
分库分表和读写分离
分库分表, 读写分离
数据切分
数据切分, 简单的说, 就是通过某种条件, 将之前存储在一台数据库上的数据, 分散到多台数据库中, 从而达到降低单台数据库负载的效果. 数据切分, 根据其切分的规则, 大致分为两种类型, 垂直切分和水平切分.
垂直切分
垂直切分就是按照不同的表或者Schema切分到不同的数据库中, 比如: 在的课程中, 订单表(order)和商品表(product)在同一个数据库中, 而现在要对其切分, 使得订单表(order)和商品表(product)分别落到不同的物理机中的不同的数据库中, 使其完全隔离, 从而达到降低数据库负载的效果.
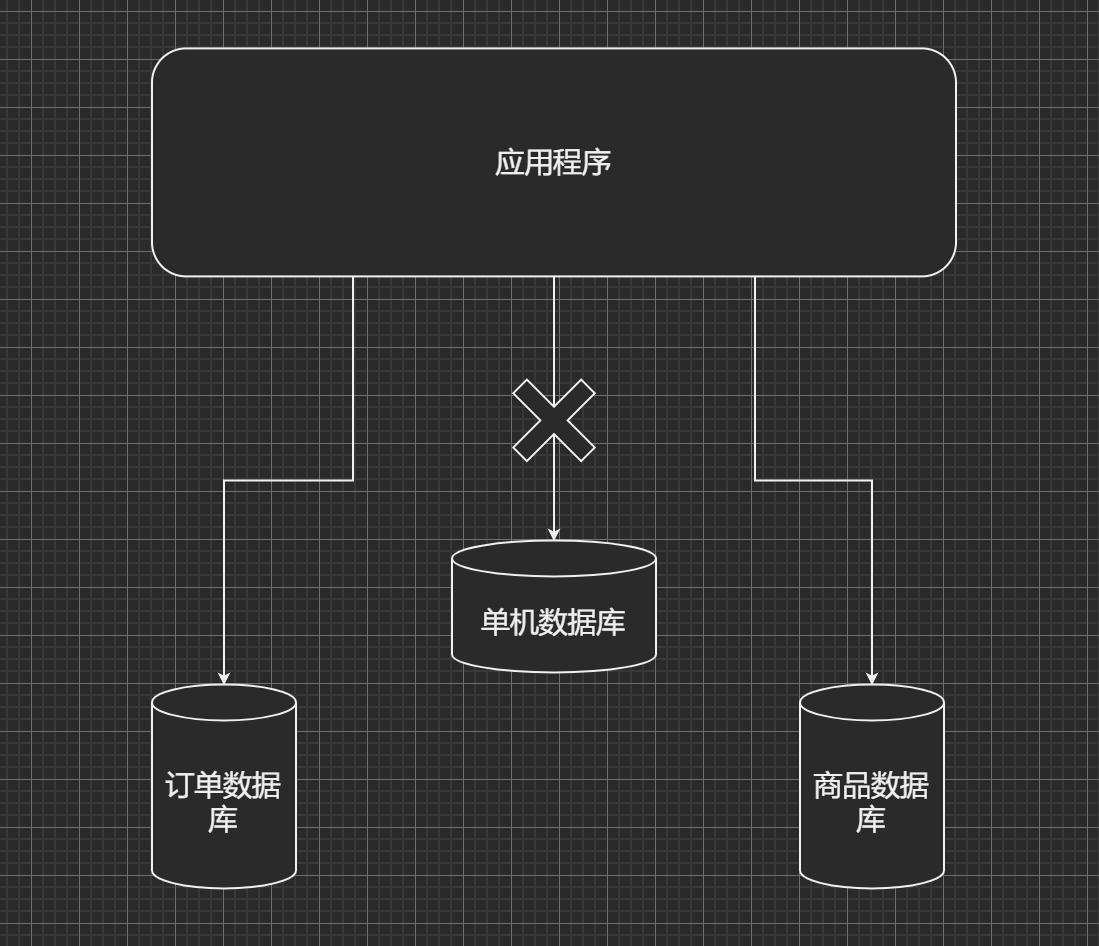
垂直切分的特点就是规则简单, 易于实施, 可以根据业务模块进行划分, 各个业务之间耦合性低, 相互影响也较小.
一个架构设计较好的应用系统, 其总体功能肯定是有多个不同的功能模块组成的. 每一个功能模块对应着数据库里的一系列表. 例如在咱们的课程当中, 商品功能模块对应的表包括: 类目, 属性, 属性值, 品牌, 商品, sku等表. 而在订单模块中, 对应的表包括: 订单, 订单明细, 订单收货地址, 订单日志等.
在架构设计中, 各个功能模块之间的交互越统一, 越少越好. 这样, 系统模块之间的耦合度会很低, 各个系统模块的可扩展性, 可维护性也会大大提高. 这样的系统, 实现数据的垂直切分就会很容易.
但是, 在实际的系统架构设计中, 有一些表很难做到完全的独立, 往往存在跨库join的现象. 还是上面的例子, 比如接到了一个需求, 要求查询某一个类目产生了多少订单, 如果在单体数据库中, 直接连表查询就可以了. 但是现在垂直切分成了两个数据库, 跨库连表查询是十分影响性能的, 也不推荐这样用, 只能通过接口去调取服务, 这样系统的复杂度又升高了. 对于这种很难做到完全独立的表, 作为系统架构设计人员, 就要去做平衡, 是数据库让步于业务, 将这些表放在一个数据库当中?还是拆分成多个数据库, 业务之间通过接口来调用呢?在系统初期, 数据量比较小, 资源也有限, 往往会选择放在一个数据库当中. 而随着业务的发展, 数据量达到了一定的规模, 就有必要去进行数据的垂直切分了. 而如何进行切分, 切分到什么程度, 则是对架构师的一个艰难的考验.
优点:
- 拆分后业务清晰, 拆分规则明确
- 系统之间容易扩展和整合
- 数据维护简单
缺点:
- 部分业务表无法join, 只能通过接口调用, 提升了系统的复杂度
- 跨库事务难以处理
- 垂直切分后, 某些业务数据过于庞大, 仍然存在单体性能瓶颈
水平切分
水平切分相比垂直切分, 更为复杂. 它需要将一个表中的数据, 根据某种规则拆分到不同的数据库中, 例如: 订单尾号为奇数的订单放在了订单数据库1中, 而订单尾号为偶数的订单放在了订单数据库2中. 这样, 原本存在一个数据库中的订单数据, 被水平的切分成了两个数据库. 在查询订单数据时, 还要根据订单的尾号, 判断这个订单在数据库1中, 还是在数据库2中, 然后将这条SQL语句发送到正确的数据库中, 查出订单.
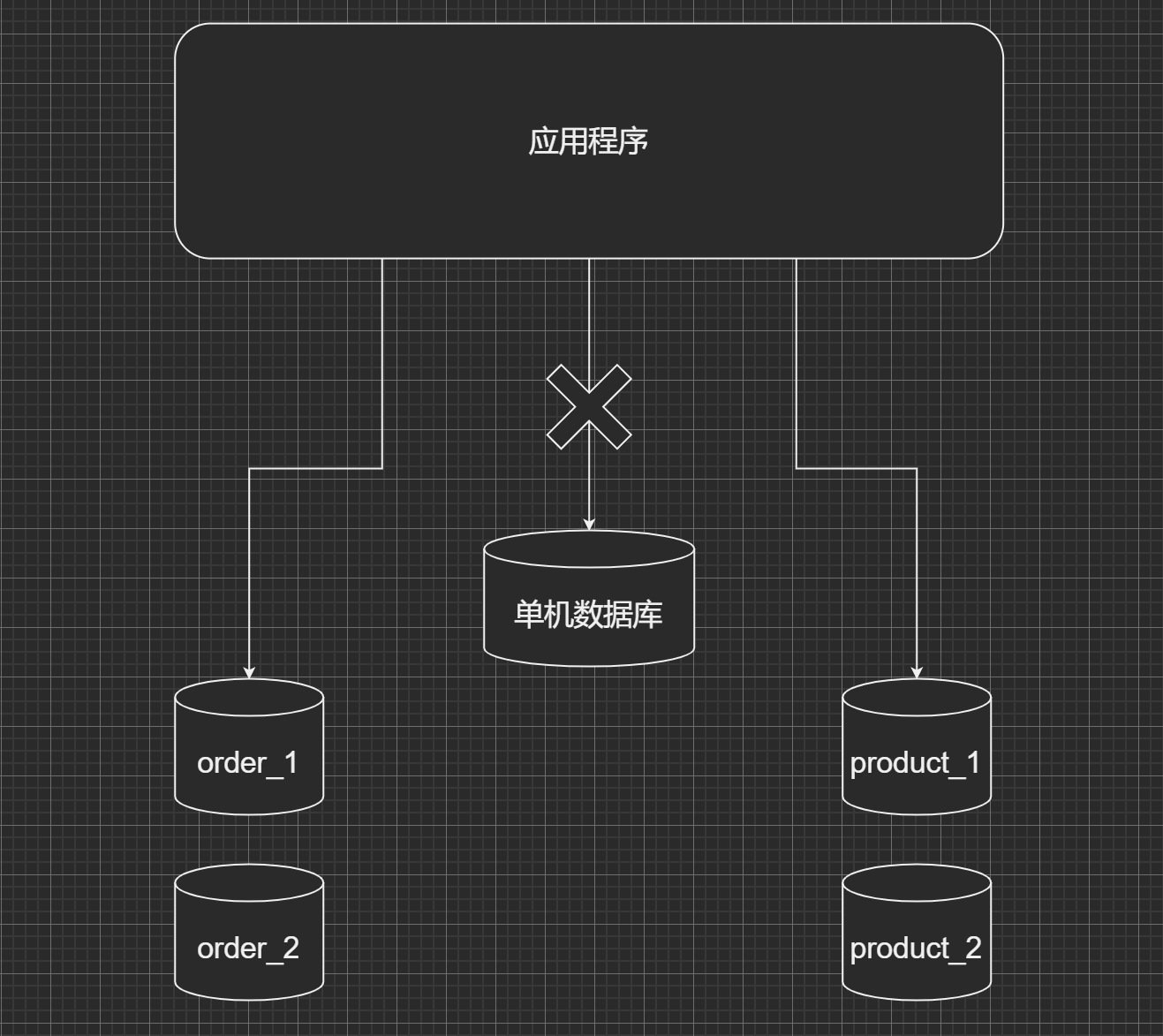
水平拆分数据, 要先订单拆分的规则, 找到你要按哪个维度去拆分, 还是前面订单的例子, 按照订单尾号的奇偶去拆分, 那么这样拆分会有什么影响呢?假如我是一个用户, 我下了两个订单, 一个订单尾号为奇数, 一个订单尾号为偶数, 这时, 我去个人中心, 订单列表页去查看我的订单. 那么这个订单列表页要去怎么查, 要根据我的用户id分别取订单1库和订单2库去查询出订单, 然后再合并成一个列表, 是不是很麻烦. 所以, 咱们在拆分数据时, 一定要结合业务, 选择出适合当前业务场景的拆分规则. 那么按照用户id去拆分数据就合理吗?也不一定, 比如: 咱们的身份变了, 不是买家了, 而是卖家, 我这个卖家有很多的订单, 卖家的后台系统也有订单列表页, 那这个订单列表页要怎么样去查?是不是也要在所有的订单库中查一遍, 然后再聚合成一个订单列表呀. 那这样看, 是不是按照用户id去拆分订单又不合理了.
分片规则:
- 用户id求模, 前面已经提到过
- 按照日期去拆分数据
- 按照其他字段求模, 去拆分数据
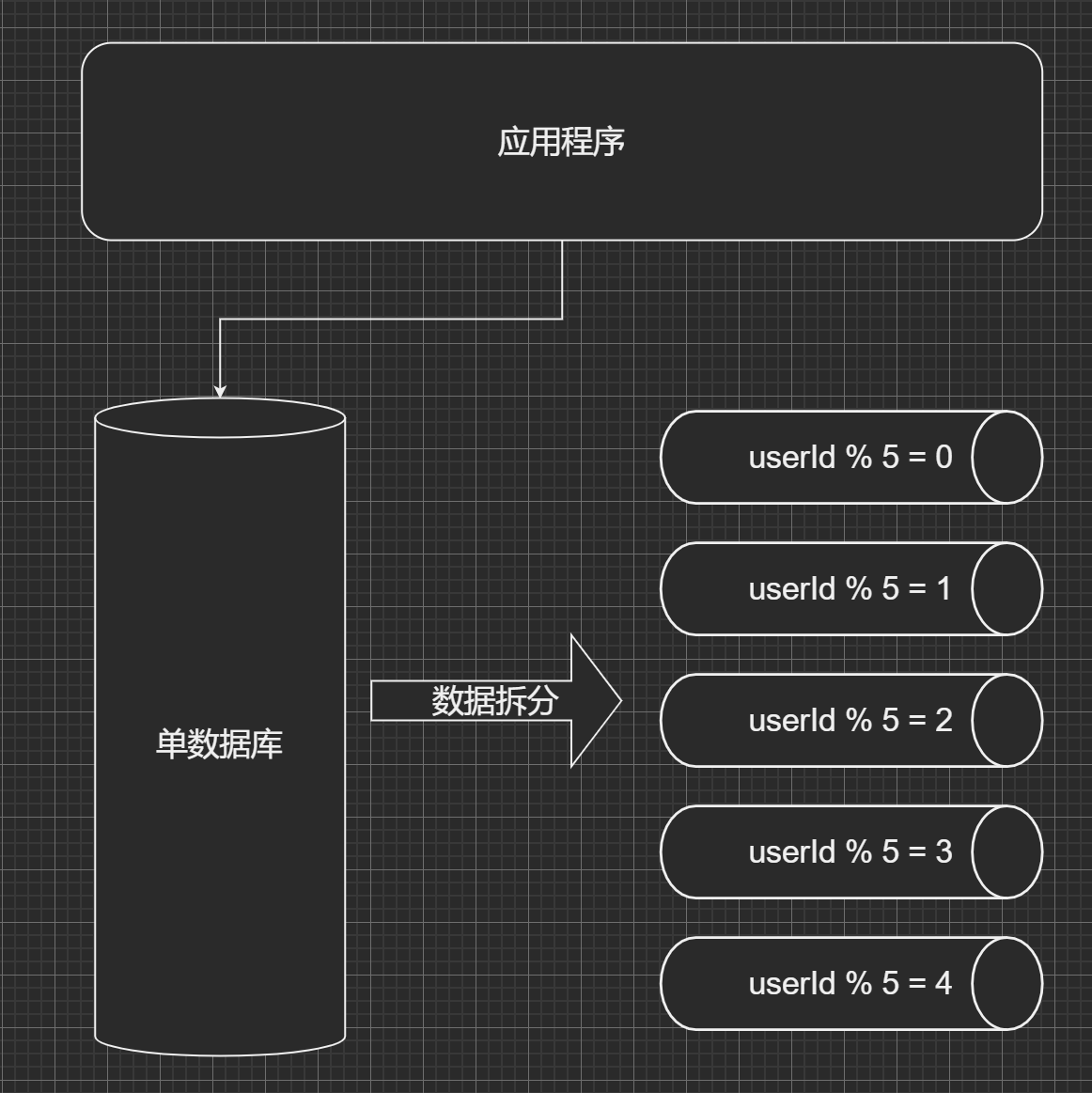
优点:
- 解决了单库大数据, 高并发的性能瓶颈
- 拆分规则封装好, 对应用端几乎透明, 开发人员无需关心拆分细节
- 提高了系统的稳定性和负载能力
缺点:
- 拆分规则很难抽象
- 分片事务一致性难以解决
- 二次扩展时, 数据迁移, 维护难度大. 比如: 开始按照用户id对2求模, 但是随着业务的增长, 2台数据库难以支撑, 还是继续拆分成4个数据库, 那么这时就需要做数据迁移了.
共同缺点
- 分布式的事务问题
- 跨库join问题
- 多数据源的管理问题
针对多源数据, 主要两种思路:
- 客户端模式, 在每个应用模块内, 配置自己需要的数据源, 直接访问数据库, 在各模块内完成数据的整合.
- 中间代理模式, 中间代理统一管理所有的数据源, 数据库层对开发人员完全透明, 开发人员无需关注拆分的细节.
基于这两种模式, 目前都有成熟的第三方软件, 接下来在的视频中, 会分别给大家介绍这两种模式的代表作
- 中间代理模式: MyCat
- 客户端模式: sharding-jdbc
读写分离
随着访问量的升高, 人们对系统的可靠性有了更高的要求, 所以, 为了避免单点故障, 对系统应用层进行了横向的扩展.
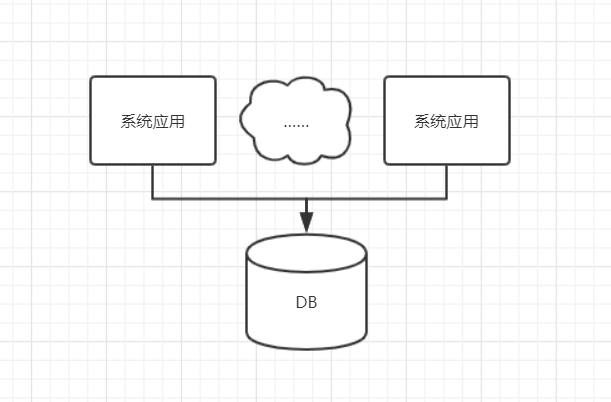
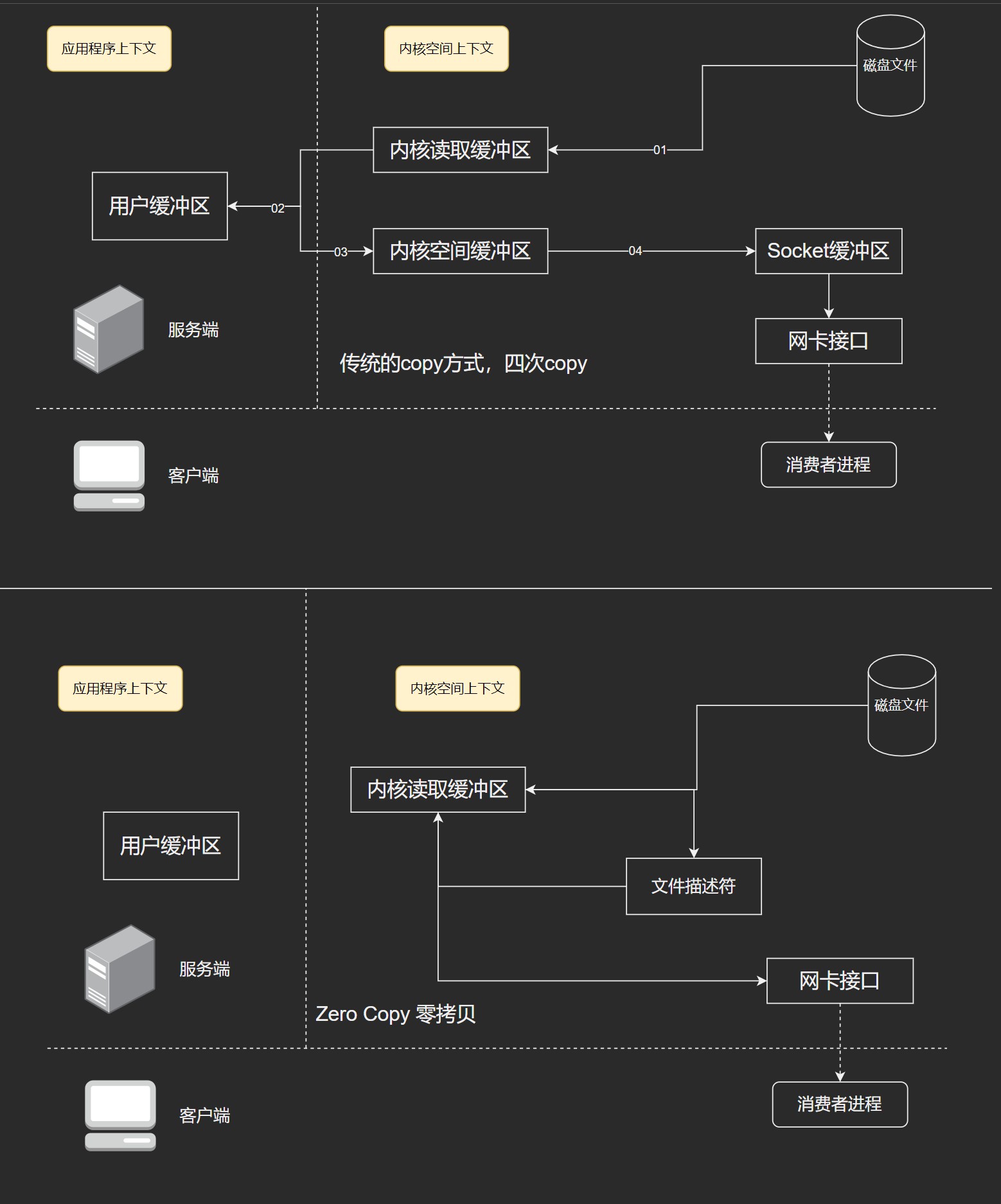
这样, 保证了系统应用层的高可用, 在发生宕机, 或者系统升级时, 系统对外还是可用的. 而且在访问量升高的时候, 系统应用层的压力也会得到分摊, 使得每一个单体的系统应用的压力在一个合理的区间范围内. 但是, 随着访问量的升高, 所有的压力都将集中到数据库这一层. 所以把读操作和写操作分开, 让所有读的请求落到专门负责读的数据库上, 所有写的操作落到专门负责写的数据库上, 写库的数据同步到读库上, 这样保证所有的数据修改都可以在读取时, 从读库获得, 系统的架构如图所示:
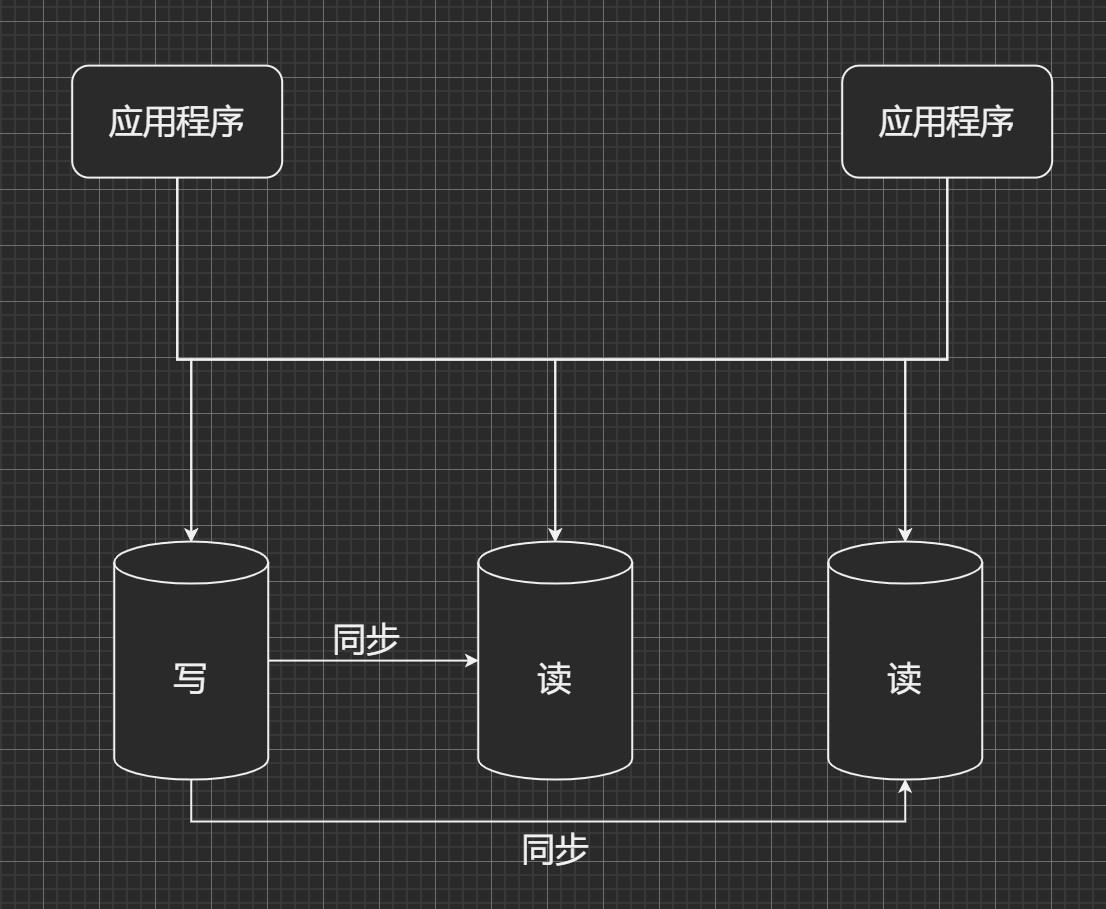
如果系统的读请求比较多的话, 读库可以多部署几台, 这样读请求就可以均摊到多台读库上, 降低每一个读库上的压力. 但是在写数据的时候, 数据要落在一个确定, 且唯一的写库中.
以一个写库为例, 比如: 商户发布商品时, 将这个商品的数据落在了写库上, 同时, 写库将这条数据同步给两个读库, 买家在网站浏览商品时, 会从读库将这个商品数据读取. 至于从哪个读库取出数据, 那就要看这个请求在当时的路由情况了. 将大量的读操作从数据库中剥离, 让读操作从专用的读数据库中读取数据, 大大缓解了数据库的访问压力, 也使得读取数据的响应速度得到了大大的提升.
缺点:
对比一下原始的架构和读写分离的架构, 从数据流上看, 他们的区别是, 数据从写入到数据库, 到从数据库取出, 读写分离的架构多了一个同步的操作. 读写分离的弊端, 当同步挂掉, 或者同步延迟比较大时, 写库和读库的数据不一致, 这个数据的不一致, 可能会造成一些问题.
使用场景:
一些对数据实时性要求不高的业务场景, 可以考虑使用读写分离. 但是对数据实时性要求比较高的场景, 比如订单支付状态, 还是不建议采用读写分离的, 或者你在写程序时, 老老实实的从写库去读取数据. 数据同步的机构, 他们给出的建议是, 如果你做数据的同步, 你的网络延迟应该在5ms以内, 这个对网络环境要求是非常高的, 大家可以ping一下你网络中的其他机器, 看看能不能达到这个标准. 如果你的网络环境很好, 达到了要求, 那么使用读写分离是没有问题的, 数据几乎是实时同步到读库, 根本感觉不到延迟.
MySQL 主从模式
主写从读.
主配置log-bin, 指定文件的名称.
主配置server-id, 默认为1.
从配置server-id 与主不能重复.
192.168.123.26是主, 192.168.123.197是从.
# 修改 mysql 的配置文件 在 /etc/my.cnf.d 下面
cd /etc/my.cnf.d
vim server.cnf
# 主数据库 输入如下内容
[mysqld]
log-bin=mysql-bin #开启二进制日志
server-id=1 #服务id, 不可重复
# 从数据库 输入如下内容
[mysqld]
server-id=2 # 服务id, 不可重复
sql_mode='STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION'
# 然后重启数据库
systemctl restart mysqld
# 在主数据库创建一个备份账号 replication slave
create user 'lgq'@'%' identified by 'lgq';
# 授权
grant replication slave on *.* to 'lgq'@'%';
# 刷新权限
flush privileges;
# 主进行锁表 防止新数据的产生 主从配置需要配置 binlog 位置
flush tables with read lock;
# 主找到 log-bin 位置 Position
show master status;
# 查看二进制日志相关的配置项
show global variables like 'binlog%';
# 查看server相关的配置项
show global variables like 'server%';
# 主数据库备份 先退出cli
mysqldump --all-databases --master-data > dbdump.db -uroot -p
# 还原数据
mysql < dbdump.db -uroot -p
# 解锁
unlock tables;
# 在 从库 上面设置 主库 的配置
CHANGE MASTER TO
master_host='192.168.123.26',
master_user='lgq',
master_password='lgq',
master_port=3306,
master_log_file='mysql-bin.000001',
master_log_pos=1623;
# 启动同步
start slave;
# 查看slave状态
show slave status;
# 主从复制模式
# STATEMENT模式(SBR)
# 修改主库的配置
binlog_format=MIXED
# 重启
systemctl restart mysqld
# 修改从库, 因为主库状态改变了
stop slave;
CHANGE MASTER TO
master_host='192.168.123.26',
master_user='lgq',
master_password='lgq',
master_port=3306,
master_log_file='mysql-bin.000001',
master_log_pos=1623;
start slave;
MyCat
MyCat是一个开源的分布式数据库系统, 前端的用户可以把它看成一个数据库代理, 用MySql客户端和命令行工具都可以访问, 而其后端则是用MySql原生的协议与多个MySql服务之间进行通信. MyCat的核心功能是分库分表, 即将一个大表水平切分成N个小表, 然后存放在后端的MySql数据当中.
MyCat是一个强大的数据库中间件, 不仅仅可以用作读写分离, 分库分表, 还可以用于容灾备份, 云平台建设等, 让你的架构具备很强的适应性和灵活性.
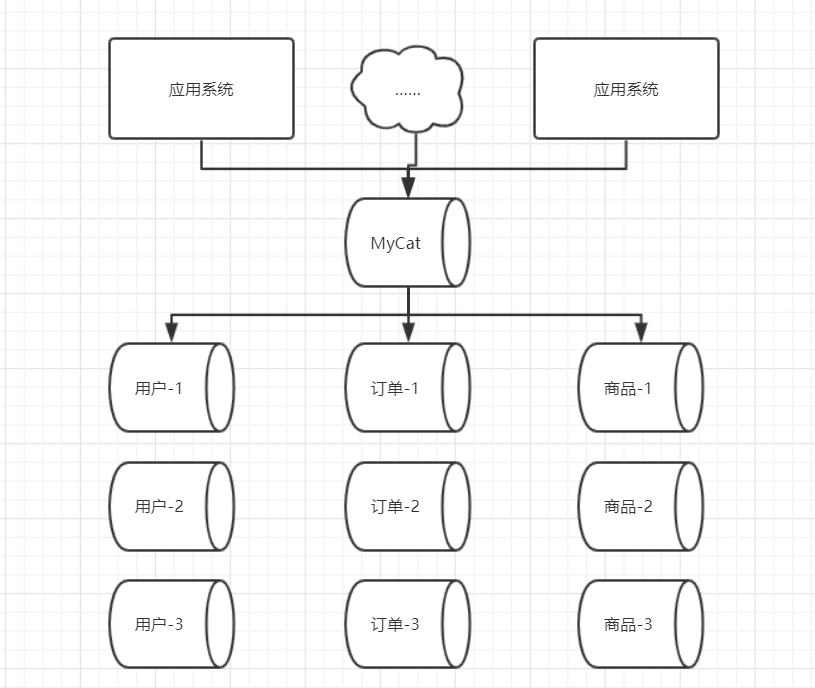
MyCat 应用场景
- 单纯的读写分离, 此时配置最为简单, 支持读写分离, 主从切换
- 分库分表, 对于超过1000w的表进行分片, 最大支持1000亿的数据
- 多租户应用, 每个应用一个数据库, 应用只连接MyCat, 程序本身不需要改造
- 代替HBase, 分析大数据
MyCat 基本概念
逻辑库(Schema): 在实际的开发中, 开发人员不需要知道数据库中间件的存在, 开发人员只需要有数据库的概念就可以了. 所以数据库中间件可以被看做是一个或者多个数据库集群构成的逻辑库. 例如: 上图中的例子, 可以理解为系统先做了垂直切分, 被分为了3个库, 用户库, 订单库, 商品库, 而这3个库就被称为逻辑库.
逻辑表(Table): 既然有逻辑库, 那么就有逻辑表, 对于应用系统来说, 读写数据的表, 就是逻辑表. 而逻辑表中的数据, 则是被水平切分后, 分布在不同的分片库中. 如上图所示: 假设用户库中有一张用户表, 这个用户表就被称为逻辑表, 而用户表又被水平切分为3个表, 每一个表中都存储一部分用户数据. 业务系统在进行用户数据的读写时, 只需要操作逻辑表就可以了, 后面的分片细节则由MyCat进行操作, 这些对于业务开发人员来说时完全透明的. 当然, 有些表的数据量没有那么大, 完全不需要进行分片, 只在一个物理的数据库表中即可. 凡是做的数据水平切分的表, 把它叫做分片表. 而数据量比较小, 没有进行分片的表, 叫它非分片表.
在真实的业务系统中, 往往存在着大量的字典表, 这些表的数据基本上很少变动, 比如: 订单状态. 查询的时候, 往往需要关联字典表去查询, 比如: 查询订单时, 需要把订单状态关联查出, 如果订单表做了分片, 分布在不同的数据库中, 而订单状态表由于数据量小, 没有做分片, 那么查询的时候就要跨库关联查询订单状态, 增加了不必要的麻烦, 不如干脆把订单状态表冗余到所有的订单分片库中, 这样关联查询就不需要跨库了. 把这种通过数据冗余方式复制到所有的分片库中的表, 叫做全局表.
分片节点(dataNode): 数据被切分后, 一张大表被分到不同的分片数据库上面, 每个分片表所在的数据库就叫做分片节点.
节点主机(dataHost): 数据切分后, 每一个分片节点不一定都会占用一个真正的物理主机, 会存在多个分片节点在同一个物理主机上的情况, 这些分片节点所在的主机就叫做节点主机. 为了避免单节点并发数的限制, 尽量将读写压力高的分片节点放在不同的节点主机上.
分片规则(rule): 一个大表被拆分成多个分片表, 就需要一定的规则, 按照某种业务逻辑, 将数据分到一个确定的分片当中, 这个规则就叫做分片规则. 数据切分选择合适的分片规则非常重要, 这将影响到后的数据处理难度, 结合业务, 选择合适的分片规则, 是对架构师的一个重大考验. 对于架构师来说, 选择分片规则是一个艰难的, 难以抉择的过程.
全局序列号(squence): 原来在一张表的时候, 采用id自增, 但是数据分布到多个库怎么办?比如: 向用户表插入数据, 第一条记录插入了用户库1, 它的id为1;第二条记录插入了用户库2, 如果是自增, 它的id也为1. 这样id就混乱了, 也无法确定一条数据的唯一标识了. 这时, 需要借助外部的机制保证数据的唯一标识, 这种保证数据唯一标识的机制, 叫做全局序列号.
MyCat 安装
mycat部署在192.168.123.130, mysql部署在192.168.123.26和192.168.123.197
wget http://dl.mycat.org.cn/1.6.7.6/20201126013625/Mycat-server-1.6.7.6-release-20201126013625-linux.tar.gz
tar -zxvf Mycat-server-1.6.7.6-release-20201126013625-linux.tar.gz -C /usr/local
# 修改配置文件
vim /conf/server.xml
# 规则文件在 rule.xml 连接端口在 8066
./bin/mycat console
MyCat 管理工具使用
使用工具连接, 端口是 9066
然后输入 show @@help;
常用指令
# 查看 数据节点
show @@datanode;
# 重新加载配置文件
reload @@config;
# 如果修改了数据源, 需要使用
reload @@config_all;
MyCat 配置
server.xml, 配置 MyCAT 用户名, 密码, 权限, schema等.
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mycat:server SYSTEM "server.dtd">
<mycat:server xmlns:mycat="http://io.mycat/">
<system>
<property name="nonePasswordLogin">0</property> <!-- 0为需要密码登陆, 1为不需要密码登陆 ,默认为0, 设置为1则需要指定默认账户-->
<property name="ignoreUnknownCommand">0</property><!-- 0遇上没有实现的报文(Unknown command:),就会报错, 1为忽略该报文, 返回ok报文.
在某些mysql客户端存在客户端已经登录的时候还会继续发送登录报文,mycat会报错,该设置可以绕过这个错误-->
<property name="useHandshakeV10">1</property>
<property name="removeGraveAccent">1</property>
<property name="useSqlStat">0</property> <!-- 1为开启实时统计, 0为关闭 -->
<property name="useGlobleTableCheck">0</property> <!-- 1为开启全加班一致性检测, 0为关闭 -->
<property name="sqlExecuteTimeout">300</property> <!-- SQL 执行超时 单位:秒-->
<property name="sequenceHandlerType">1</property>
<property name="sequnceHandlerPattern">(?:(\s*next\s+value\s+for\s*MYCATSEQ_(\w+))(,|\)|\s)*)+</property>
<property name="subqueryRelationshipCheck">false</property> <!-- 子查询中存在关联查询的情况下,检查关联字段中是否有分片字段 .默认 false -->
<property name="sequenceHanlderClass">io.mycat.route.sequence.handler.HttpIncrSequenceHandler</property>
<property name="processorBufferPoolType">0</property>
<property name="handleDistributedTransactions">0</property>
<property name="useOffHeapForMerge">0</property>
<property name="memoryPageSize">64k</property>
<property name="spillsFileBufferSize">1k</property>
<property name="useStreamOutput">0</property>
<property name="systemReserveMemorySize">384m</property>
<property name="useZKSwitch">false</property>
<property name="strictTxIsolation">false</property>
<property name="parallExecute">0</property>
</system>
<user name="root" defaultAccount="true">
<property name="password">lgq2020</property>
<!-- 多个 schema 直接使用 , 隔开 -->
<property name="schemas">user</property>
</user>
<user name="user">
<property name="password">user</property>
<property name="schemas">user</property>
<property name="readOnly">true</property>
</user>
</mycat:server>
schema.xml, 配置 dataHost (节点主机), 包括读host, 写host; 配置 dataNode (数据节点), 指定到具体的数据库; 配置 schema, 表名, 数据节点, 分片规则等.
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<!-- 要与 server.xml 中的配置相对应 sqlMaxLimit 默认检索100条 checkSQLschema 是否去掉sql中schema -->
<schema name="user" checkSQLschema="true" sqlMaxLimit="100" randomDataNode="dn26">
<!-- rule 定义分片表的规则, 必须与 rule.xml 中的 tableRule 对应 -->
<!-- ruleRequired 是否绑定分片规则, 如果为true, 没有绑定分片规则, 程序报错 -->
<table name="user" primaryKey="id" dataNode="dn26,dn197" rule="auto-sharding-long" autoIncrement="true" fetchStoreNodeByJdbc="true" />
</schema>
<!-- 数据节点 -->
<dataNode name="dn26" dataHost="db26" database="user_26" />
<dataNode name="dn197" dataHost="db197" database="user_197" />
<!-- <dataNode name="dn187" dataHost="S1" database="user_187" /> -->
<!-- 主机节点 最大连接数 最少连接数 -->
<!-- balance
0 不开启读写分离
1 全部的 readHost 与 stand by writeHost 参与 select 语句的负载均衡, 简单的说, 当双
主双从模式(M1->S1, M2->S2, 并且 M1 与 M2 互为主备), 正常情况下, M2,S1,S2 都参与 select 语句的负载 均衡.
2 读写均匀分配
3 读落在readHost上
-->
<!-- writeType 0 落在第一个writeHost上,如果宕机了再落再下一个数据主机上 1 随机 -->
<dataHost name="db26" maxCon="1000" minCon="10" balance="3" writeType="0" dbType="mysql" dbDriver="jdbc" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM1" url="jdbc:mysql://192.168.123.26:3306" user="root" password="lgq2020">
<readHost host="S1" url="jdbc:mysql://192.168.123.187:3306" usr="root" password="lgq51233"></readHost>
</writeHost>
</dataHost>
<dataHost name="db197" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="jdbc" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM2" url="jdbc:mysql://192.168.123.197:3306" user="root" password="lgq2020">
</writeHost>
</dataHost>
</mycat:schema>
MyCat 分片规则
分片枚举
rule.xml
<tableRule name="sharding-by-intfile">
<rule>
<columns>province_id</columns>
<algorithm>hash-int</algorithm>
</rule>
</tableRule>
<function name="hash-int" class="io.mycat.route.function.PartitionByFileMap">
<property name="mapFile">partition-hash-int.txt</property>
<property name="type">0</property>
<property name="defaultNode">0</property>
</function>
partition-hash-int.txt文件
10000=0
10010=1
DEFAULT_NODE=1
MyCat 全局表
- type属性: global为全局表, 不设置则为分片表.
MyCat 子表
子表的分片根据父表的分片来进行.
- childTable: 定义分片子表
- name: 子表名称
- joinKey: 子表中的列, 用于与父表做关联
- parentKey: 标志父表中的列, 与joinKey对应
- primaryKey: 子表主键, 同table标签
- needAddLimit: 同table标签
MyCat HA原理
- 对系统可靠性要求高
- 避免单点故障
- 系统应用, 数据库, 缓存都是双节点
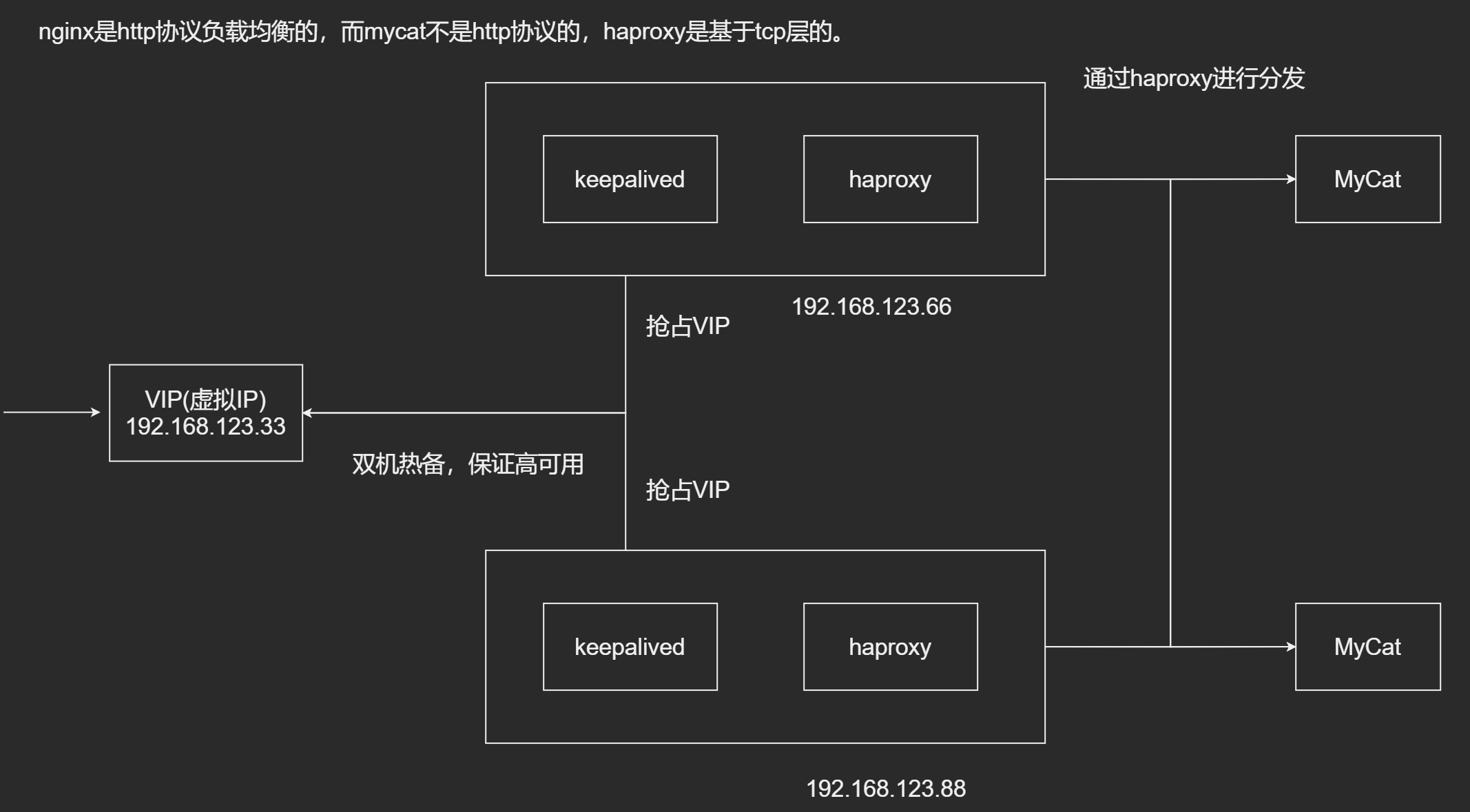
MyCat HA搭建
搭建MyCat, 部署在 192.168.123.129 和 192.168.123.130
# 进入已经部署了mycat的服务器130
scp -r mycat [email protected]:/usr/local/
搭建Haproxy, 部署在 192.168.123.163 和 192.168.123.233
wget https://github.com/haproxy/haproxy/archive/v2.3.0.tar.gz
mv v2.3.0.tar.gz haproxy_v2.3.0.tar.gz
tar -zxvf haproxy_v2.3.0.tar.gz
cd haproxy-2.3.0
mkdir /usr/local/haproxy
make TARGET=linux-glibc PREFIX=/usr/local/haproxy
make install PREFIX=/usr/local/haproxy
# 创建新用户组和用户
groupadd -r -g 149 haproxy
useradd -g haproxy -r -s /sbin/nologin -u 149 haproxy
# 创建配置文件
mkdir /etc/haproxy
touch /etc/haproxy/haproxy.cfg
haproxy.cfg 配置文件
global
log 127.0.0.1 local0 info
maxconn 5120
chroot /usr/local/haproxy
uid 99
gid 99
daemon
quiet
nbproc 20
pidfile /var/run/haproxy.pid
defaults
log global
# 使用4层代理模式, "mode http"为7层代理模式
mode tcp
#if you set mode to tcp,then you nust change tcplog into httplog
option tcplog
option dontlognull
retries 3
option redispatch
maxconn 2000
timeout connect 10s
#客户端空闲超时时间为 3小时 则HA 发起重连机制
timeout client 3h
#服务器端链接超时时间为 3小时 则HA 发起重连机制
timeout server 3h
frontend main
bind *:5000
acl url_static path_beg -i /static /images /javascript /stylesheets
acl url_static path_end -i .jpg .gif .png .css .js
use_backend static if url_static
default_backend app
backend static
balance roundrobin
server static 127.0.0.1:4331 check
backend app
balance roundrobin
server mycat1 192.168.123.129:8066 check
server mycat2 192.168.123.130:8066 check
启动 HaProxy
/usr/local/haproxy/sbin/haproxy -f /etc/haproxy/haproxy.cfg
# 访问 http://192.168.123.129:8100/rabbitmq-stats
关闭 HaProxy
killall haproxy
ps -ef | grep haproxy
netstat -tunpl | grep haproxy
ps -ef |grep haproxy | awk '{print $2}' | xargs kill -9
搭建keepalived, 部署在 192.168.123.163 和 192.168.123.233
vim /etc/keepalived/keepalived.conf, 修改配置文件
! Configuration File for keepalived
global_defs {
notification_email {
[email protected]
[email protected]
[email protected]
}
notification_email_from [email protected]
# smtp_server 192.168.200.1
# smtp_connect_timeout 30
router_id LVS_DEVEL
vrrp_skip_check_adv_addr
#vrrp_strict
vrrp_garp_interval 0
vrrp_gna_interval 0
}
# 注意这个的顺序, 要在配置这个脚本之前的位置才行!!!
vrrp_script chk_haproxy {
# 判断进程是否还在, 使用 ehco $? 查看结果
script "killall -0 haproxy"
interval 2
# script "/etc/keepalived/check_haproxy_alive_or_not.sh" #执行脚本位置
# interval 2 #检测时间间隔
# weight -20 #如果条件成立则权重减20
}
vrrp_instance VI_1 {
# BACKUP
state MASTER
interface ens33
virtual_router_id 51
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.123.88
}
track_script {
chk_haproxy
}
}
virtual_server 192.168.123.88 6000 {
delay_loop 6
lb_algo rr
lb_kind NAT
persistence_timeout 50
protocol TCP
real_server 192.168.123.233 5000 {
weight 1
}
}
启动
# 启动
./keepalived
# 停止 - 杀掉进程
ps -ef | grep keepalived
kill -9 PID
Sharding-Jdbc
- 一个开源的分布式的关系型数据库中间件
- 客户端代理模式
- 定位为轻量级的java框架
- 可以理解为增强型的jdbc驱动
- 兼容各种ORM框架
- 提供了四种配置方式, Java Api, Yaml, SpringBoot 和 Spring命名空间
与 MyCat 的区别
- MyCat 是服务的代理, Sharding-Jdbc是客户端代理
- MyCat 不支持在一个库内的水平切分, Sharding-Jdbc支持
Sharding-Jdbc 使用
查看Git库工程sharding-jdbc-demo

博客内容遵循 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 协议