
分布式消息队列
业界主流的分布式消息队列与技术选型
应用场景
- 服务解耦. 服务的拆分和隔离,业务层面的. 服务之间的通信是强依赖还是弱依赖. 强依赖:直连的方式,同步的 Dubbo 调用,同步的 Http (SpringCloud)或者其它 JRPC方式. 弱依赖:选用消息中间件进行解耦. 弱依赖不代表可以失败. 例如上游的服务发送了一条消息到MQ,那么下游一定要接收到,并做消费处理,那么上游就要做到可靠性的投递.
- 削峰填谷. 即时性高,流量大的应用场景,比如秒杀,大促销等场景. 把流量的高峰和低谷的速率做一个均衡. 下游服务抗不住,处理不过来,可以把消息缓存到一个地方,进行慢消费.
- 异步化缓冲. 最终一致性.
应用思考点
- 生产端的可靠性投递. 例如如果是金融行业的,那么一定要保证消息100%的投递. 消息一定要与数据库保证原子性.
- 消费端幂等. 消费端可能会接收到同样的消息,消费多次会导致消息不一致,所以消费端要保证幂等性.
- 高可用.
- 低延迟.
- 可靠性. 业界基本都是 Replicas(副本). 像es的分片和副本.
- 堆积能力.
- 扩展性. 能否支持天然的,无感知的横向扩容.
业界主流的消息队列
- ActiveMQ. JMS (Java Message Server) 规范.
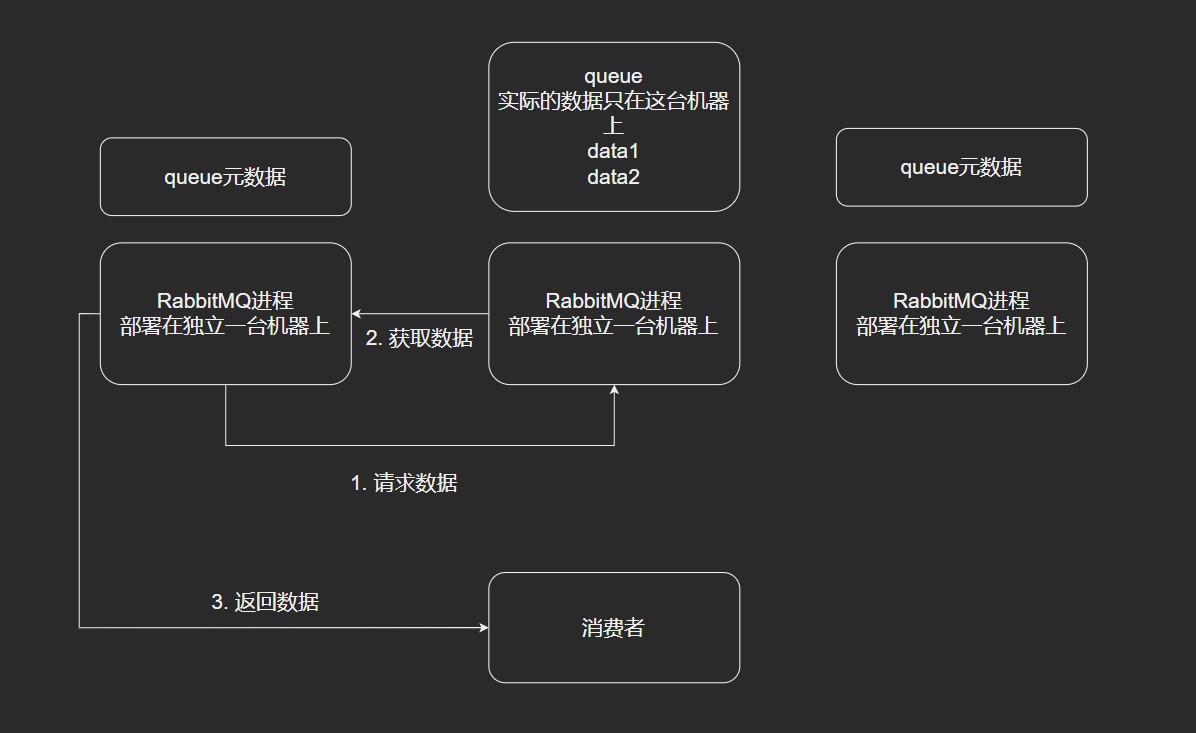
- RabbitMQ. 镜像队列. 横向扩展能力不太好. 滴滴,美团,头条,去哪儿都在使用.
- RocketMQ. 分布式事务. 扩展性好,但是可维护可能不太好.
- Kafka. 海量数据,高吞吐量.
如何进行技术选型
- 各个MQ的性能,优缺点,相应的业务场景. 高并发,海量数据,大流量,ActiveMQ就不合适了,如果说是公司的内部的边缘系统或者中小型公司就完全是可以的.
- 集群架构模式,分布式,扩展性,高可用,可维护性.
- 综合成本问题,集群规模,人员成本.
- 未来的方向,规划,思考
RabbitMQ集群架构模型与原理解析
- 主备模式. 主做读写,备只是个备份,当主宕机时,备升为主节点运行.
- 远程模式. 数据异地容灾,数据转储.
- 镜像模式.
- 多活模式.
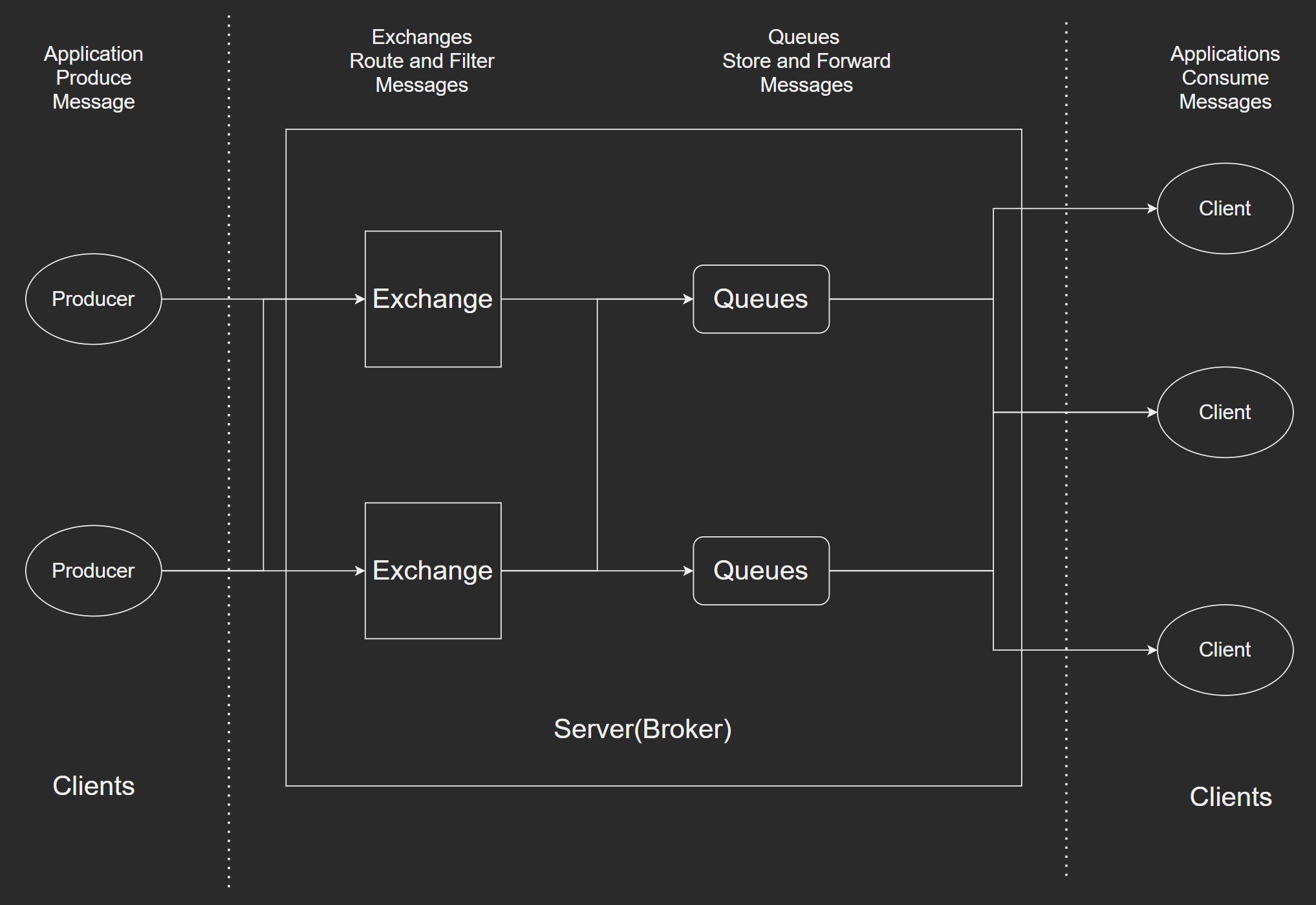
主备模式
主备模式也称为warren(兔子窝)模式. 一个主/备方案(主节点如果挂了,备用节点提供服务,和ActiveMQ利用Zookeeper做主/备一样). 热备份. 使用Haproxy实现. 并发和数据量不高.
主备和主从是不一样的. 主节点可以提供读写,备用节点不提供服务,只是备用的作用;主从模式的话,主节点可以读写,而从节点只提供读功能.
HaProxy配置
listen rabbitmq_cluster
bind 0.0.0.0:5672
mode tcp # 配置TCP模式
balance roundrobin # 简单的轮询
server rb1 192.168.123.26:5672 check inter 5000 rise 2 fall 2 # 主节点 inter每隔5s对mq集群进行健康检查 2次正确证明服务器可用 2次失败证明服务器不可用
server rb2 192.168.123.197:5672 backup check inter 5000 rise 2 fall 2 # 备用节点
远程模式
远距离通信和复制,可以实现双活的一种模式,简称 Shovel 模式. 现在用的不多,可靠性有待提高.
所谓的 Shovel 就是可以把消息进行不同数据中心的复制工作,可以跨地域地让两个mq集群互联. 近端的同步确认,远端的异步确认.
有两个异地的 MQ 集群(可以是更多的集群),当用户在地区 1 这里下单了,系统发消息到 1 区的 MQ 服务器,发现 MQ 服务已超过设定的阈值,负载过高,这条消息就会被转到 地区2 的 MQ 服务器上,由 2 区的去执行后面的业务逻辑,相当于分摊的服务压力.
Shovel 模式配置步骤
- 启动 RabbitMQ 插件
- rabbitmq-plugins enable amqp_client
- rabbitmq-plugins enable rabbitmq_shovel
- 创建 rabbitmq.config 文件
- touch /etc/rabbitmq.config
- 添加配置
- 源与目的服务器使用相同地配置文件(rabbitmq.config)
镜像模式
集群模式非常经典的就是Mirror模式,保证 100% 数据不丢失.
在实际工作中用的最多,并且实现集群非常的简单,一般互联网大厂都会使用这种模式.
- 高可用.
- 数据同步.
- 3节点,一般都使用奇数节点,集群脑裂现象.
不能做横向扩展. 就算是横向添加了,也是添加mq集群的负担,多一个节点,数据同步也就多一份了,吞吐量和性能会受到影响.
Mirror镜像队列,目的是为了保证RabbitMQ数据的高可靠性解决方案,主要就是实现数据的同步.
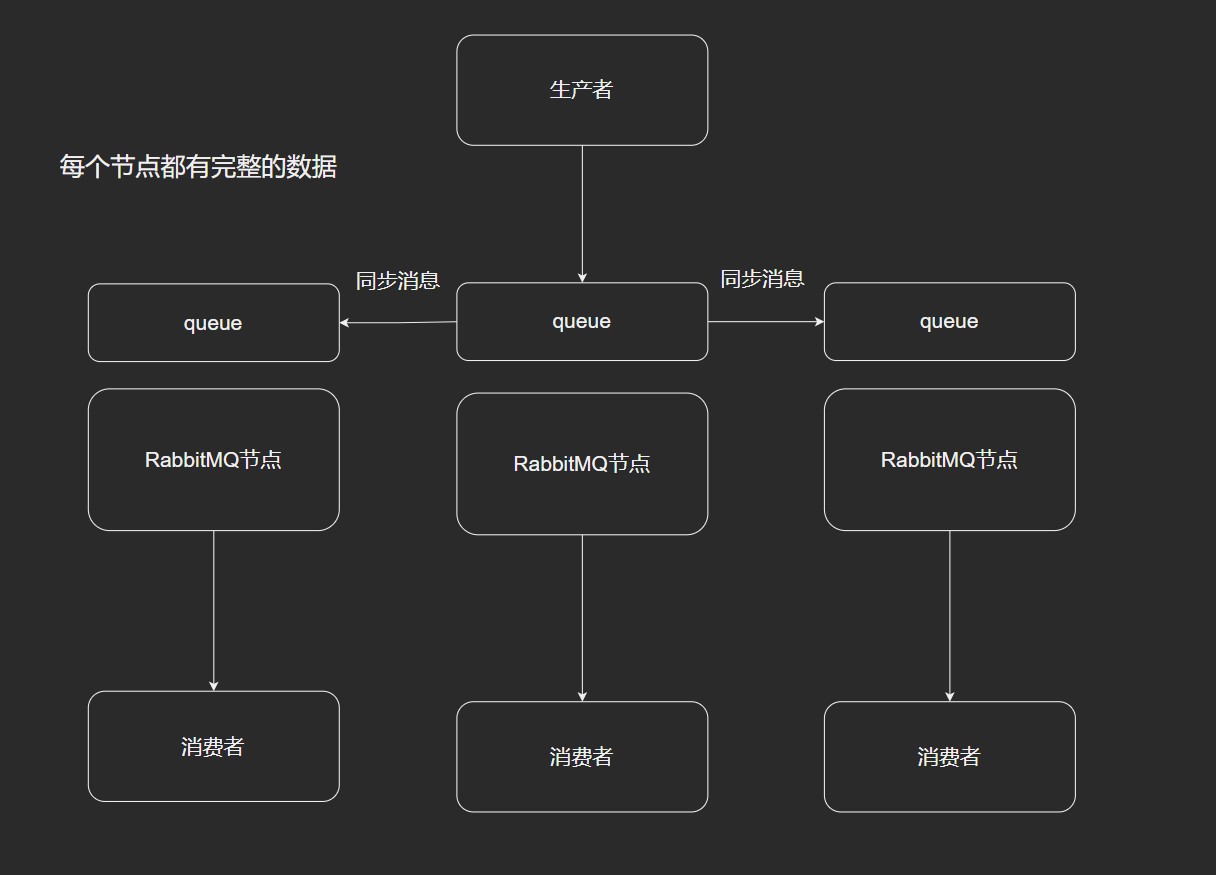
多活模式
这种模式也是实现异地数据复制的主流模式, 因为 Shoνel 模式配置比较复杂, 所以一般来说实现异地集群都是使用这种双活或者多活模型来实现的.
这种模型需要依赖 RabbitMQ 的 federation 插件, 可以实现持续的可靠的 AMQP 数据通信, 多活模式实际配置与应用非常简单.
RabbitMQ部署架构采用双中心模式(多中心), 那么在两套(或多套)数据中心中各部署一套 RabbitMQ集群, 各中心的 RabbitMQ服务 除了需要为业务提供正常的消息服务外, 中心之间还需要实现部分队列消息共享.
Federation 插件是一个不需要构建 Cluster, 而在 Brokers之间传输消息的高性能插件, Federation 插件可以在 Brokers 或者 Cluster 之间传输消息,连接的双方可以使用不同的 users和 virtual hosts, 双方也可以使用版本不同的 RabbitMQ 和 Erlang. Federation 插件使用 AMQP 协议通讯, 可以接受不连续的传输. 统一协议.
Federation Exchanges, 可以看成 Downstream 从 Upstream 主动拉取消息, 但并不是拉取所有消息, 必须是在 Downstream 上已经明确定义 Bindings 关系的 Exchange , 也就是有实际的 物理Queue 来接收消息, 才会从 Upstream 拉取消息到 Downstream. 使用 AMQP协议 实施代理间通信, Downstream 会将绑定关系组合在一起, 绑定/解除绑定命令将发送到 Upstream交换机. 因此, Federation Exchange只接收具有订阅的消息.
RabbitMQ 实战
- 采用Erlang语言作为底层实现:Erlang有着和原生Socket一样的延迟
- 开源、性能优秀、稳定性保障
- 提供可靠消息投递模式(confirm)、返回模式(return)
- 与SpringAMQP完美的整合,API丰富
- 集群模式丰富,表达式配置,HA模式,镜像队列模型
- 保证数据不丢失的前提做到高可靠性、可用性
AMQP 核心概念
具有现代特征的二进制协议,是一个提供统一消息服务的应用层高级消息队列协议,是应用层协议的一个开放标准,为面向消息的中间件设计. 核心部件包括:消息的生产者producer、消息的消费者consumer、MQBroker(Server)、以及内部的Virtual Host、Exchange、Message Queue。
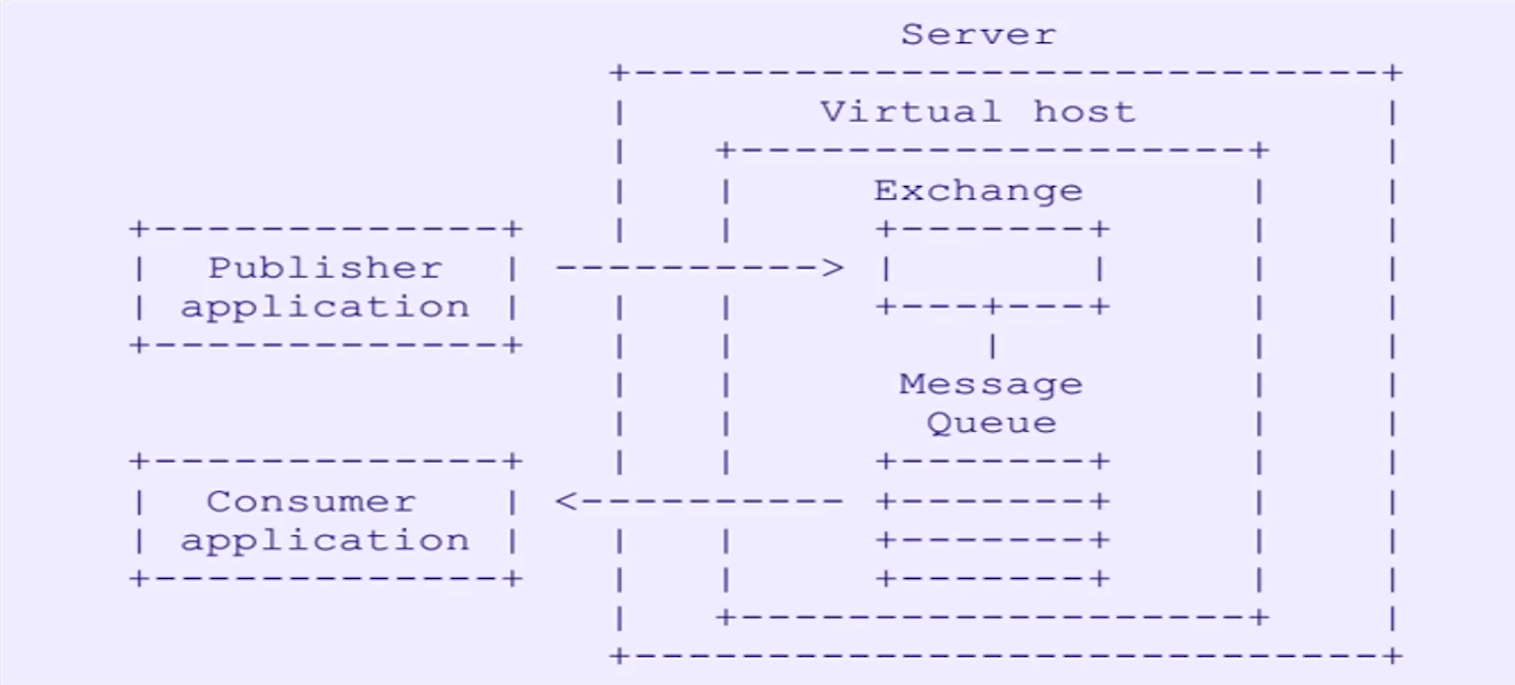
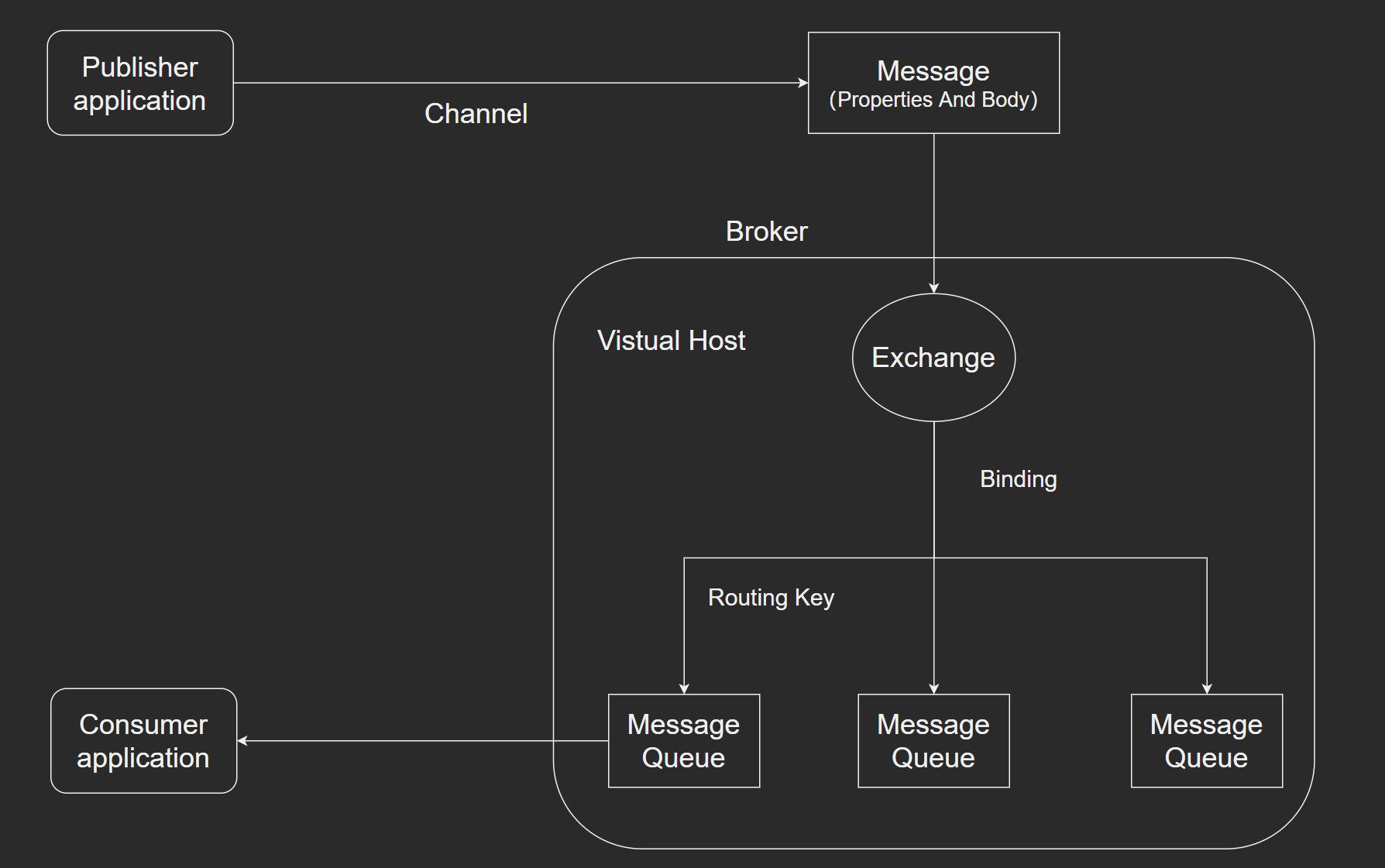
Consumer application 只需要监听消息队列即可。核心在于 Exchange 和 Message Queue 之间有绑定的关系。
AMQP 专有名词解释
AMQP Advanced Message Queuing Protocol
- Server:又称Broker,接受客户端的连接,实现AMQP实体服务.
- Connection:连接,应用程序与Broker的网络连接.
- Channel:网络信道,几乎所有的操作都在Channel中进行,Channel是进行消息读写的通道. 客户端可建立多个Channel,每个Channel代表一个会话任务.
- Message:消息,服务器和应用程序之间传送的数据,由Properties和Body组成. Properties可以对消息进行修饰,比如消息的优先级、延迟等高级特性;Body则就是消息体内容.
- Virtual host:虚拟地址,用于进行逻辑隔离,类似redis的数据库,最上层的消息路由. 一个Virtual Host里面可以有若干个Exchange和Queue,同一个Virtul Host不能有相同名称的 Exchange 或 Queue.
- Exchange:交换机,接收生产者投递的消息,根据路由键转发消息到绑定的队列. 一个Exchange可以绑定多个Queue.
- Binding:Exchange和Queue之间的虚拟连接,binding中可以包含routing key.
- Routing Key:一个路由规则,虚拟机可用它来缺点如何路由一个特定消息.
- Queue:也称为Message Queue,消息队列,保存消息并将他们转发给消费者.
RabbitMQ 安装
CentOS安装(192.168.123.129)
# 安装erlang环境 https://www.erlang-solutions.com/resources/download.html
wget https://packages.erlang-solutions.com/erlang/rpm/centos/8/x86_64/esl-erlang_23.1-1~centos~8_amd64.rpm
# 安装依赖库
yum install -y epel-release
yum install -y erlang.x86_64
# Curl error (37): Couldn't read a file:// file for file:///etc/pki/rpm-gpg/RPM-GPG-KEY-EPEL-8 [Couldn't open file /etc/pki/rpm-gpg/RPM-GPG-KEY-EPEL-8]
rpmkeys --import /etc/pki/rpm-gpg/RPM-GPG-KEY-EPEL-8
# 测试
erl -version
# RabbitMQ 安装
wget https://dl.bintray.com/rabbitmq/all/rabbitmq-server/3.8.9/rabbitmq-server-3.8.9-1.el8.noarch.rpm
# 安装
rpm -ivh rabbitmq-server-3.8.9-1.el8.noarch.rpm --nodeps
# 依赖问题
# socat 被 rabbitmq-server-3.8.9-1.el8.noarch 需要
yum install socat
# 开启用户远程访问
cp rabbitmq.config.example /etc/rabbitmq/rabbitmq.config
vim /etc/rabbitmq/rabbitmq.config
loopback_users = none
# 启动/停止
systemctl start rabbitmq-server
systemctl stop rabbitmq-server
systemctl restart rabbitmq-server
systemctl status rabbitmq-server
# 是否启动成功
lsof -i:15672
netstat -tnlp | grep 15672
# 启动失败查看原因
journalctl -xe
# 报错/usr/lib/rabbitmq/bin/rabbitmq-server:行187: erl: 未找到命令
vim rabbitmq-server
ERL_DIR=/usr/local/erlang/bin/
# 设置开机启动
chkconfig rabbitmq-server on
# Manjaro 安装
pacman -S erlang
pacman -S rabbitmqsyst
# 启动
systemctl start rabbitmq
# 开启web界面
rabbitmq-plugins enable rabbitmq_management
systemctl restart rabbitmq-server
# or
systemctl restart rabbitmq
# 默认登录用户名和密码都是:guest
http://192.168.123.129:15672
RabbitMQ 延迟插件
RabbitMQ 插件下载地址:https://www.rabbitmq.com/community-plugins.html
延迟插件下载地址:https://github.com/rabbitmq/rabbitmq-delayed-message-exchange/releases
# 把下载的插件放在 /usr/lib/rabbitmq/lib/rabbitmq_server-{version}/plugins 下面
# 启用插件
rabbitmq-plugins enable rabbitmq_delayed_message_exchange
# 停止使用插件
rabbitmq-plugins disable rabbitmq_delayed_message_exchange
进入管理后台,添加exchange
创建队列与之绑定
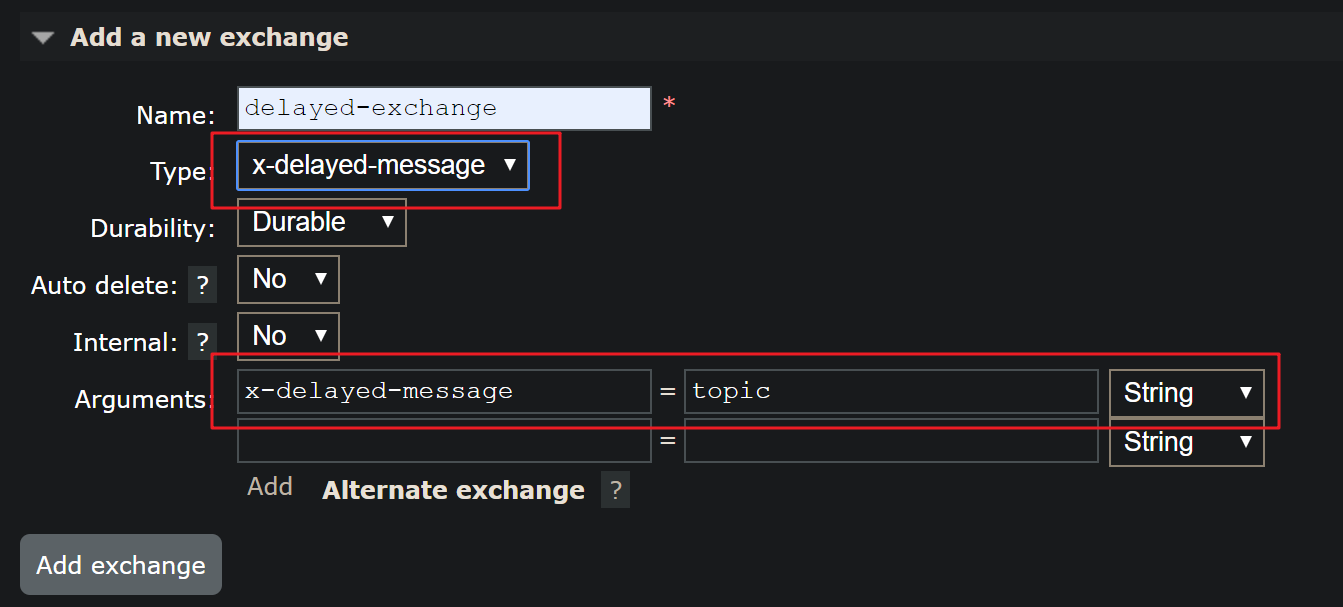
测试
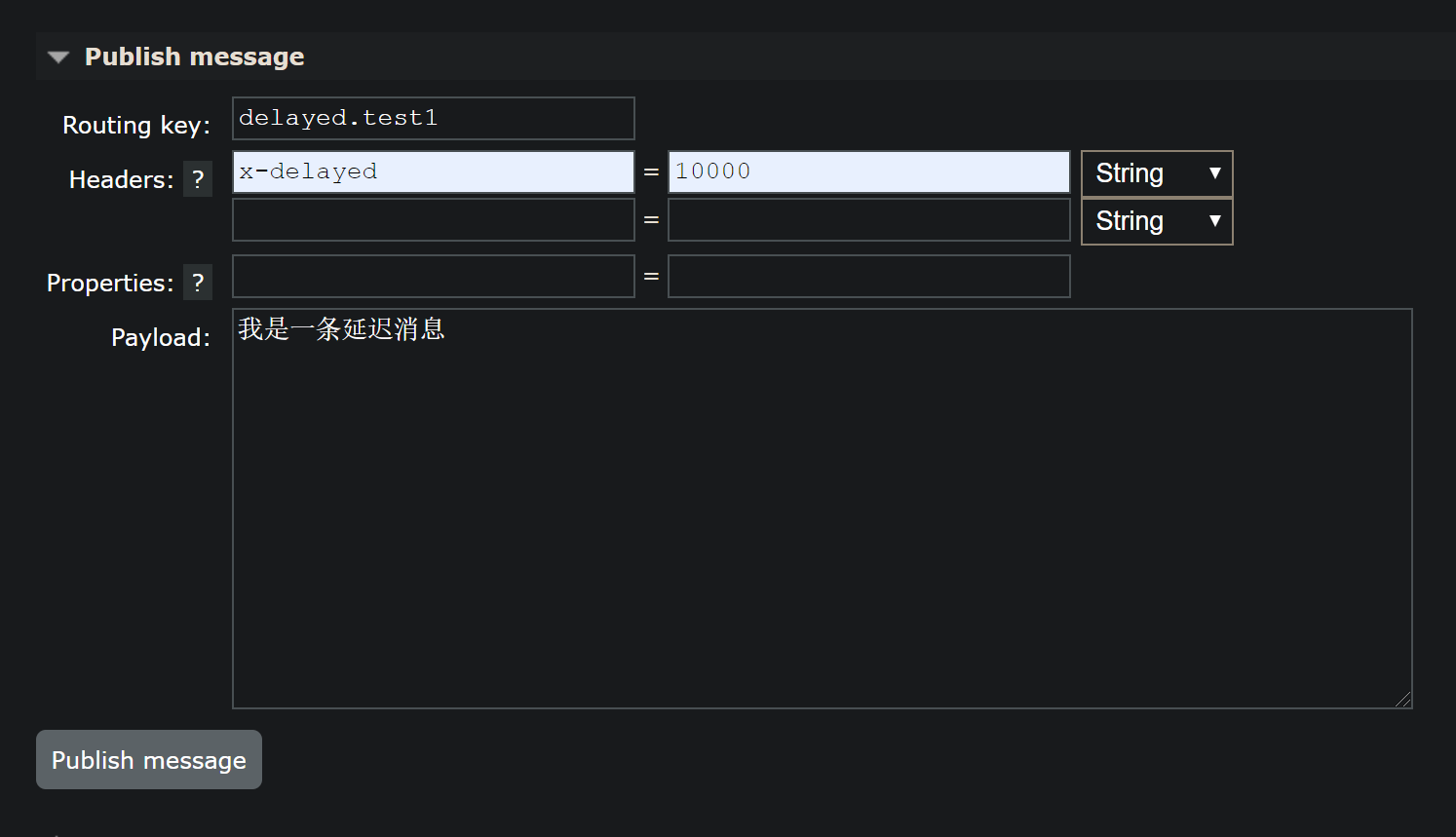
注意:延迟插件不支持内存节点的!!!!
RabbitMQ 集群搭建
官方集群配置文档:http://www.rabbitmq.com/clustering.html
镜像队列文档:http://www.rabbitmq.com/ha.html
集群操作文档:http://www.rabbitmq.com/man/rabbitmqctl.1.man.html
服务:RabbitMQ Cluster + Queue HA + Haproxy + Keepalived
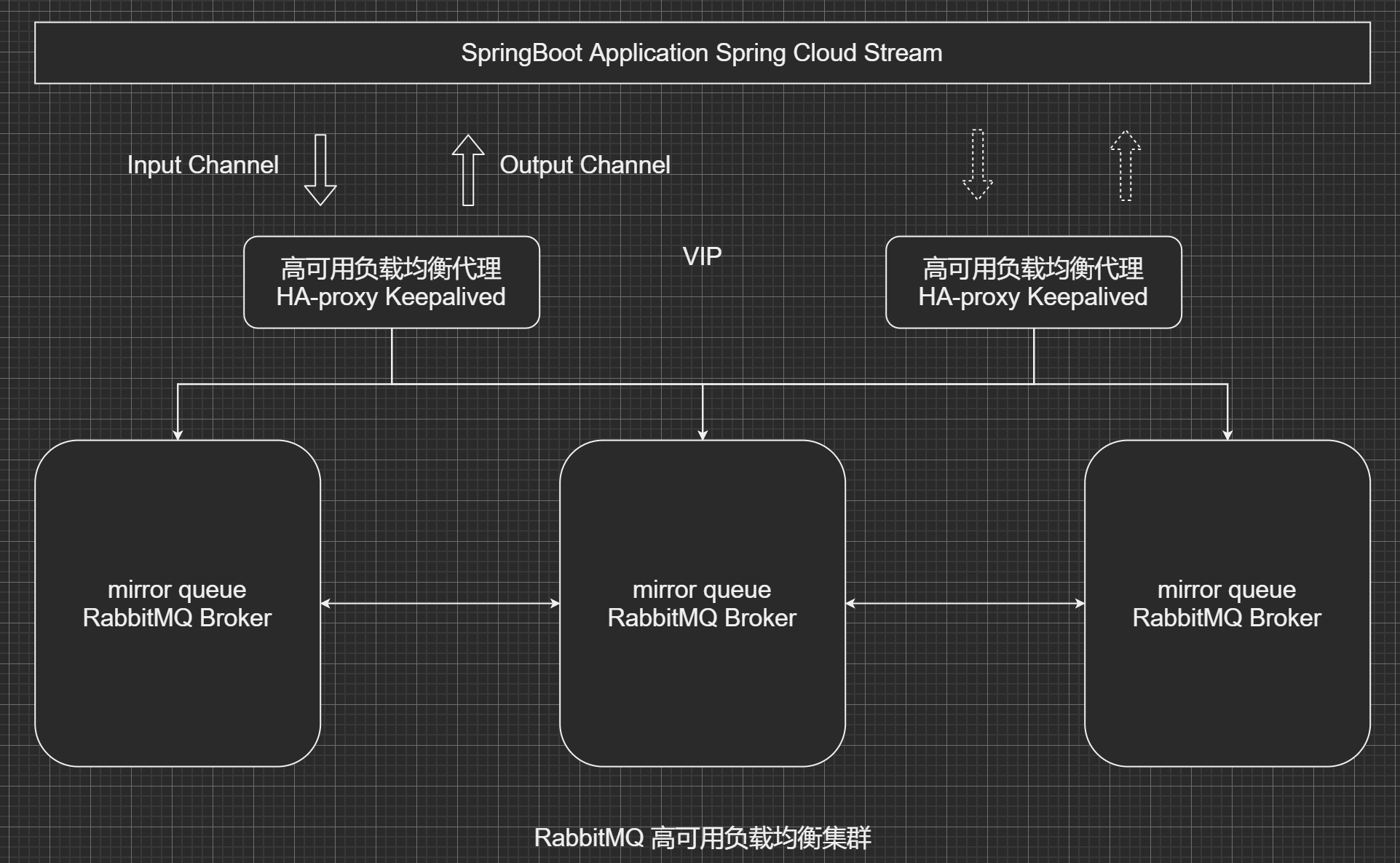
3台 RabbitMQ服务器 构建 broker 集群,允许任意2台服务器故障而服务不受影响,在此基础上,通过Queue HA (queue mirror)实现队列的高可用,在本例中镜像到所有服务器节点(即1个master,2个slave)为保证客户端访问入口地址的唯一性,通过haproxy做4层代理来提供MQ服务,并通过简单的轮询方式来进行负载均衡,设置健康检查来屏蔽故障节点对客户端的影响;使用2台haproxy并且通过keepalived实现客户端访问入口的高可用机制.
最后使用 192.168.123.110 虚拟ip进行访问.
服务器分配
| 服务器IP | hostname | 节点说明 | 端口 | 管控台地址 |
|---|---|---|---|---|
| 192.168.123.26 | desktop-linux | rabbitmq master | 5672 | http://192.168.123.26:15672 |
| 192.168.123.197 | notebook-linux | rabbitmq slave | 5672 | http://192.168.123.197:15672 |
| 192.168.123.128 | linux-128 | rabbitmq slave | 5672 | http://192.168.123.128:15672 |
| 192.168.123.129 | host129 | haproxy + keepalived | 8100 | http://192.168.123.129:8100/rabbitmq-stats |
| 192.168.123.130 | host130 | haproxy + keepalived | 8100 | http://192.168.123.130:8100/rabbitmq-stats |
修改节点计算机的名称
vim /etc/hostname
linux-devlgq.localdomain
# 或者使用以下指令
sysctl kernel.hostname=linux-devlgq.localdomain
修改hosts文件
vim /etc/hosts
192.168.123.26 linux-devlgq
192.168.123.197 devlgq-notebook
192.168.123.128 linux-128
3台服务器都安装好RabbitMQ. 如果在修改hostname之前启动过mq,那么要删除 /var/lib/rabbitmq/mnesia/ 下的内容.
# 文件同步步骤
# 把需要作为master的Cookie文件同步到其余节点
# Cookie 文件位置 /var/lib/rabbitmq/.erlang.cookie
# 把 Cookie 文件权限修改为777,原来是400
chmod 777 /var/lib/rabbitmq/.erlang.cookie
scp /var/lib/rabbitmq/.erlang.cookie [email protected]:/var/lib/rabbitmq/
scp /var/lib/rabbitmq/.erlang.cookie [email protected]:/var/lib/rabbitmq/
# 之后把权限修改回400
chmod 400 /var/lib/rabbitmq/.erlang.cookie
# 先停掉所有的mq 启动集群
rabbitmq-server -detached
# 启动rabbitmq
systemctl start rabbitmq
# 查看状态
rabbitmqctl status
# slave 加入集群
rabbitmqctl stop_app
# 以内存节点的方式加入
rabbitmqctl join_cluster --ram rabbit@linux-devlgq
rabbitmqctl start_app
rabbitmqctl stop
# Error:
# {:inconsistent_cluster, 'Mnesia protocol negotiation failed. Local version: {8,3}. Remote version {8,5}'}
# 这个错误是服务器的 erlang 版本不一致导致的,保持服务器的 erlang 版本一致即可.
# 移除集群中的某个节点
rabbitmqctl forget_cluster_node rabbit@linux-devlgq
# 修改集群的名称,默认是第一个集群的名称
rabbitmqctl set_cluster_name rabbitmq_cluster1
# 查看集群状态
rabbitmqctl cluster_status
# 配置镜像队列
rabbitmqctl set_policy ha-all "^" '{"ha-mode":"all"}'
# 查看镜像队列状态
rabbitmqctl list_queues name pid slave_pids
# 修改节点为 内存节点
rabbitmqctl change_cluster_node_type ram
# 修改节点为 磁盘节点
rabbitmqctl change_cluster_node_type disc
集群配置文件
环境变量配置文件:rabbitmq-env.conf
配置信息配置文件:rabbitmq.config
rabbitmq-env.conf
RABBITMQ_NODENAME=FZTEC-240088 节点名称
RABBITMQ_NODE_IP_ADDRESS=127.0.0.1 监听IP
RABBITMQ_NODE_PORT=5672 监听端口
RABBITMQ_LOG_BASE=/data/rabbitmq/log 日志目录
RABBITMQ_PLUGINS_DIR=/data/rabbitmq/plugins 插件目录
RABBITMQ_MNESIA_BASE=/data/rabbitmq/mnesia 后端存储目录
详细配置:http://www.rabbitmq.com/configure.html#configuration-file
rabbitmq.config
# 设置rabbimq的监听端口,默认为[5672]
tcp_listerners 5672
# 磁盘低水位线,若磁盘容量低于指定值则停止接收数据,默认值为{mem_relative, 1.0},即与内存相关联1:1,也可定制为多少byte.
disk_free_limit 1.0
# 设置内存低水位线,若低于该水位线,则开启流控机制,默认值是0.4,即内存总量的40%.
vm_memory_high_watermark 0.4
# 将部分rabbimq代码用High Performance Erlang compiler编译,可提升性能,该参数是实验性,若出现erlang vm segfaults,应关掉.
hipe_compile false
# 该参数属于rabbimq_management,若为true则进行精细化的统计,但会影响性能
force_fine_statistics true
详细配置:http://www.rabbitmq.com/configure.html
HA-Proxy 安装
HAProxy是一款提供高可用性、负载均衡以及基于TCP和HTTP应用的代理软件,HAProxy是完全免费的、借助HAProxy可以快速并且可靠的提供基于TCP和HTTP应用的代理解决方案.
HAProxy可以支持数以万计的并发连接,并且HAProxy的运行模式使得它可以很简单安全的整合进架构中,同时可以保护web服务器不被暴露到网络上.
安装配置在 192.168.123.129 和 192.168.123.130 .
wget https://github.com/haproxy/haproxy/archive/v2.3.0.tar.gz
mv v2.3.0.tar.gz haproxy_v2.3.0.tar.gz
tar -zxvf haproxy_v2.3.0.tar.gz
cd haproxy-2.3.0
mkdir /usr/local/haproxy
make TARGET=linux-glibc PREFIX=/usr/local/haproxy
make install PREFIX=/usr/local/haproxy
# 创建新用户组和用户
groupadd -r -g 149 haproxy
useradd -g haproxy -r -s /sbin/nologin -u 149 haproxy
# 创建配置文件
mkdir /etc/haproxy
touch /etc/haproxy/haproxy.cfg
haproxy.cfg 配置文件
# logging options
global
log 127.0.0.1 local0 info
maxconn 5120
chroot /usr/local/haproxy
uid 99
gid 99
daemon
quiet
nbproc 20
pidfile /var/run/haproxy.pid
defaults
log global
# 使用4层代理模式,"mode http"为7层代理模式
mode tcp
#if you set mode to tcp,then you nust change tcplog into httplog
option tcplog
option dontlognull
retries 3
option redispatch
maxconn 2000
timeout connect 10s
#客户端空闲超时时间为 3小时 则HA 发起重连机制
timeout client 3h
#服务器端链接超时时间为 3小时 则HA 发起重连机制
timeout server 3h
# front-end IP for consumers and producters
listen rabbitmq_cluster
bind 0.0.0.0:5672
#配置TCP模式
mode tcp
#balance url_param userid
#balance url_param session_id check_post 64
#balance hdr(User-Agent)
#balance hdr(host)
#balance hdr(Host) use_domain_only
#balance rdp-cookie
#balance leastconn
#balance source //ip
#简单的轮询
balance roundrobin
# rabbitmq集群节点配置 #inter 每隔五秒对mq集群做健康检查, 2次正确证明服务器可用,2次失败证明服务器不可用,并且配置主备机制
server linux-devlgq 192.168.123.26:5672 check inter 5000 rise 2 fall 2
server devlgq-notebook 192.168.123.197:5672 check inter 5000 rise 2 fall 2
server linux-128 192.168.123.128:5672 check inter 5000 rise 2 fall 2
# 配置haproxy web监控,查看统计信息
listen stats
bind 192.168.123.129:8100
mode http
option httplog
stats enable
#设置haproxy监控地址为 http://192.168.123.129:8100/rabbitmq-stats
stats uri /rabbitmq-stats
stats auth admin:admin123
# stats refresh 5s
启动 HAProxy
/usr/local/haproxy/sbin/haproxy -f /etc/haproxy/haproxy.cfg
# 访问 http://192.168.123.129:8100/rabbitmq-stats
关闭 HAProxy
killall haproxy
ps -ef | grep haproxy
netstat -tunpl | grep haproxy
ps -ef | grep haproxy | awk '{print $2}' | xargs kill -9
HA-Proxy 集群搭建错误
错误 ERROR CachingConnectionFactory:1576 - Channel shutdown: connection error
使用单机版是没有这个问题的. 如果是使用HAProxy搭建的集群,就可能出现这个问题.
the exact behaviour of tcp keep-alive is determined by the underlying OS/Kernel configuration TCP keepalived数据包的发送,取决于系统内核的配置.
查看服务器中keep_alived_time时间, CentOS默认是7200s,即是2小时.
cat /proc/sys/net/ipv4/tcp_keepalive_time
虽然配置了clitcpka参数,但因为系统发送TCP keepalive数据包的间隔时间过长,远远超过 HAProxy 中的 timeout client 超时时间(默认好像是 2 秒),所以客户端连接每隔 2 秒,就被 HAProxy 断开连接了,然后不断的被重建.
解决方案:
- 修改系统的tcp_keepalive_time配置,间隔时间低于 HAProxy 配置的timeout client超时时间.
- 修改 HAProxy 中的timeout client超时时间,配置大于系统的tcp_keepalive_time间隔时间.
推荐修改 HAproxy 的配置,因为修改服务器的配置,可能会影响其他的服务的运行.
timeout client 3h
timeout server 3h
Keepalived 配置
配置在 192.168.123.129 和 192.168.123.130.
检测haproxy脚本.
#!/bin/bash
COUNT=`ps -C haproxy --no-header | wc -l`
if [ $COUNT -eq 0 ];then
/usr/local/haproxy/sbin/haproxy -f /etc/haproxy/haproxy.cfg
sleep 2
if [ `ps -C haproxy --no-header |wc -l` -eq 0 ];then
killall keepalived
fi
fi
# 执行脚本赋权
chmod +x check_haproxy_alive_or_not.sh
! Configuration File for keepalived
global_defs {
router_id linux-130 #标识节点的字符串,通常为hostname 注意要修改
}
vrrp_script chk_haproxy {
script "/etc/keepalived/check_haproxy_alive_or_not.sh" #执行脚本位置
interval 2 #检测时间间隔
weight -20 #如果条件成立则权重减20
}
vrrp_instance VI_1 {
state MASTER # 主节点为MASTER,备份节点为BACKUP
interface ens33 # 绑定虚拟IP的网络接口(网卡),与本机IP地址所在的网络接口相同
virtual_router_id 10086 # 虚拟路由ID号(主备节点一定要相同)
mcast_src_ip 192.168.123.130 # 本机ip地址 注意要修改
priority 100 #优先级配置(0-254的值)
nopreempt
advert_int 1 # 组播信息发送间隔,俩个节点必须配置一致,默认1s
authentication { # 认证匹配
auth_type PASS
auth_pass lgq2020
}
track_script {
chk_haproxy
}
virtual_ipaddress {
192.168.123.110 # 虚拟ip,可以指定多个 会漂移
}
}
启动 keepalived
systemctl start keepalived
systemctl stop keepalived
systemctl restart keepalived
systemctl status keepalived
RabbitMQ 管理
安装 rabbitmqadmin 管理脚本. 从之前安装好的 rabbitmq_management 插件获取即可.
cd /etc/rabbitmq
wget http://localhost:15672/cli/rabbitmqadmin
chmod +x rabbitmqadmin
# 查看虚拟主机(vhost)下的交换机列表
./rabbitmqadmin -V "/" list exchanges
# 清空队列
./rabbitmqadmin purge queue name=exchange-1.queue-1
# 创建交换机
./rabbitmqadmin -u guest -p guest declare exchange \name=exchange-2 type=fanout
# 获得链接数
./rabbitmqadmin list connections name
# 关闭链接
./rabbitmqadmin close connection name="connect_name"
幂等性概念和业界主流解决方案
幂等性:可以借鉴数据库的乐观锁机制. 比如执行一条更新库存的SQL语句,UPDATE_REPS SET COUNT = COUNT - 1, VERSION = VERSION + 1 WHERE VERSION = 1. 再比如ElasticSearch,每次更新,他的版本号肯定都是递增的. 对于一个操作,无论重复操作多少次,最终的结果都是相同的.
在海量订单产生的业务高峰期,如何避免消息的重复消费问题?
消费端实现幂等,就意味着消息永远不会消费多次,即使收到多条一样的消息.
消费端-幂等性保障
- 唯一ID + 指纹码(业务规则拼接) 机制,利用数据库主键去重.
- select count(1) from t_order where id = 唯一ID + 指纹码
- 优点:实现简答
- 缺点:高并发下有数据库写入的性能瓶颈
- 解决方案:根据ID进行分库分表算法路由,单库的幂等变成多库的幂等,从而做到分压分流.
- 利用Redis原子性去重.
- 是否需要数据落库,如果落库的话,关键解决的问题是数据库和缓存如何做到原子性?
- 如果不进行落库,那么都存储到缓存中,如何设置同步策略?
RabbitMQ Java API使用
生产者 配置文件
spring:
rabbitmq:
addresses: 192.168.123.110:5672
username: guest
password: guest
virtual-host: /
connection-timeout: 15000
# 消息确认模式
publisher-confirm-type: simple
# 设置消息return模式,注意需要和 mandatory 一起使用
publisher-returns: true
template:
mandatory: true
生产者java代码
package org.lgq.producer.component;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.amqp.rabbit.connection.CorrelationData;
import org.springframework.amqp.rabbit.core.RabbitTemplate;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.messaging.Message;
import org.springframework.messaging.MessageHeaders;
import org.springframework.messaging.support.MessageBuilder;
import org.springframework.stereotype.Component;
import java.util.Map;
import java.util.UUID;
/**
* @author DevLGQ
* @version 1.0
*/
@Component
public class RabbitMQSend {
private static final Logger log = LoggerFactory.getLogger(RabbitMQSend.class);
@Autowired
private RabbitTemplate rabbitTemplate;
/**
* <p>确认消息的回调监听接口,用于确认消息是否被 broker 接收到</p>
* <p>CorrelationData: 作为唯一的标识</p>
* <p>ack broker是否落盘成功,就是消息是否到达broker了, true就是成功</p>
* <p>cause 失败的异常信息</p>
*/
static final RabbitTemplate.ConfirmCallback confirmCallback = (correlationData, ack, cause) -> {
log.info("消息ACK: {} correlationData: {}", ack, correlationData);
};
/**
* 对外发送消息的方法
*
* @param message 消息的内容
* @param properties 额外的附加属性
* @throws
*/
public void send(Object message, Map<String, Object> properties) throws Exception {
// 消息头
MessageHeaders headers = new MessageHeaders(properties);
// 消息体
Message<Object> msg = MessageBuilder.createMessage(message, headers);
// 设置消息发送回调监听
this.rabbitTemplate.setConfirmCallback(confirmCallback);
// 作为唯一标识
CorrelationData correlationData = new CorrelationData(UUID.randomUUID().toString());
// 发送消息
this.rabbitTemplate.convertAndSend("exchange-1",
"springboot.rabbit",
msg,
// 消息执行完成之后会调用此函数
message1 -> {
log.info("------ post to do {}", message1.toString());
return message1;
}, correlationData);
}
}
消费者 配置文件
spring:
rabbitmq:
addresses: 192.168.123.110:5672
username: guest
password: guest
virtual-host: /
connection-timeout: 15000
# 消息确认模式
publisher-confirm-type: simple
# 设置消息return模式,注意需要和 mandatory 一起使用
publisher-returns: true
template:
mandatory: true
listener:
simple:
# 表示消费者消费成功之后需要手工签收(ack),默认为auto
acknowledge-mode: manual
# 线程数
concurrency: 5
# 一条条消费
prefetch: 1
max-concurrency: 10
# 支持重连
retry:
enabled: true
# 消息队列配置
mq:
exchange:
name: "exchange-1"
durable: true
type: "topic"
key: "springboot.*"
消费者java代码
package org.lgq.consumer.component;
import com.rabbitmq.client.Channel;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.amqp.rabbit.annotation.*;
import org.springframework.amqp.support.AmqpHeaders;
import org.springframework.messaging.Message;
import org.springframework.stereotype.Component;
/**
* @author DevLGQ
* @version 1.0
*/
@Component
public class RabbitMQReceive {
private static final Logger log = LoggerFactory.getLogger(RabbitMQReceive.class);
//@Value("${mq.exchange.name}")
/**
* 绑定,队列和交换机之间,组合使用
*
* @param message
* @param channel
* @throws
*/
@RabbitListener(
bindings = @QueueBinding(
value = @Queue(value = "queue-1", durable = "true"),
exchange = @Exchange(name = "${mq.exchange.name}", durable = "${mq.exchange.durable}", type = "${mq.exchange.type}"),
key = "${mq.exchange.key}")
)
@RabbitHandler
public void onMessage(Message message, Channel channel) throws Exception{
// 收到消息后进行业务处理
log.info("----------------------");
log.info("消费消息: {}", message.getPayload());
// 配置文件签收配置为手动
// 进行手工的ack操作 如果没有,消息会是 Unacked 状态. 消费端保证,如果没有收到ack的消息,消息不会删除,会再次推送.
// 所以做mq的可靠性投递,一般只做生产端的,因为消费端的mq保证了.
long deliverTag = (long) message.getHeaders().get(AmqpHeaders.DELIVERY_TAG);
channel.basicAck(deliverTag, false);
}
}
博客内容遵循 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 协议