
Kafka高效的原因
Kafka高效的原因
Kafka无论是作为MQ还是存储层,主要两个功能是:作为Producer生产的数据存储到broker,而是Consumer从broker读取数据。所以高效的原因应该从读写两方面考虑。
写数据分析
为了优化写入速度,使用了 顺序写 和 MMFile 技术。
顺序写
一般使用的硬盘是机械结构,每次读写都会寻址->写入,其中寻址是一个”机械动作”,它是最耗时的。所以硬盘最讨厌随机I/O,最喜欢顺序I/O。为了提高读写硬盘的速度,Kafka就是使用顺序I/O。
而Linux对于磁盘的读写优化比较多,包括read-ahead和write-behind,磁盘缓存等。如果在内存中做这些操作,一个是Java对象的内存开销很大,另一个就是随着堆内存数据的增多,Java的GC时间会变长,所以使用磁盘有以下好处:
- 顺序写入磁盘顺序读写速度超过磁盘随机读写。
- 顺序写入JVM的GC效率低,内存占用大,使用磁盘避免这问题。
- 顺序写入系统冷启动后,磁盘依然可用。
一个Topic对应多个Partition。
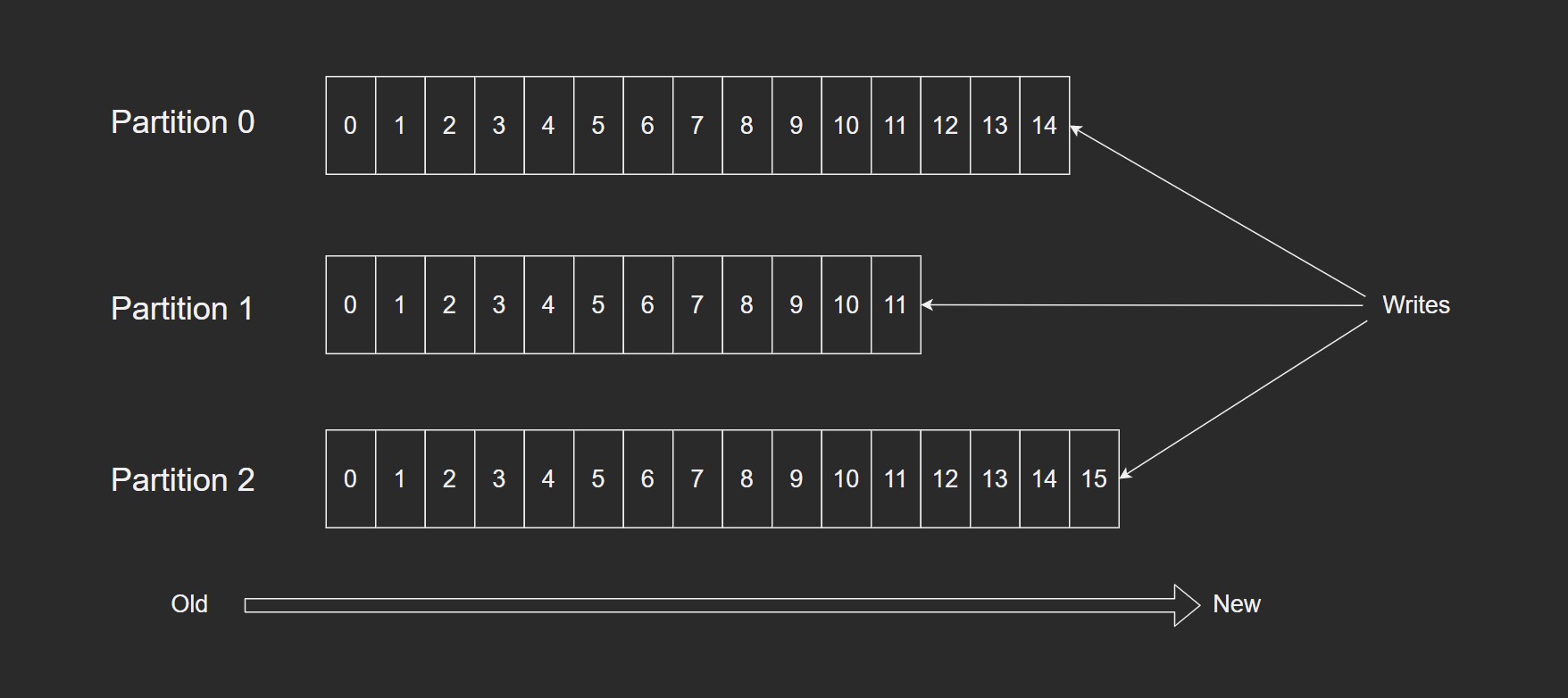
这个方法的缺点是不能删除数据,所以Kafka是不会删除数据的,会把所有数据都保留下来,每个消费者(Consumer)对每个Topic都有一个offset用来表示读到第几条数据。
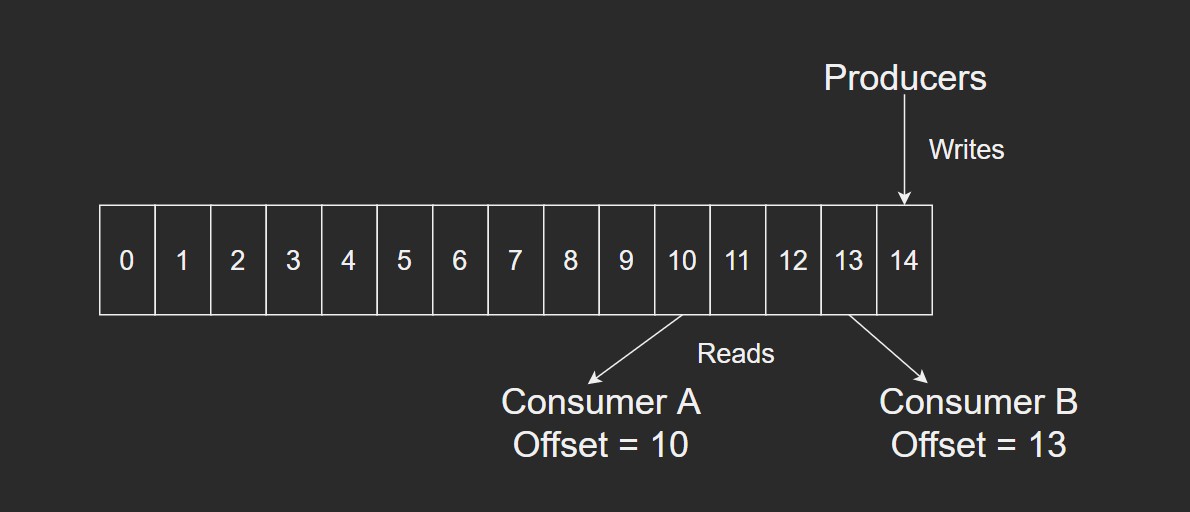
两个消费者
- 顺序写入Consumer1有两个offset分别对应Partition0,Partition1(假设每个Topic一个Partition)。
- 顺序写入Consumer2有一个offset对应Partition2。
这个offset是由客户端SDK负责保存的,Kafka的Broker是不负责的;一般情况下,SDK会把这个保存在Zookeeper中,所以需要给Consumer提供Zookeeper的地址。
如果不删除数据,磁盘会满的,所以Kafka提供了两种策略来删除数据:
- 基于时间。
- 基于
partition的大小。
具体看配置文档。
Memory Mapped Files
即使是顺序写入,磁盘的速度还是追不上内存的,所以Kafka的数据并不是实时写入磁盘的,而是利用了OS分页存储来利用内存提高IO效率。
MMFile也被翻译成 内存映射文件,在64位系统一般可以表示20g数据,原理是利用OS的Page来实现文件到物理内存的直接映射。
通过MMFile可以获得很大的IO提升,省去了用户空间到内核空间复制的开销。
但也有一个明显的缺点,不可靠。写到MMFile中的数据并没有被真正地写到磁盘,操作系统会在程序主动调用flush的时候才会把数据写到磁盘中。
Kafka提供了参数producer.type来控制是不是主动flush,如果Kafka写入到MMFile之后就立即flush然后返回给Producer就叫做同步(sync);如果是写入MMFile之后立即返回,Producer不调用flush叫做异步(async)。
读数据分析
零拷贝
基于sendfile实现Zero Copy
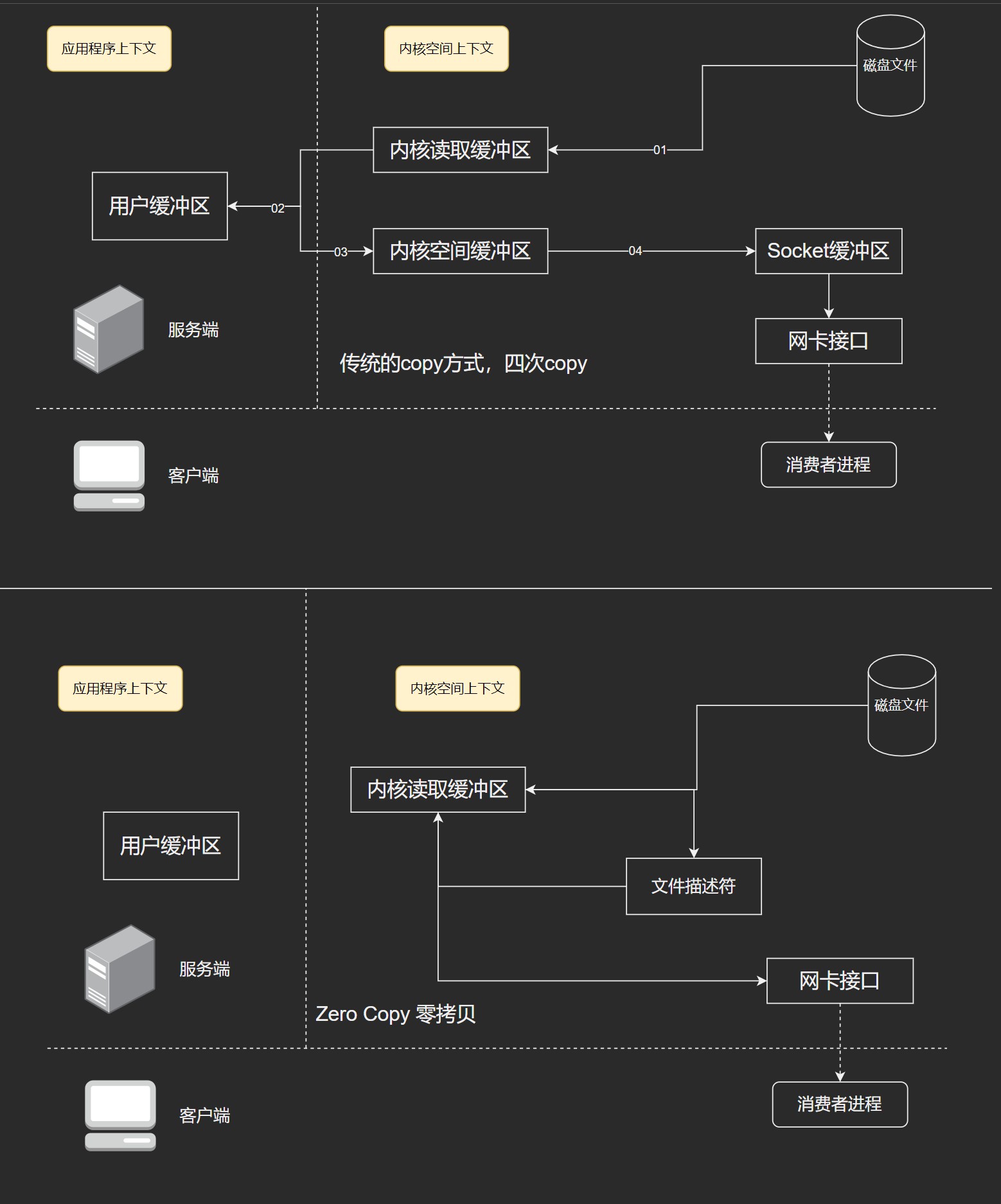
传统模式下,对一个文件进行传输时
- 调用read函数,文件数据被copy到内核缓冲区
- read函数返回,文件数据从内核缓冲区copy到用户缓冲区
- write函数调用,将文件从用户缓冲区copy到内核与socket相关的缓冲区
- 数据从socket缓冲区copy到相关协议引擎
设备 -> 内核buf -> 用户buf -> socket相关缓冲区 -> 协议引擎
而sendfile系统调用提供了减少copy的方式,提升了传输性能的方法。
在内核2.1中,引入了sendfile调用,简化了网络上和两个本地文件之间的数据传输。大致流程如下:
- sendfile系统调用,文件数据copy至内核缓冲区
- 再从内核缓冲区copy到内核中socket相关的缓冲区
- 最后socket相关缓冲区copy到协议引擎
相较传统read/write方式,2.1版本内核引进的sendfile已经减少了内核缓冲区到用户缓冲区,再由用户缓冲区到socket相关缓冲区的文件copy,而在内核版本2.4之后,文件描述符结果被改变,sendfile实现了更简单的方式,再次减少了一次copy操作。
在Apache、Nginx、lighttpd等web服务器当中,都有一项sendfile相关的配置,使用sendfile可以大幅提升文件传输性能。
Kafka把所有的消息都存放在一个一个的文件中,当Consumer需要数据的时候Kafka直接把文件发送给消费者,配合MMFile作为文件读写方式,直接把它传给sendfile。
批量压缩
在很多情况下,系统的瓶颈不是CPU或磁盘,而是网络IO。对于需要在广域网上数据中心之间发送消息的数据流水线更是如此。进行数据压缩会消耗少量的CPU资源,不过对于Kafka来说,网络IO应该更加重要。
如果每个消息都压缩,但是压缩率相对很低,所以Kafka使用了批量压缩,即将多个消息一起压缩而不是单个消息压缩。
Kafka允许使用递归的消息集合,批量的消息可以通过压缩的形式传输并且在日志中也可以保持压缩格式,直到被消费者解压缩。
Kafka支持多种压缩协议,包括Gzip和Snappy压缩协议。
应用场景
- 消息队列。比起大多数的消息系统,Kafka有更好的吞吐量,内置的分区,冗余以及容错性,是一个很好的大规模消息处理应用的解决方案。消息系统一般吞吐量相对较低,但是需要更小的端到端延时,并常常依赖于Kafka提供的强大的持久性保障。在这个领域,Kafka足以媲美传统消息系统,如ActiveMQ或RabbitMQ。
- 日志收集。日志收集开源产品有很多,包括Scribe、Apache Flume。很多人使用Kafka代替日志聚合(log aggregation)。日志聚合一般来说是从服务器上收集日志文件,然后放到一个集中的位置(文件服务器或HDFS)进行处理。然而Kafka忽略掉文件的细节,将其更清晰地抽象成一个个日志或事件的消息流。这就让Kafka处理过程延迟更低,更容易支持多数据源和分布式数据处理。比起以日志为中心的系统比如Scribe或者Flume来说,Kafka提供同样高效的性能和因为复制导致的更高的耐用性保证,以及更低的端到端延迟。
博客内容遵循 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 协议
本文永久链接是:https://blog.lgq51233.xyz/2020/09/30/Kafka%E9%AB%98%E6%95%88%E7%9A%84%E5%8E%9F%E5%9B%A0/