掺杂大量非服务节点, 这些节点无需对送达的广播请求做出响应, 这种广播的模式无疑增加了网络通信成本.
- 服务端压力增加: 不仅要求注册中心向网络中所有节点主动发送广播请求, 还需要对客户端的应答做出响应, 一个担子两头挑. 考虑到注册中心的节点数远远少于服务节点, 我们要尽可能地减轻服务中心承载的业务.
第二种方案
- 省心 对于网络中其它非服务节点来说不会产生任何无效请求
- 省时 省去了广播环节的时间, 使注册效率大大提高
- 省力 节省了大量网络请求的开销
SpringCloud对注册中心可谓是优待有加, 只接受服务节点上门服务, 绝不主动出门联系. 这便是SpringCloud大道至简的智慧所在, 任何复杂的问题到了这里, 都会通过最简单、最经济的方式来解决.
注册中心的日常任务
- 他会的技能(所提供的微服务是什么, 比如“洗剪吹”)
- 他住在哪里(IP地址+端口)
- 他的状态(通常注册完成时的服务状态就是UP)在等待戈多的过程中, 其实这两位流浪汉也没有那么闲, 他在空余时间还是干了两件微小的事:
- 心跳检测和服务剔除 已经注册过的戈多们, 会时不时来跟我打声招呼(心跳检测), 如果隔段时间没见着他们了, 我就只好从注册名单中把他们删除(服务剔除).
- 注册信息同步 我们两个流浪汉分别接待不同的戈多, 有的戈多在我这里注册, 没有在他那里注册. 我抽空就会把我这里的戈多名单和他做分享.
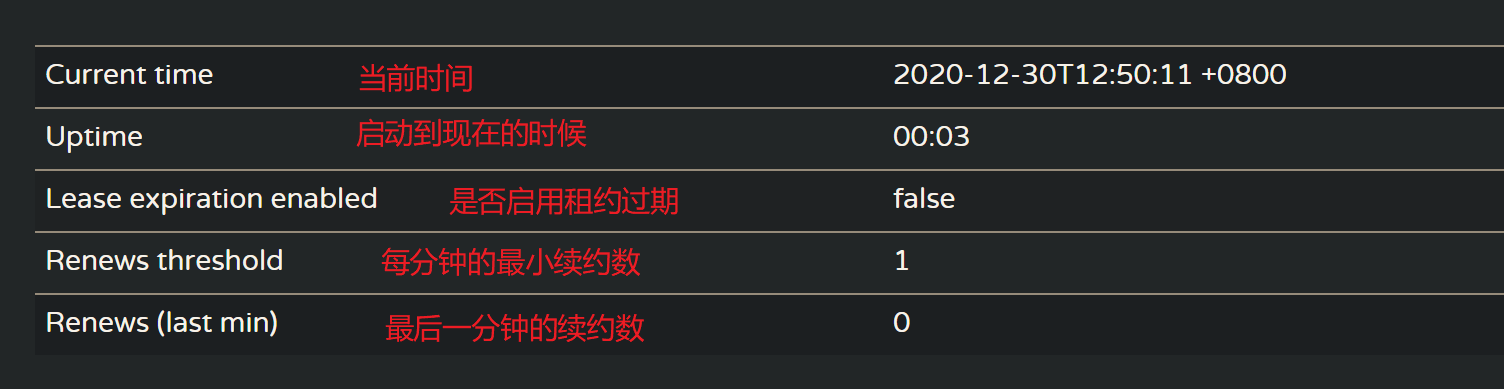
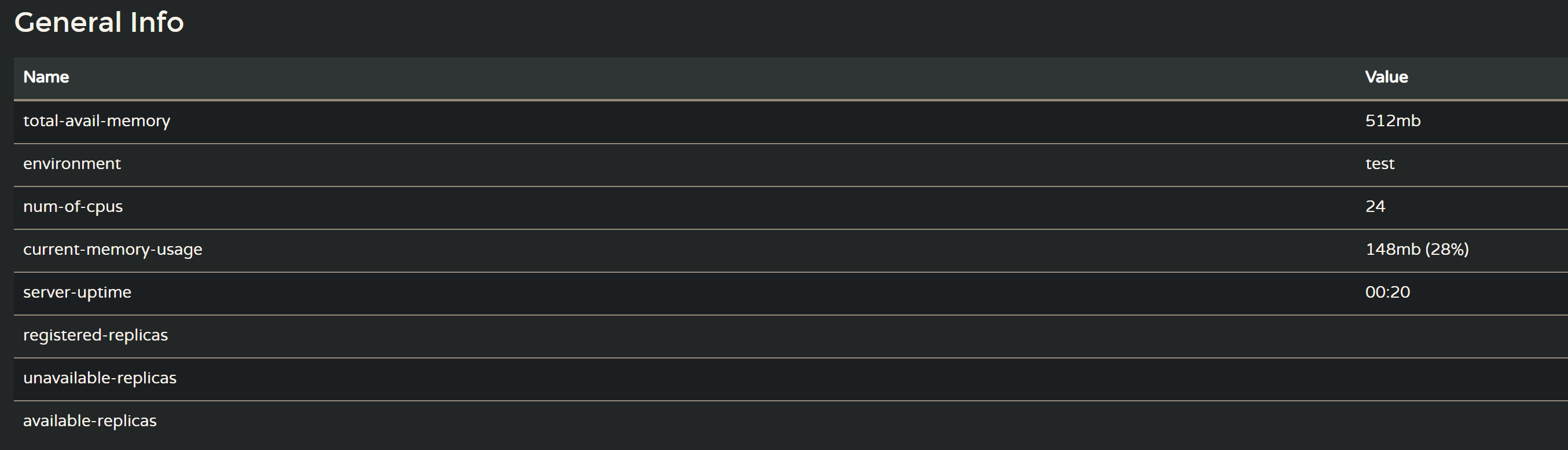
注册中心UI解读
自我保护机制开启

网络分区:就是某些机器与注册中心的通路被切断了.
注册中心副本和当前注册应用

注册中心的系统信息
服务注册
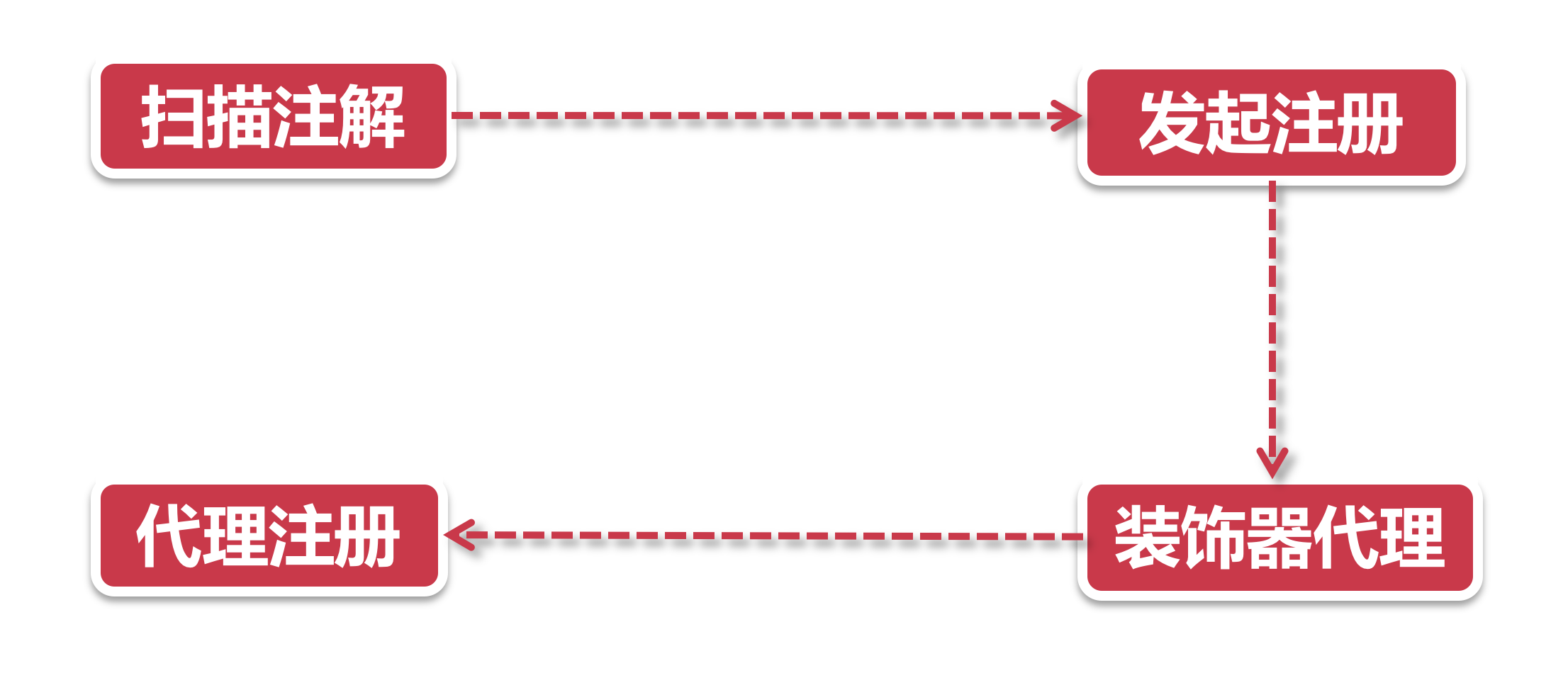
- 扫描注解
@EnableDiscoveryClient - 发起注册 DiscoveryClient类的register方法, 可以把这个类当做一个类似Facade(外观)模式的门面类, 他是服务节点很多操作的入口. 在这一步中DiscoveryClient运起了设计模式中的代理+装饰器模式, 现在执行到了SessionedEurekaHttpClient装饰器.
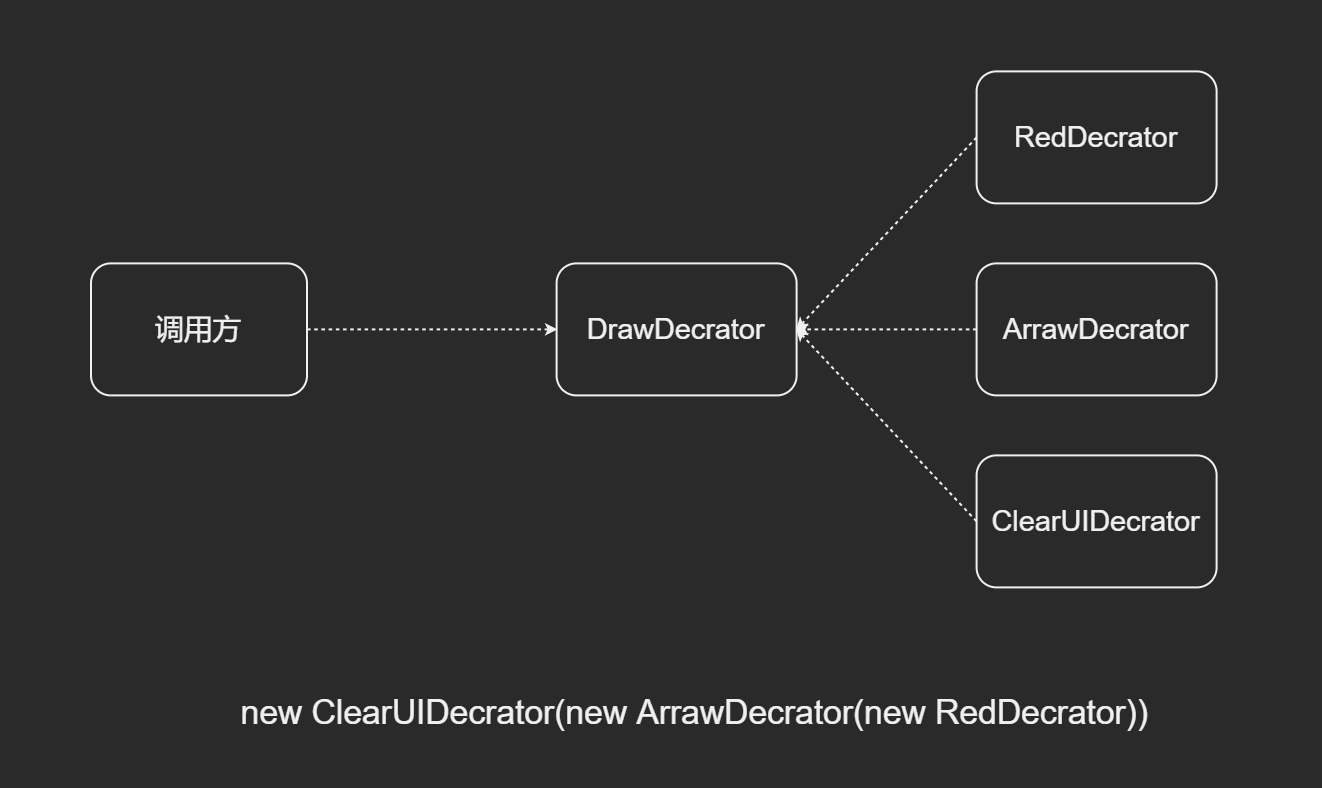
- 装饰器+代理 话说SessionedEurekaHttpClient还有个师父(父类), 江湖人称EurekaHttpClientDecorator, Eureka的一众连接器全部师从(继承)自这个类. 从名字中的Decorator就可以看出它用了装饰器设计模式, 简单的说, 装饰器就像一层套一层的俄罗斯娃娃, 每一层都会给本体加上一层Buff(假定大家都玩过王者荣耀, 知道Buff是什么意思), 所以你也尽可称呼它为装B模式. JDK里使用装B模式的还有大名鼎鼎的输入输出流框架(InputStream和OutputStream).
- 代理注册 Eureka的注册流程其实是用代理+回调的方式, 实现了类似装饰器的效果, 也就是说虽然这个祖师爷EurekaHttpClientDecorator名字里带了个Decorator, 但并不是完全体的装B模式, 他没有上一步提到的JDK Stream框架装B的彻底. 接下来, 就要看Eureka大显神通, 运用一层层代理, 给注册器加上各种装饰器的Buff.
为什么要设计成这样?
这要说到业务系统和开源项目孵化的不同了.
所谓业务系统, 在保证可扩展性的基本要求下, 尽可能支持公司业务的快速增长, 往往不会特别在意系统架构层面的清晰度和组件化. 这点在互联网公司表现的更加直接, 大型互联网公司业务增长迅速, 制约业务发展的往往是IT系统跟不上业务的奔跑速度. 首要任务是满足业务发展, 留给系统设计架构思考的时间, 少之又少. 这就是为什么大公司也会有质量很低的代码的原因, 缺少code review和架构设计的时间.
在互联网公司做业务团队, 老板只会关注你是不是能及时满足业务发展的要求, 何曾见到业务团队把架构设计当做一项KPI?正所谓大家只关心你飞的高不高, 而不关心你飞的累不累.
而对于开源项目孵化来说, 站在Spring组织的角度, 对接口规范的履约程度和组件化的划分是有明确要求的. 打一个比方, 不管你是使用Spring Portlet规范做一套项目, 还是使用SpringMVC做项目, 你会发现这些组件都严格执行了一套Spring封装的Servlet接口规范, 在做技术栈变更的时候只用替换具体模块组件就好, 对自身业务代码的影响会很小. 也就是说, Spring治理下所有开源项目都是一种可插拔的组件模式, 当你从一个组件切换到另一个组件的时候, 由于遵循同一套接口规范, 这种迁移变得十分容易. 这也就是为什么一个进入Apache或Spring的开源项目, 要经过官方指导的漫长的孵化器, 一方面是为了稳定功能和版本, 另一方面也是为了做好组件化的划分.
代理模式
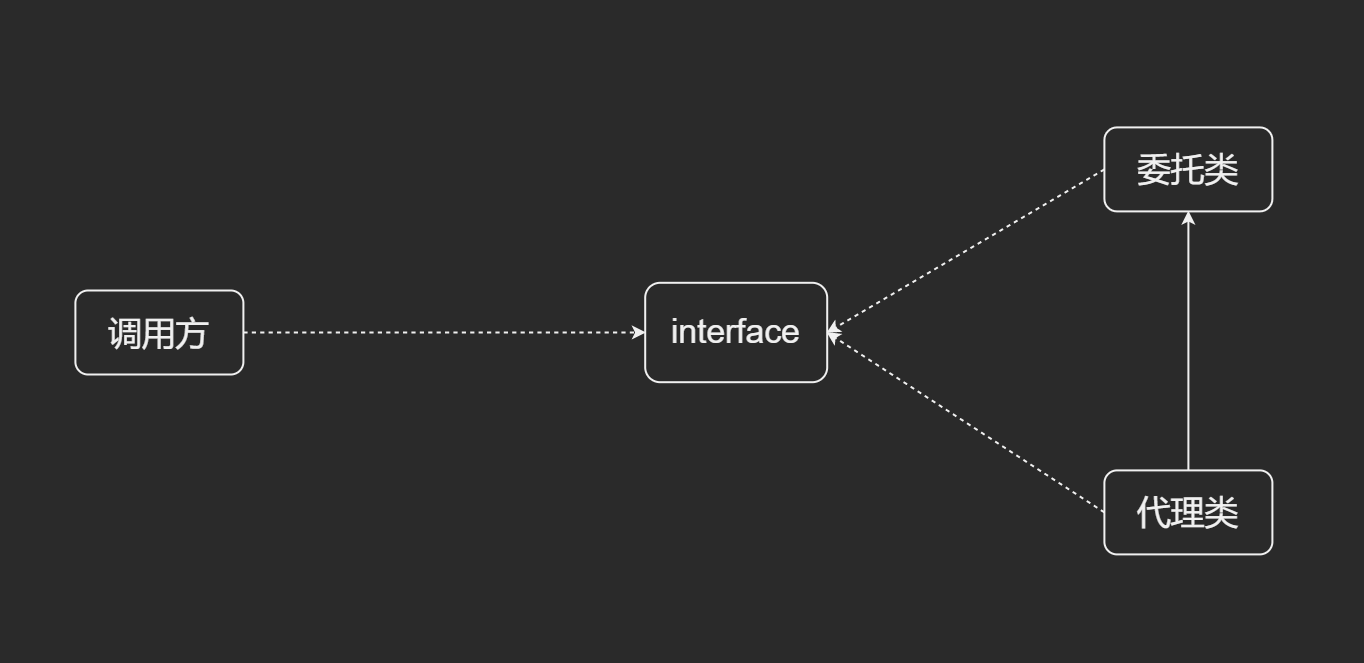
装饰器模式
服务注册源码分析
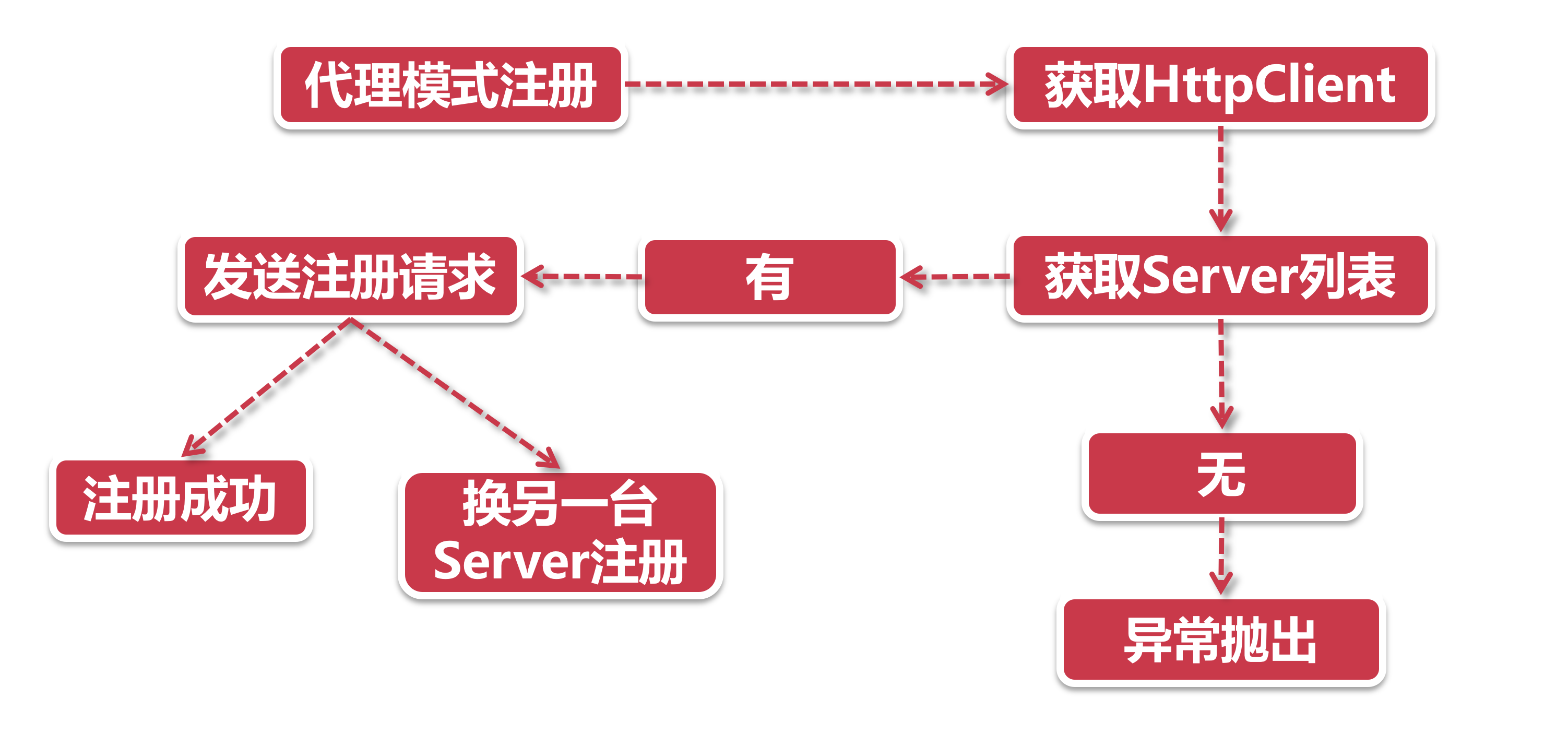
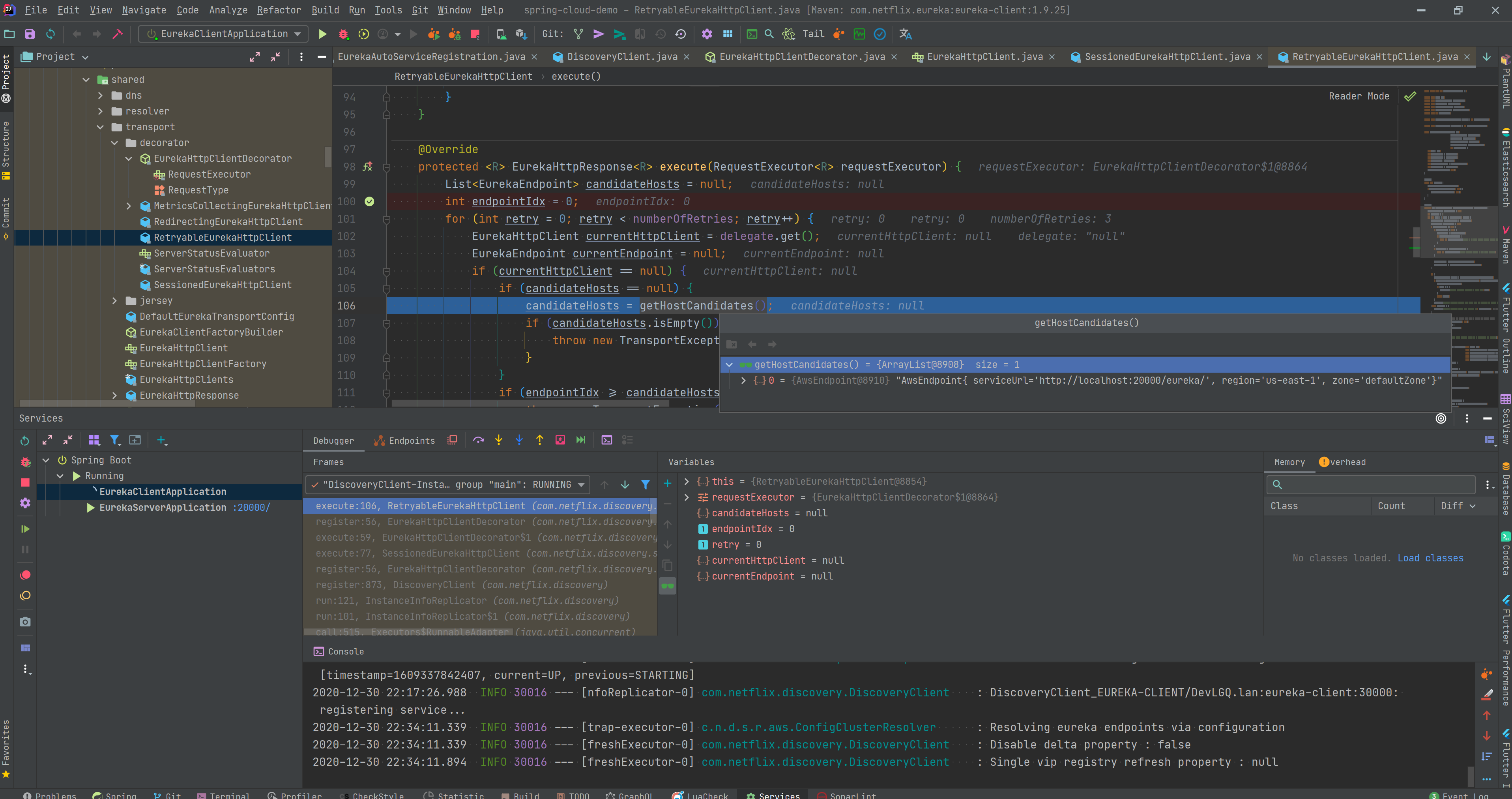
- 代理模式注册 前面说到了装饰器模式就像层层嵌套的洋娃娃, 我们抽丝剥茧之后发现, 总共有4层洋娃娃, 每一层装饰器都有特殊的功能, 正所谓我走过的最长的路是Eureka的套路. 这里我们选一层最重要的娃娃来展开, 那就是RetryableEurekaHttpClient(注意, 这不是最里层的那个). 从名字Retryable我们不难看出, 它自带了“失败重试”的功能, 这就是它的特殊的Buff-原地复活.
- 获取HttpClient 这里的HttpClient是RetryableEurekaHttpClient里面的代理对象, 也是下一层的洋娃娃, 它里面封装了上次同步成功的注册中心地址等信息. 假如代理对象为空, 那我们就不知道该连向哪个注册中心了, 这时候我们就要从Server列表中找一台服务器.
- 获取Server列表 在之前的章节我们提到过, 客户端的Server列表是开发人员通过上帝视角直接配置的, 那么第一步就是获取这些已经配置好的Server列表信息.
- 发送注册请求 最里层的装饰器发起了真正的杀招, 调用了JerseyApplicationCLient的register方法向注册中心发起最后一击. 注册信息中的三大金刚:服务名称, 服务节点IP, 节点状态.
- 如果注册失败, 换一个注册节点再来Retry, 在上一台的基础上自增一, 重新走一次注册流程获取. 超过上限之后, 等下次定时Task来注册了.
RetryableEurekaHttpClient.java
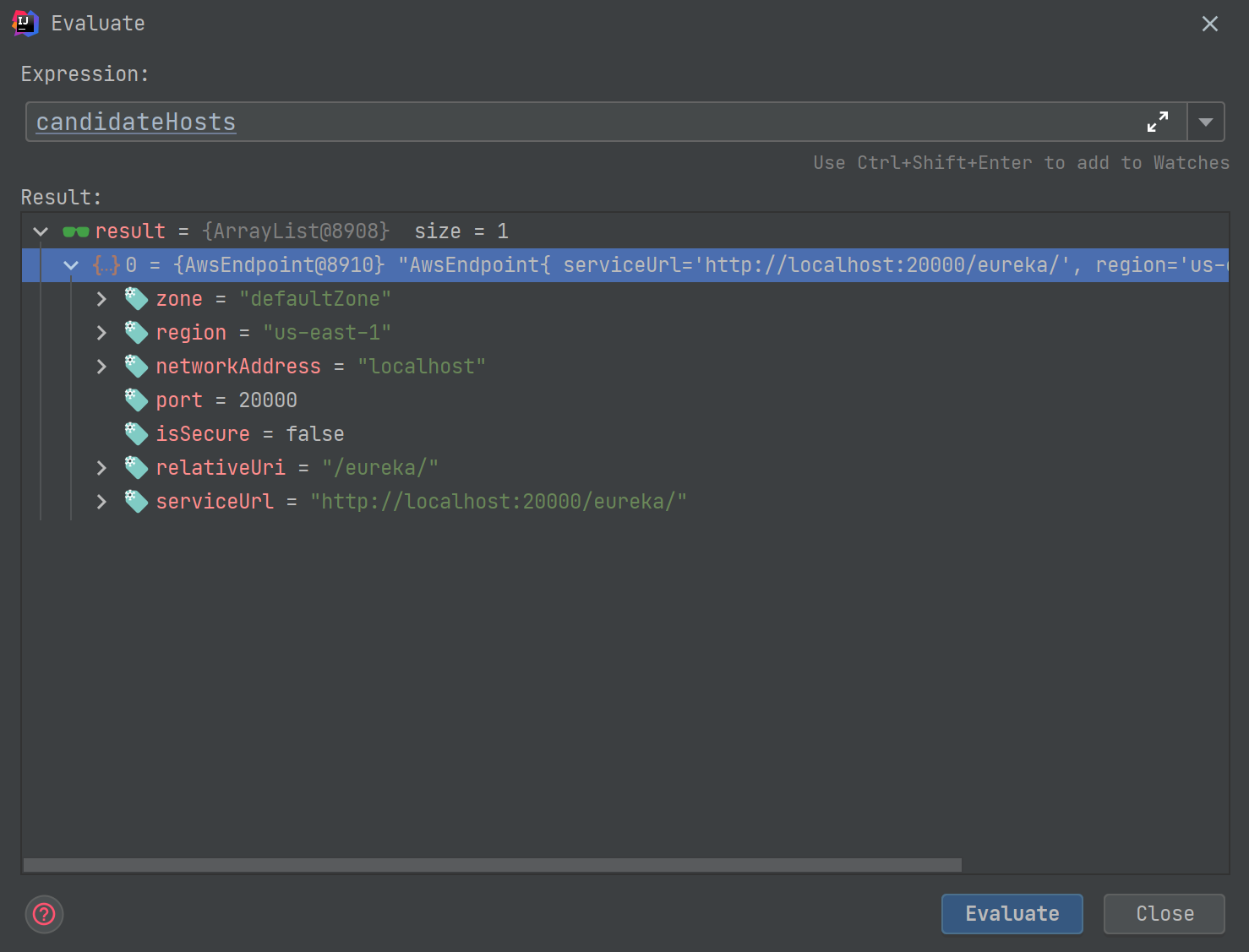
JerseyApplicationClient.java
服务发现
基于客户端的服务发现
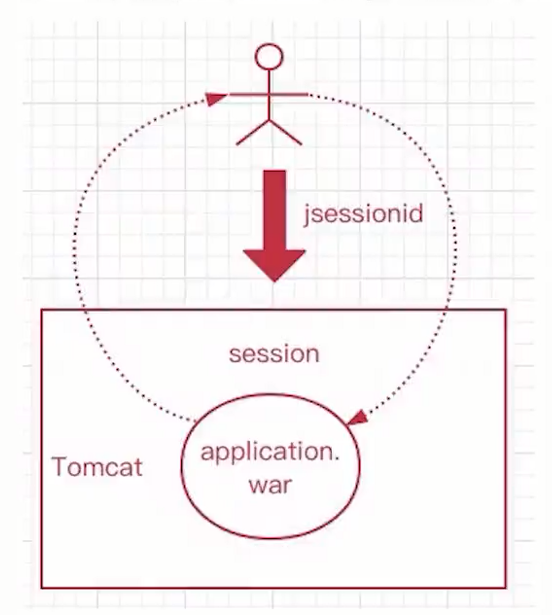
网络服务节点通过服务注册, 将自己的信息以及IP地址发送给注册中心, 而调用方则从注册中心获取所有可用的服务列表, 通过负载均衡获取到一个可用的节点, 自己直接去访问获取数据.
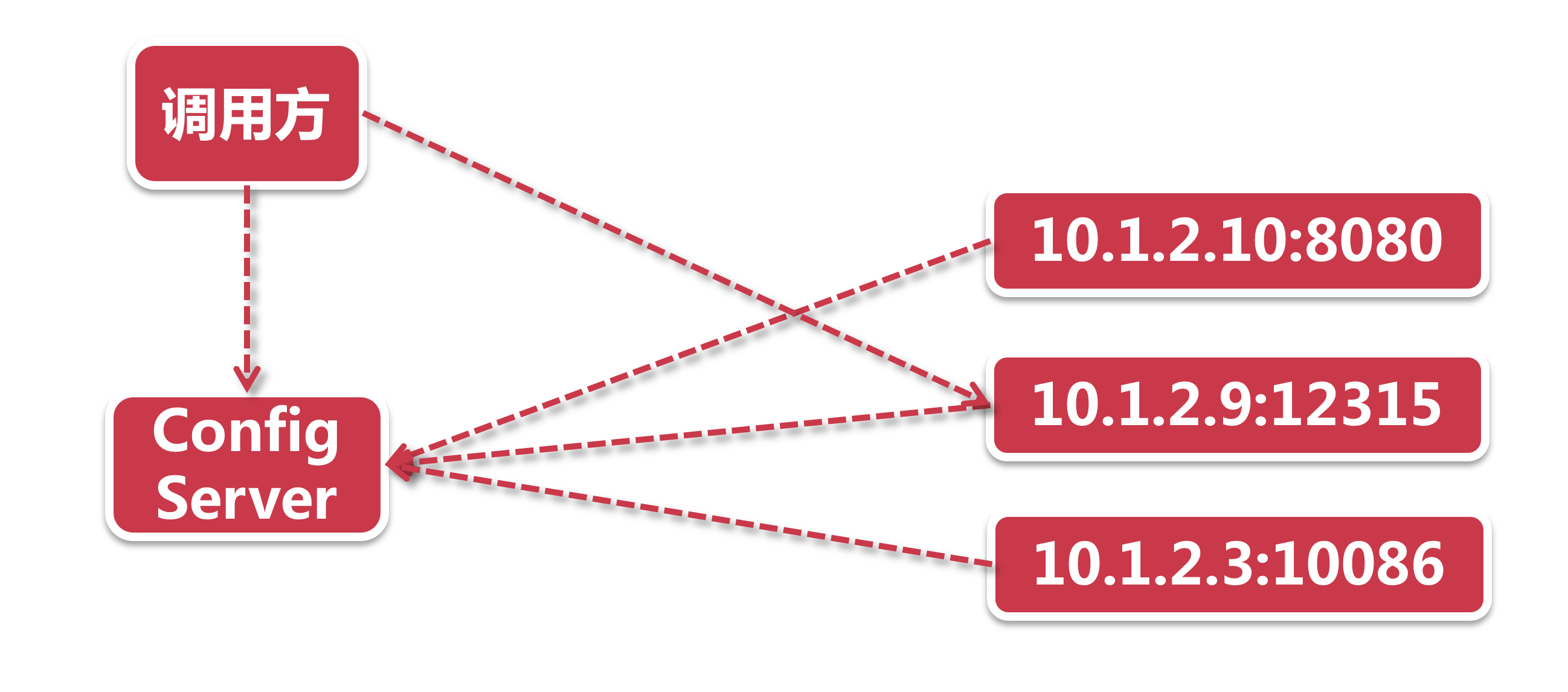
基于服务端的服务发现
在这种模式下, 多了一个Router的概念. 注册中心依然有所有的服务节点信息. 这个Router既可以是服务端负载均衡器, 也可以是网关层, 而负载均衡策略则从发起调用的消费者一端, 移到了服务端.
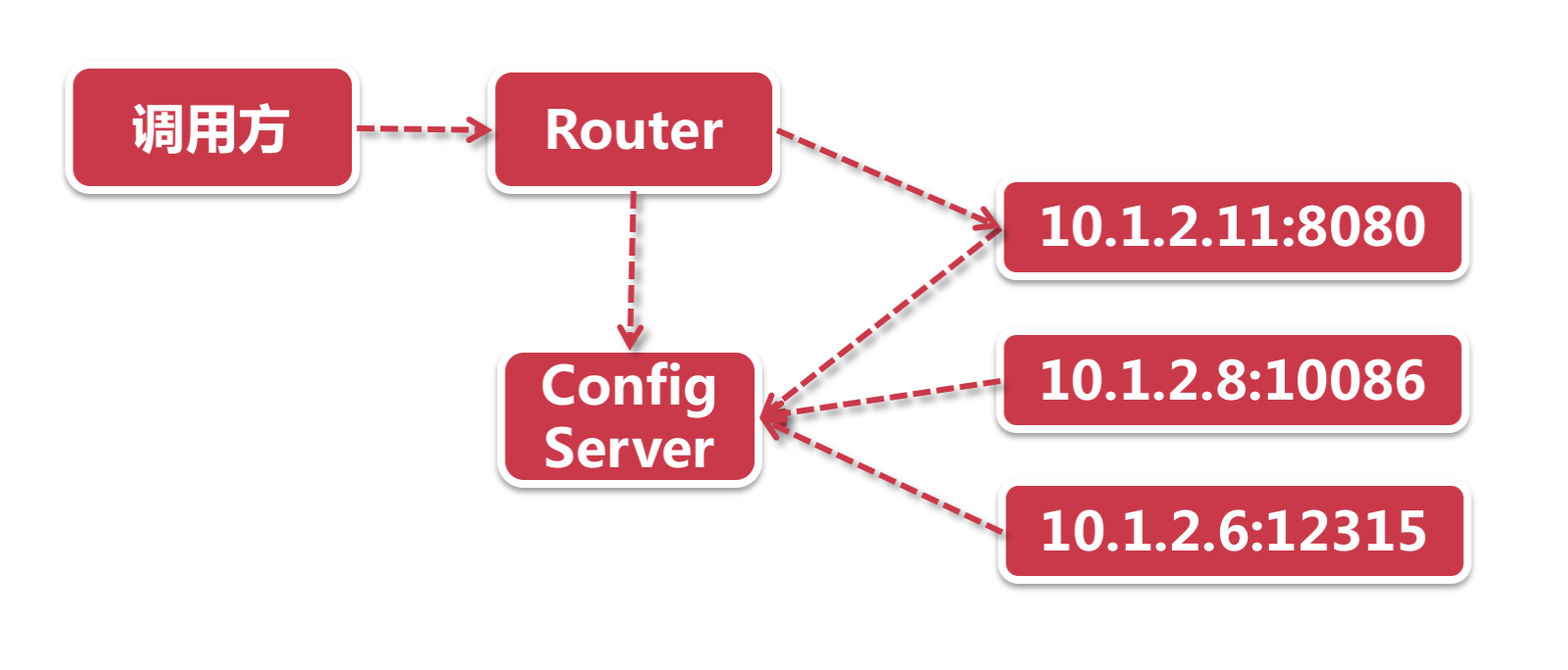
对比
| 客户端模式 | 服务端模式 | |
|---|---|---|
| 性能 | 快. 网络转发量少, 客户端直接参与负载均衡. | 慢. 网络转发请求大, 服务端承载负载均衡. |
| 负载均衡策略 | 调用方负责. | 服务器端负责. |
| 运维成本 | 低. 没有额外网络组件, 交互模型简单. | 高. 借助额外组件实现Router+负载均衡. |
| 应用 | Eureka定时拉取. Dubbo订阅模式. | k8s代理, AWS ELB, Consul Template + Nginx |
客户端模式似乎是更加轻量且效率的做法, 但是对于客户端来说, 就要承载额外的负载均衡处理. 但是显而易见的是, 负载均衡无论是在客户端或者服务端, 总归得是有的(大型互联网应用通常是客户端+网关层都会部署负载均衡), 所以如果采用客户端负载均衡模式的话, 对SpringCloud来说则是省了一个部署组件, 这又说明了SpringCloud一切从简的原则.
心跳和服务续约源码分析
- 客户端发起 我们前面说过Eureka的注册中心是一个运筹帷幄的角色, 足不出户办天下事, 所以心跳服务是由一个个服务节点根据配置的时间主动发起的.
- 同步状态 我们说的“心跳”不光要告诉注册中心“我还活着”, 还要告诉他我活的好不好, 是现在快不行了(OUT服务状态 心跳能反映出一个人的身体状况, 对服务节点也一样, 一个节点的服务状态有以下几种
UP, DOWN, STARTING, OUT_OF_SERVICE, UNKNOWN
_OF_SERVICE状态)还是生龙活虎(UP状态). - 服务剔除 现在轮到注册中心做点事情了, 对一段时间无响应的服务, 反映到心电图上就是一根直线跌停板, 那便要主动从注册列表中剔除, 以防服务调用方请求失败.
- 服务续约 也许大家还不知道, 服务续约底层也是靠着心跳来实现的, 但包含了一套“��数据”处理流程.
心跳信息
访问地址 也就是Eureka注册中心的地址, 如http://localhost:20000/eureka/
访问路径 为了防止注册中心把我的心电图当做了别人的, 给人治错了病, 我还要主动告诉注册中心我是谁. 不同于服务注册流程中把个人信息放到POST请求的body, 心跳包把这个信息放到了访问的URL中, 例如
apps/${app_name}/${instance_id}, 这里的appname是服务注册时提供的服务名, 而instance_id则是当前这个服务节点的唯一编号, 比如9527.
服务状态 心跳能反映出一个人的身体状况, 对服务节点也一样, 一个节点的服务状态有以下几种UP, DOWN, STARTING, OUT_OF_SERVICE, UNKNOWN.
最后一次同步注册的时间 lastDirtyTimeStamp, 这是心跳检测环节最复杂的一个知识点, 它是当前服务节点最后一次与服务中心失去同步时的时间, InstanceInfo封装了该属性以及另一个搭档isInstanceInfoDirty, 当isInstanceInfoDirty=true的时候, 表示当前节点自从lastDirtyTimeStamp以后的时间都处于未同步的状态.
核心指标
eureka.instance.lease-renewal-interval-in-seconds=10
eureka.instance.lease-expiration-duration-in-seconds=20
- 第一个指标决定了每隔多久向服务器发送一次心跳包
- 第二个参数告诉服务器, 如果我在x秒内都没有心跳, 那就代表我挂掉了
客户端发送心跳信息 DiscoveryClient
boolean renew() {
EurekaHttpResponse<InstanceInfo> httpResponse;
try {
httpResponse = eurekaTransport.registrationClient.sendHeartBeat(instanceInfo.getAppName(), instanceInfo.getId(), instanceInfo, null);
logger.debug(PREFIX + "{} - Heartbeat status: {}", appPathIdentifier, httpResponse.getStatusCode());
if (httpResponse.getStatusCode() == Status.NOT_FOUND.getStatusCode()) {
REREGISTER_COUNTER.increment();
logger.info(PREFIX + "{} - Re-registering apps/{}", appPathIdentifier, instanceInfo.getAppName());
long timestamp = instanceInfo.setIsDirtyWithTime();
boolean success = register();
if (success) {
instanceInfo.unsetIsDirty(timestamp);
}
return success;
}
return httpResponse.getStatusCode() == Status.OK.getStatusCode();
} catch (Throwable e) {
logger.error(PREFIX + "{} - was unable to send heartbeat!", appPathIdentifier, e);
return false;
}
}
服务端接收 InstanceResource
@PUT
public Response renewLease(
@HeaderParam(PeerEurekaNode.HEADER_REPLICATION) String isReplication,
@QueryParam("overriddenstatus") String overriddenStatus,
@QueryParam("status") String status,
@QueryParam("lastDirtyTimestamp") String lastDirtyTimestamp) {
// 心跳请求来自哪一方, 服务提供者还是其他注册中心同步过来的
boolean isFromReplicaNode = "true".equals(isReplication);
// registry -> InstanceRegistry
boolean isSuccess = registry.renew(app.getName(), id, isFromReplicaNode);
// Not found in the registry, immediately ask for a register
if (!isSuccess) {
logger.warn("Not Found (Renew): {} - {}", app.getName(), id);
return Response.status(Status.NOT_FOUND).build();
}
// Check if we need to sync based on dirty time stamp, the client
// instance might have changed some value
Response response;
// 上一次和服务器出现的脏数据时间戳
// 脏数据 -- 服务不同步
// 就是最近发生数据不同步的时间戳
// 并且 SyncWhenTimestampDiffers 这个属性是否需要同步
if (lastDirtyTimestamp != null && serverConfig.shouldSyncWhenTimestampDiffers()) {
// 验证脏数据时间戳
response = this.validateDirtyTimestamp(Long.valueOf(lastDirtyTimestamp), isFromReplicaNode);
// Store the overridden status since the validation found out the node that replicates wins
if (response.getStatus() == Response.Status.NOT_FOUND.getStatusCode()
&& (overriddenStatus != null)
&& !(InstanceStatus.UNKNOWN.name().equals(overriddenStatus))
&& isFromReplicaNode) {
registry.storeOverriddenStatusIfRequired(app.getAppName(), id, InstanceStatus.valueOf(overriddenStatus));
}
} else {
response = Response.ok().build();
}
logger.debug("Found (Renew): {} - {}; reply status={}", app.getName(), id, response.getStatus());
return response;
}
验证脏数据时间戳
private Response validateDirtyTimestamp(Long lastDirtyTimestamp,
boolean isReplication) {
InstanceInfo appInfo = registry.getInstanceByAppAndId(app.getName(), id, false);
if (appInfo != null) {
// 传入的 lastDirtyTimestamp 和当前服务端保存的 lastDirtyTimestamp 不一致
// 说明产生了时间不同步的情况
if ((lastDirtyTimestamp != null) && (!lastDirtyTimestamp.equals(appInfo.getLastDirtyTimestamp()))) {
Object[] args = {id, appInfo.getLastDirtyTimestamp(), lastDirtyTimestamp, isReplication};
// 客户端发来的脏数据时间比服务器的脏数据时间新
if (lastDirtyTimestamp > appInfo.getLastDirtyTimestamp()) {
logger.debug(
"Time to sync, since the last dirty timestamp differs -"
+ " ReplicationInstance id : {},Registry : {} Incoming: {} Replication: {}",
args);
return Response.status(Status.NOT_FOUND).build();
} else if (appInfo.getLastDirtyTimestamp() > lastDirtyTimestamp) {
// 服务器的脏数据时间比客户端发来的脏数据时间新
// In the case of replication, send the current instance info in the registry for the
// replicating node to sync itself with this one.
if (isReplication) {
logger.debug(
"Time to sync, since the last dirty timestamp differs -"
+ " ReplicationInstance id : {},Registry : {} Incoming: {} Replication: {}",
args);
return Response.status(Status.CONFLICT).entity(appInfo).build();
} else {
return Response.ok().build();
}
}
}
}
return Response.ok().build();
}
InstanceRegistry.java
@Override
public boolean renew(final String appName, final String serverId,
boolean isReplication) {
log("renew " + appName + " serverId " + serverId + ", isReplication {}"
+ isReplication);
List<Application> applications = getSortedApplications();
for (Application input : applications) {
if (input.getName().equals(appName)) {
InstanceInfo instance = null;
for (InstanceInfo info : input.getInstances()) {
if (info.getId().equals(serverId)) {
instance = info;
break;
}
}
publishEvent(new EurekaInstanceRenewedEvent(this, appName, serverId,
instance, isReplication));
break;
}
}
// 调用父类 PeerAwareInstanceRegistryImpl.java 的 renew
return super.renew(appName, serverId, isReplication);
}
PeerAwareInstanceRegistryImpl.java
public boolean renew(final String appName, final String id, final boolean isReplication) {
// AbstractInstanceRegistry.java
if (super.renew(appName, id, isReplication)) {
// 高可以用, 多个节点进行同步
replicateToPeers(Action.Heartbeat, appName, id, null, null, isReplication);
return true;
}
return false;
}
AbstractInstanceRegistry.java
/**
* Marks the given instance of the given app name as renewed, and also marks whether it originated from
* replication.
*
* @see com.netflix.eureka.lease.LeaseManager#renew(java.lang.String, java.lang.String, boolean)
*/
public boolean renew(String appName, String id, boolean isReplication) {
RENEW.increment(isReplication);
Map<String, Lease<InstanceInfo>> gMap = registry.get(appName);
Lease<InstanceInfo> leaseToRenew = null;
if (gMap != null) {
// 根据 id 获取租约
leaseToRenew = gMap.get(id);
}
if (leaseToRenew == null) {
RENEW_NOT_FOUND.increment(isReplication);
logger.warn("DS: Registry: lease doesn't exist, registering resource: {} - {}", appName, id);
return false;
} else {
InstanceInfo instanceInfo = leaseToRenew.getHolder();
if (instanceInfo != null) {
// touchASGCache(instanceInfo.getASGName());
// 是否要重载instance
InstanceStatus overriddenInstanceStatus = this.getOverriddenInstanceStatus(
instanceInfo, leaseToRenew, isReplication);
if (overriddenInstanceStatus == InstanceStatus.UNKNOWN) {
logger.info("Instance status UNKNOWN possibly due to deleted override for instance {}"
+ "; re-register required", instanceInfo.getId());
RENEW_NOT_FOUND.increment(isReplication);
return false;
}
if (!instanceInfo.getStatus().equals(overriddenInstanceStatus)) {
logger.info(
"The instance status {} is different from overridden instance status {} for instance {}. "
+ "Hence setting the status to overridden status", instanceInfo.getStatus().name(),
instanceInfo.getOverriddenStatus().name(),
instanceInfo.getId());
instanceInfo.setStatusWithoutDirty(overriddenInstanceStatus);
}
}
// 过去一分钟服务续约
renewsLastMin.increment();
// Lease.java 只是更新了 lastUpdateTimestamp
leaseToRenew.renew();
return true;
}
}
Lease.java
public void renew() {
lastUpdateTimestamp = System.currentTimeMillis() + duration;
}
服务剔除
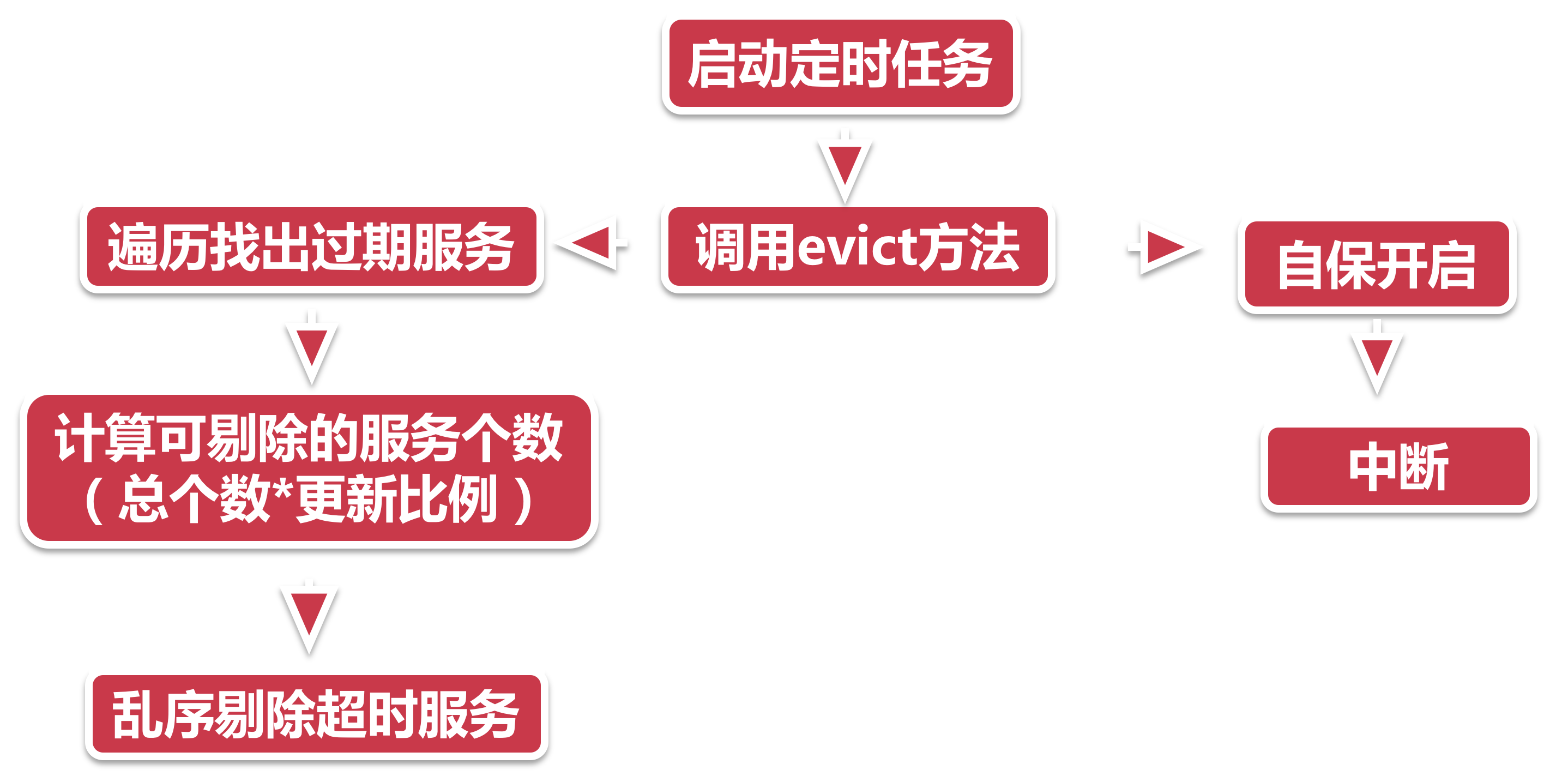
- 启动定时任务 注册中心在启动的时候也会同步开启一个后台任务, 默认每间隔60秒触发服务剔除任务, 当然我们也可以通过在服务端
eureka.server.eviction-interval-timer-in-ms=30000做如下参数配置修改触发间隔, 这里将间隔设置成了30秒. 此处建议不要设置的时间过短. - 调用evict 不像服务注册的山路十八弯, 服务剔除比较直接了当, 通过AbstractInstanceRegistry的eviction方法直接运行. 自保开启 服务自保是注册中心的保命招, 后面课程会详细介绍, 这里大家只要知道一旦自保开启, 则注册中心就会中断服务剔除操作.
- 遍历过期服务 接下来注册中心会遍历所有服务节点, 揪出所有过期服务. 如何判断一个服务是过期服务呢, 只要满足以下两点中任意一点就可以当做过期已被标记为过期(evictionTimestamp > 0).
- 最后一次心跳时间 + 服务端配置的心跳间隔时间 < 当前时间.
- 计算可剔除的服务总个数 所有服务是否能被全部剔除呢?当然不是, 服务中心也要顾及自身的稳定性, 因此他设置了一个系数(默认0.85), 可剔除的服务数量, 不能大于已注册服务的总数量乘以这个系数. 比如当前有100个服务, 其中99个已经断了气, 那么注册中心实际上只能剔除100*0.85 = 85个服务节点, 而不是99个.
- 乱序剔除服务
服务续约

- 将服务节点的状态同步到注册中心, 意思就是通知注册中心我还可以继续工作, 这一步续约借助客户端的心跳功能来主动发送.
- 当心跳包到达注册中心的时候, 那就要看注册中心有没有心动的感觉了, 他有一套判别机制, 来判定当前的续约心跳是否合理. 并根据判断结果修改当前instance在注册中心记录的同步时间.
服务剔除并不会和心跳以及续约直接打交道, 而是通过查验服务节点在注册中心记录的同步时间, 来决定是否剔除这个节点.
所以说心跳, 续约和剔除是一套相互拮抗, 共同作用的一套机制.
发送Renew请求
服务节点向注册中心发送续约请求的时候.
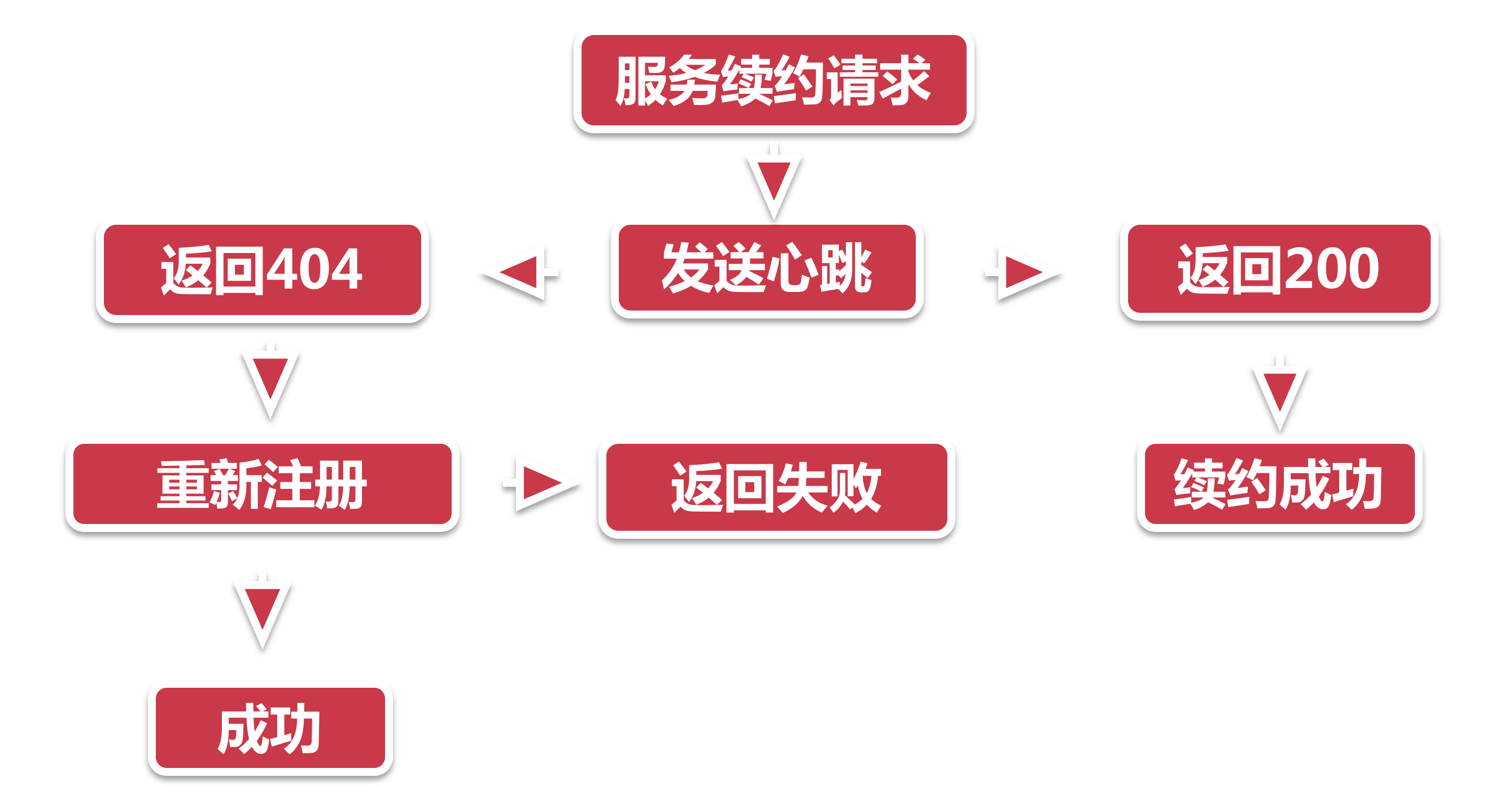
- 服务续约请求 客户端有的
DiscoverClient类, 是所有操作的门面入口. 所有的续约服务都是从这个类 renew 方法开始的. - 发送心跳 服务续约借助心跳来实现, 因此注册中心的参数和心跳部分写到的一样. 两个重要参数分别是服务的状态(UP)和 lastDirtyTimeStamp 如果续约成功, 注册中心则会返回200的HTTP code.
- 如果续约不成功, 注册中心返回404, 这里的404并不是说没有找到注册中心的地址, 而是注册中心认为当前服务节点并不存在. 这个时候再怎么续约也不灵验了, 客户端需要触发一次重新注册操作.
- 在重新注册之前, 客户端会做下面两个小操作, 然后再主动调用服务册流程. 设置 lastDirtyTimeStamp 由于重新注册意味着服务节点和注册中心的信息不同步, 因此需要将当前系统时间更新到”lastDirtyTimeStamp”.
- 标记自己为脏节点.
- 当注册成功的时候, 清除脏节点标记, 但是lastDirtyTimeStamp不会清除, 因为这个属性将会在后面的服务续约中作为参数发给注册中心, 以便服务中心判断节点的同步状态.
注册中心续约校验
考验注册中心灵验不灵验的时候到了, 注册中心开放了一系列的HTTP接口, 来接受四面八方的各种请求, 他们都放在com.netflix.eureka.resources这个包下. 只要客户端路径找对了, 注册中心什么都能帮你办到.
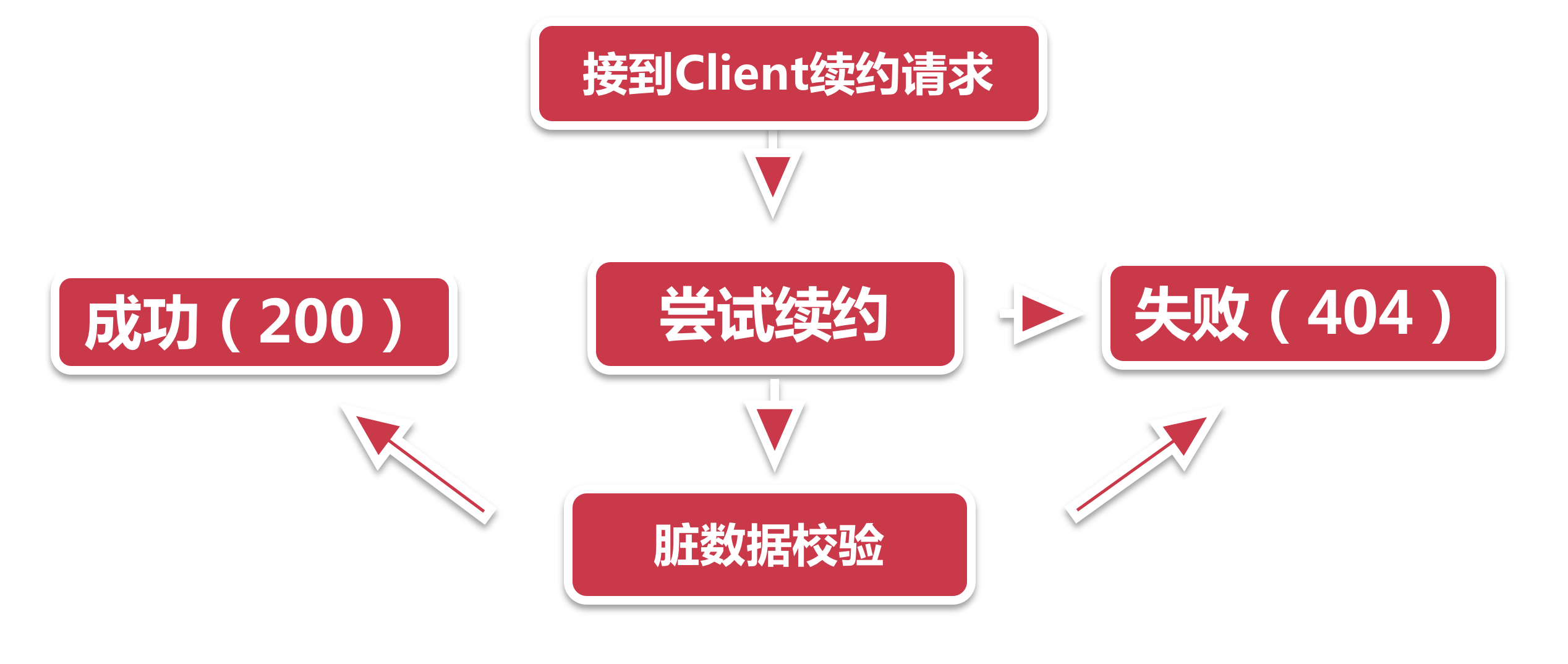
- 接受请求 InstanceResource下的renewLease方法接到了服务节点的续约请求.
- 尝试续约 服务节点说:“万能的注册中心, 请赐予我永生”. 注册中心:“想得美, 从现在算到下一次心跳间隔时间, 如果你没来renew, 就当你死了”. 注册中心此时会做几样简单的例行检查, 如果没有通过, 则通通返回404, 不接受申辩. 小样你以前来注册过吗?没有?续约失败!带齐资料工作日前来办理注册!
- 小样你是Unknown状态?回去回去, 重新注册!
- 脏数据校验 如果续约校验没问题, 接下来就要进行脏数据检查. 到了服务续约最难的地方了, 脏数据校验逻辑之复杂, 如同这皇冠上的明珠. 往细了说, 就是当客户端发来的lastDirtyTimeStamp, 晚于注册中心保存的lastDirtyTimeStamp时(每个节点在中心都有一个脏数据时间), 说明在从服务节点上次注册到这次续约之间, 发生了注册中心不知道的事儿(数据不同步). 这可不行, 这搞得我注册中心的工作不好有序开展, 回去重新注册吧. 续约不通过, 返回404.
服务自保
服务剔除, 服务自保, 这两套功法一邪一正, 俨然就是失传多年的上乘心法的上卷和下卷. 但是往往你施展了服务剔除便无法施展服务自保, 而施展了服务自保, 便无法施展服务剔除. 也就是说, 注册中心在同一时刻, 只能施展一种心法, 不可两种同时施展.
服务剔除 把服务节点果断剔除, 即使你的续约请求晚了一步也毫不留情.
服务自保 把当前所有节点保留, 一个都不能少, 绝不放弃任何队友. 心法的指导思想是, 即便主动删除, 也许并不能解决问题, 且放之任之, 以不变应万变.
在实际应用里, 并不是所有无心跳的服务都不可用, 也许因为短暂的网络抖动等原因, 导致服务节点与注册中心之间续约不上, 但服务节点之间的调用还是属于可用状态, 这时如果强行剔除服务节点, 可能会造成大范围的业务停滞.
服务自保的触发机关
服务自保由两个开关进行控制
自动开关
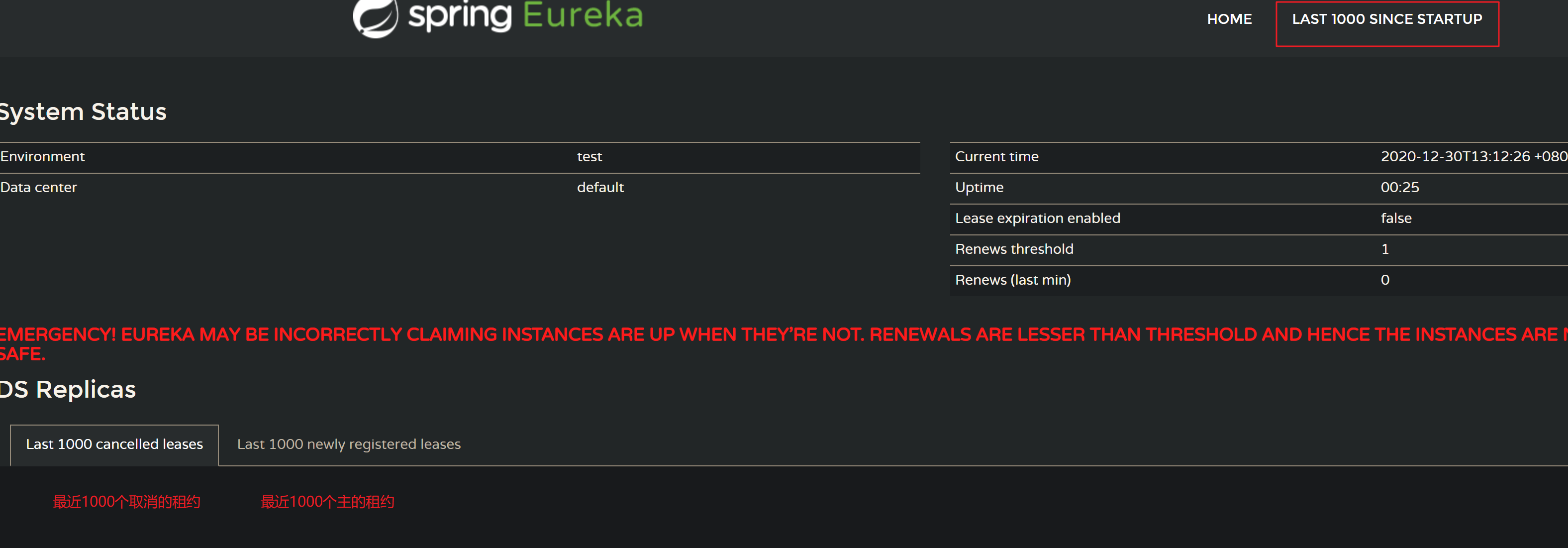
EMERGENCY! EUREKA MAY BE INCORRECTLY CLAIMING INSTANCES ARE UP WHEN THEY’RE NOT. RENEWALS ARE LESSER THAN THRESHOLD AND HENCE THE INSTANCES ARE NOT BEING EXPIRED JUST TO BE SAFE.
这就是服务自保开启后的警告, 意思是说, 挂掉的服务有可能会被错误的当做UP, (在一定时间内)续约成功的节点个数占已注册总服务的比值, 已经低于限定值, 因此所有节点都不会过期, 服务自保开启.
这是一个服务自保的自动触发开关, 简单来说, 服务自保机制会检查过去15分钟以内, 所有成功续约的节点, 占所有注册节点的比例, 如果低于一个限定值(比如85%)就开启服务自保模式.
服务自保模式往往是为了应对短暂的网络环境问题, 在理想情况下服务节点的续约成功率应该接近100%, 如果突然发生网络问题, 比如一部分机房无法连接到注册中心, 这时候续约成功率有可能大幅降低. 但考虑到Eureka采用客户端的服务发现模式, 客户端手里有所有节点的地址, 如果服务节点只是因为网络原因无法续约但其自身服务是可用的, 那么客户端仍然可以成功发起调用请求. 这样就避免了被服务剔除给错杀.
手动开关
这是服务自保的总闸, 以下配置将强制关闭服务自保, 即便上面的自动开关被触发, 也不能开启自保功能.
eureka.server.enable-self-preservation=false
服务下线
- 服务下线, 通常由服务器关闭, 或主动调用shutdown方法来触发, 是由服务节点主动向注册中心发起的资源释放命令.
下线代表着服务的生命周期走到了尾声, 服务节点在工作岗位站到了最后一刻.
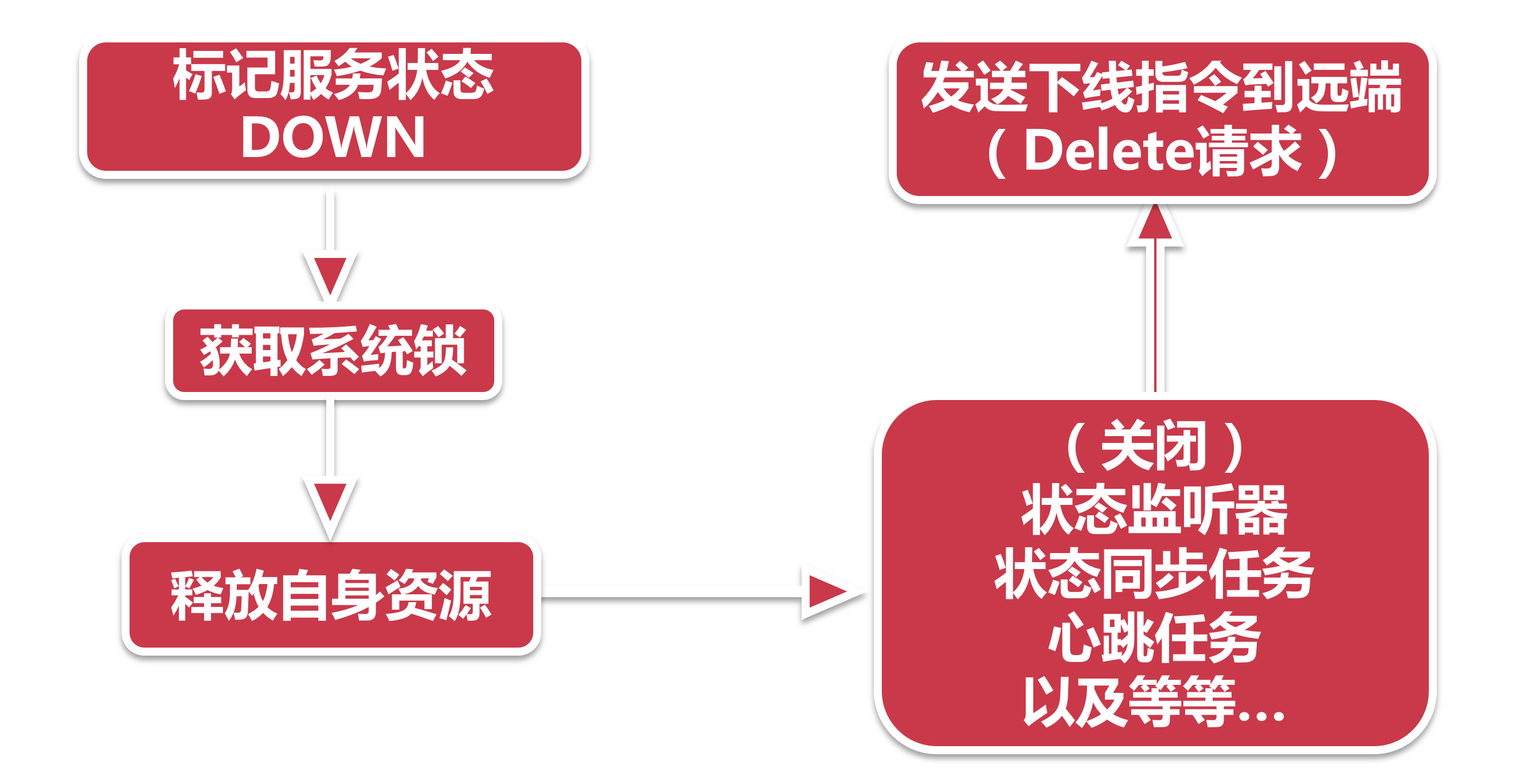
- 标记状态:下线的第一步, 就要先给自己立一个flag. 这一步在
EurekaServiceRegistry.deregister里完成, 这个方法也只做一件事件. - 获取系统锁:服务下线, 为了防止反复执行, 需要借助一个特殊的锁, 来完成线程安全的下线操作.
- 释放资源:在服务注册伊始, 服务节点创建了很多监听和后台任务, 比如状态监听会在服务状态变化的时候同步给注册中心, 心跳会主动发送心跳包, 还有很多资源, 都会被一同关闭或者释放.
- 发送下线指令:发送一个Delete指令到注册中心, 完成整个服务下线请求.
锁
Java中的线程安全方法有很多, 比如大家熟知的synchronize, 或者借助concurrent包下的各种类. 可是当面试官问你, 抛开这些, 你还有什么线程安全的方式?有的人可能会说Thread中的wait和notify.
刚才我们说的都是Java层面提供的封装好的机制, 然而还有一个利用底层操作系统实现的乐观同步锁, 他叫做CAS, 即Compare and Swap. 从字面意思上理解, 就是先比较, 再替换的过程, 比如我们拿服务下线里的操作看, 它调用了AtomicBoolean的CAS操作.
public final boolean compareAndSet(boolean expect, boolean update) {
int e = expect ? 1 : 0;
int u = update ? 1 : 0;
return unsafe.compareAndSwapInt(this, valueOffset, e, u);
}
这里的expect和update入参是不同的两个值, expect=false, update=true, 而最后一行unsafe.compareAndSwapInt操作是看不到源码的, 因为CAS操作是借助了底层操作系统的接口, 因此这实际是一个被native关键字修饰的由操作系统实现的方法. 操作系统的cas操作会将内存值与expect值进行比较, 如果相等就会将update参数更新到内存, 并返回成功, 如果不等则返回失败, 在操作系统层面, 这个比对-替换的操作是原子性的, 所以也就可以保证线程安全. 这和我们平时业务代码中的乐观锁实现比较类似.
当然, CAS也有一个著名的ABA问题, 也就是当内存值从A变到B, 然后再变回A的情况下, 假如我的期望值是A, 尽管中途发生了A->B的变化, 可是因为最终又变回了A, 因此CAS操作依然认为内存值是没有发生变化的. 我想这个问题难不倒大家, 解决方法很简单, 用简单的版本号控制的方式规避掉就可以了(在比对的时候同时验证版本号, 每次修改后版本号+1).
如何保证注册中心的高可用, 单中心宕机的思考
高可用
就是保证服务在各种异常面前, 都可以提供服务.
- 故障容错(服务降级, 商品详情页面, 评论模块出问题了, 可以先不渲染
- 故障恢复(出现双高情况, 运维脚本会监听自动重启
高可用注册中心
集群 + 互备
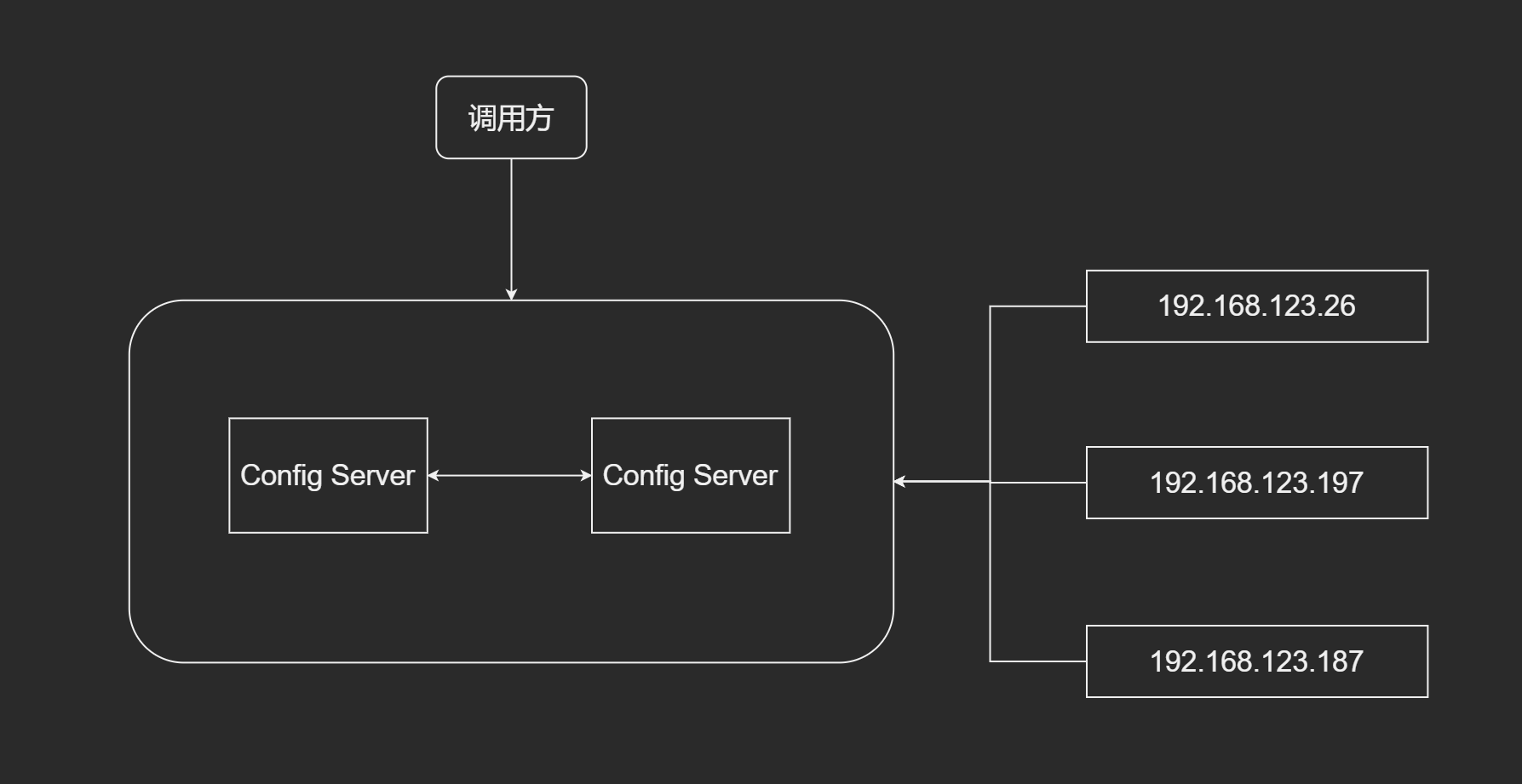
- Server固有一死
- 警惕挖掘机
- Latency(延迟)
- Brave

博客内容遵循 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 协议
本文永久链接是:https://blog.lgq51233.xyz/2020/12/30/%E6%9C%8D%E5%8A%A1%E6%B2%BB%E7%90%86%E5%AE%9E%E6%88%98/