
MySQL索引
MySQL 索引
每一个索引都是一个 B+Tree 的结构, 是一个有序的结构.
- B+Tree: 所有叶子节点的高度不会超过1. 内容都存储在叶子节点. 叶子节点之间还可以使用指针连接, 适合等值和范围查询.
- Hash. 等值查询的效率非常高, 但是范围查询不行.
索引的分类
- 聚簇索引, 密集索引. 行数据和索引节点放在一起. 因为和数据在一起, 所以只有一个.
- 非聚簇索引, 稀疏索引. 索引存储的是数据行的指针, 所以查询的话需要二级查询.
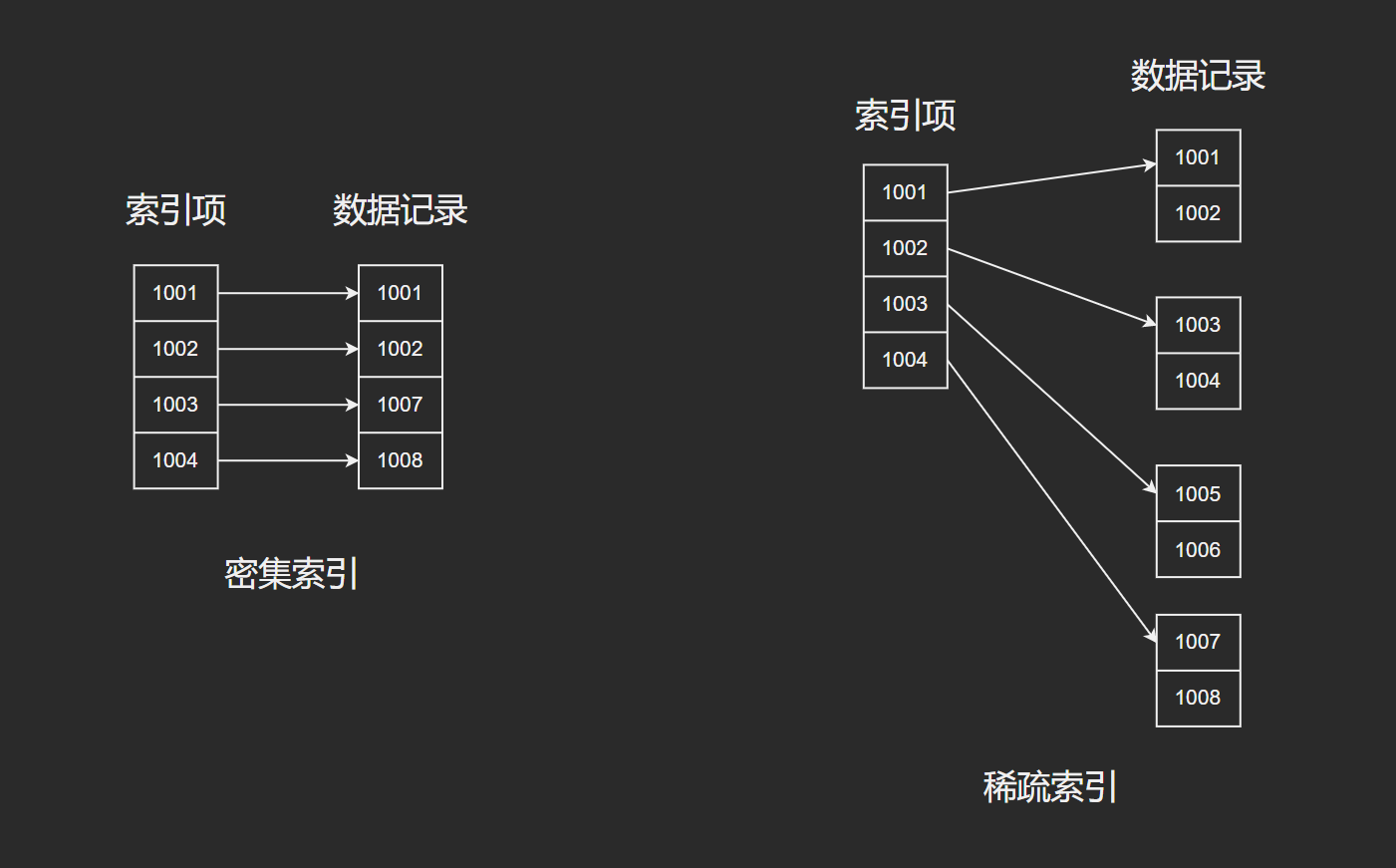
MySQL有主流两种存储引擎:MyISAM 和 InnoDB。MyISAM 主键索引, 唯一键索引 或者 普通索引, 都是稀疏索引,而 InnoDB 中:
- 若一个主键被定义, 该主键则作为密集索引.
- 若没有主键被定义, 该表的第一个唯一非空索引则作为密集索引.
- 若不满足以上条件,
InnoDB内部会生成一个隐藏主键(密集索引), 是一个6字节的列, 该列的值会随数据插入而自增, 就是说InnoDB必须要有主键, 而该主键必须作为唯一的密集索引. - 非主键索引存储相关键位和其对应的主键值, 没有存储行数据的物理地址, 而是存储该行的主键值, 这样会包含两次查找. 一次是查找次级索引, 然后再查找主键.
-- 创建一个 MyISAM 引擎的数据库
create table `shop_info_small`(
`shop_id` int(2) not null auto_increment,
`shop_name` varchar(20) default null,
`person_id` int(2) default null,
`shop_profile` varchar(50) default null,
primary key (`shop_id`),
unique key `shop_name` (`shop_name`)
)engine=MyISAM default charset=utf8;
-- 创建一个 InnoDB 引擎的数据库
create table `person_info_large`(
`id` int(2) not null auto_increment,
`account` varchar(20) default null,
`name` varchar(20) default null,
`area` varchar(20) default null,
`title` varchar(20) default null,
`motto` varchar(50) default null,
primary key (`id`),
unique key `account` (`account`),
key `index_area_title` (`area`, `title`) comment '联合索引'
)engine=InnoDB auto_increment=2312991 default charset=utf8;
进入查看mysql的数据目录的数据
cd /var/lib/mysql
ll
[linux-devlgq test_demo]# ll
总用量 156
drwx------ 2 mysql mysql 4096 2月 7 22:36 ./
drwx------ 9 mysql mysql 4096 2月 7 22:26 ../
-rw-rw---- 1 mysql mysql 67 2月 7 22:26 db.opt
-rw-rw---- 1 mysql mysql 2410 2月 7 22:36 person_info_large.frm
-rw-rw---- 1 mysql mysql 131072 2月 7 22:36 person_info_large.ibd
-rw-rw---- 1 mysql mysql 1716 2月 7 22:27 shop_info_small.frm
-rw-rw---- 1 mysql mysql 0 2月 7 22:27 shop_info_small.MYD
-rw-rw---- 1 mysql mysql 1024 2月 7 22:27 shop_info_small.MYI
可以看到shop_info_small(MyISAM)数据和索引是分开的,而person_info_large(Innodb)索引和数据是一起的。
主键和唯一键区别:
- 当一个属性声明为主键时, 它将不接受
NULL值, 而当声明为Unique的属性时, 它可以接受一个NULL值. - 表中只能有一个主键, 但可以有多个唯一键.
- 定义主键时自动创建密集索引. 相反,
Unique键生成稀疏索引.
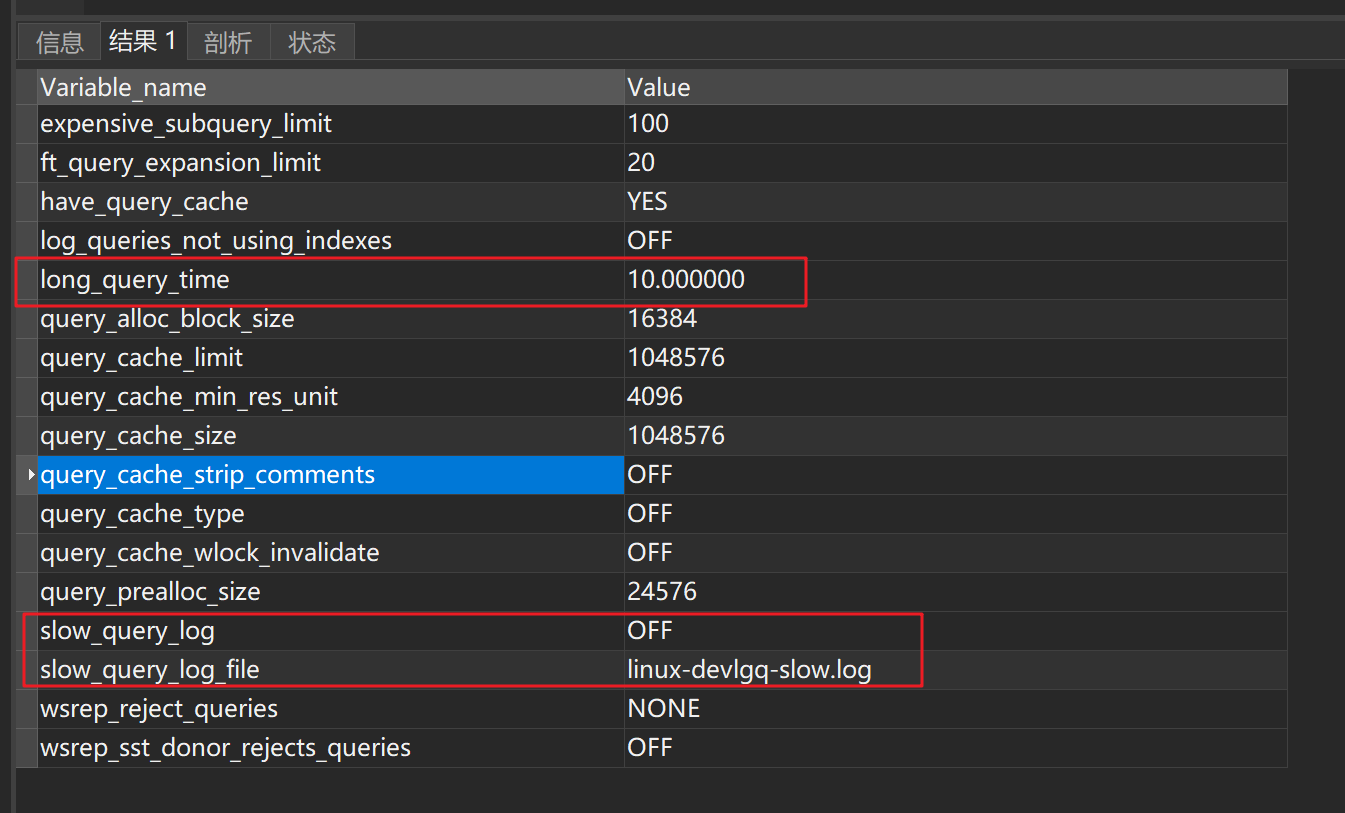
慢日志
打开慢日志定位查询sql
-- 查看系统变量
show variables like '%query%';
-- 查询慢查询 注意, 如果是临时修改的话, 该值在mysql重启后会清零
show status like '%slow_queries%'
-- 打开慢日志 临时修改, 要永久修改的话修改配置文件
-- 注意要重新连接才能查询到修改后的数据
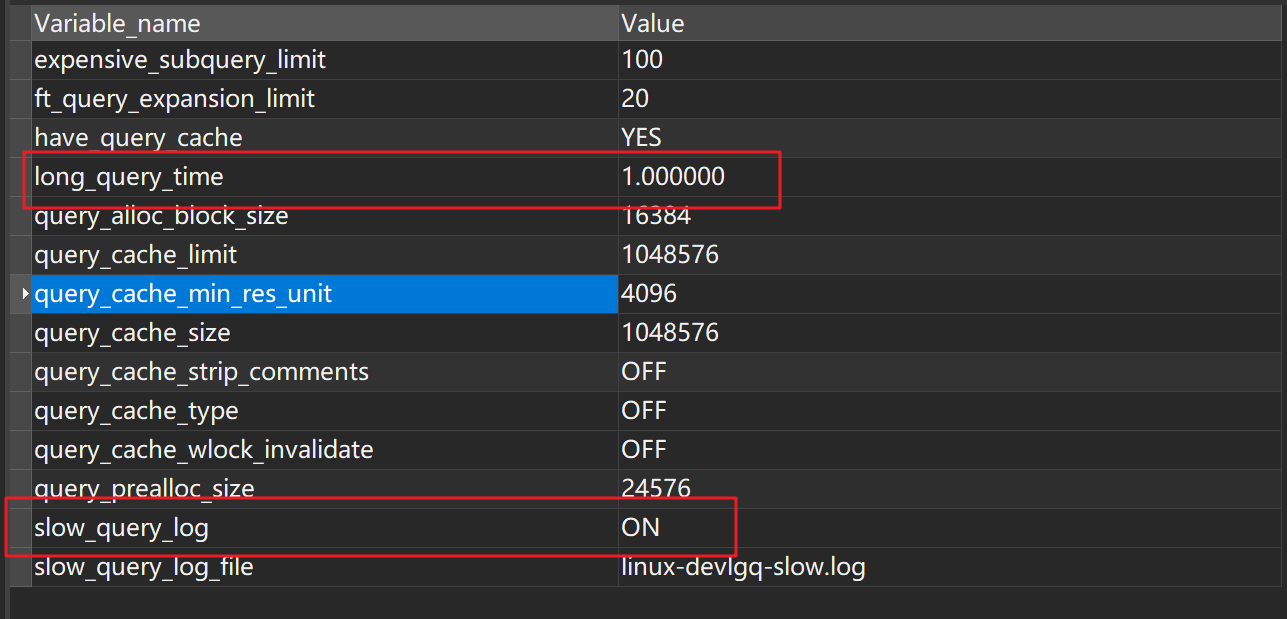
set global slow_query_log = on;
set global long_query_time = 1.0;
场景模拟: 构建1亿条数据.项目位置: JavaInterview 下的 db 包下的 GenExecutor 文件.
# 查询 太慢了... 59s
select * from huge.post where user_id = 6000614;
# 查看mysql慢查询日志
more /var/lib/mysql/devlgq-linux-slow.log
/usr/bin/mysqld, Version: 8.0.24 (Source distribution). started with:
Tcp port: 3306 Unix socket: /run/mysqld/mysqld.sock
Time Id Command Argument
# Time: 2021-05-19T03:41:26.711135Z
# User@Host: root[root] @ DevLGQ [192.168.31.124] Id: 77
# Query_time: 59.655983 Lock_time: 0.000138 Rows_sent: 5 Rows_examined: 100000000
SET timestamp=1621395627;
/* ApplicationName=DataGrip 2021.1 */ select * from huge.post where user_id = 6000614;
explain执行计划
explain执行计划分析sql语句。
explain select * from huge.post where user_id = 6000614;

- type: mysql找到需要数据行的方式
system: 仅一行, const的特例const: 主键 or 唯一键的 常量等值查询(一次索引就找到了,只匹配一行数据)eq_ref: 主键 or 唯一键 的扫描或关联查询ref: 普通非唯一索引的 常量等值查询,因为是非唯一索引,所以可能多于1行数据被扫描range: 索引的范围查询, 需要遍历.index: 索引全查询, 遍历索引.all: 遍历全表查询
- key_len : MySQL 实际使用的索引长度. 如果索引是 NULL, 则长度为 NULL. 如果不是 NULL, 则为使用索引的长度.
- 定长字段: int 4字节, date 3字节, char(n) n个字符(一个字符大小看字符编码集)
- 变长字段: varchar(n), 占用n个字符+2个字节.
- 不同的字符集. utf-8编码的, 一个字符3个字节, UTF8MB4的话是4个字节
- 对于所有所以字段, 如果允许为 NULL, 则还需要1个字节.
- extra: 以下2项意味着
MYSQL根本没有使用索引, 效率会受重大影响. 应尽可能对此进行优化.- Using filesort: 表示MySQL会对结果使用一个外部索引排序, 而不是从表里按索引次序读到相关内容. 可能在内存或磁盘上进行排序. MySQL中无法利用索引完成的排序操作称为文件排序.
- Using temporary: 表示MySQL在对查询结果排序时使用临时表. 常见于排序
order by和 分组查询group by.
-- 使用原本就是索引的字段
explain SELECT account FROM `person_info_large` ORDER BY `account` desc;
-- 加索引 属于DDL, 是操作表结构的. DML才会.
alter table `post` add index idx_user_id(`idx_user_id`);
-- 走的是密集索引还是稀疏索引?
explain SELECT COUNT(id) FROM `post`;
-- 强制走主键索引 也可以使用这个来测试走哪个索引比较好
explain SELECT COUNT(id) FROM `post` force index(primary);
这个结果是由查询优化器决定的 – 尽可能使用索引, 并使用最严格的索引来消除尽可能多的数据行.
联合索引的最左匹配原则
由多列组成的索引, 也叫做聚合索引或者联合索引.
什么是最左匹配原则? 假设2列A, B, 将A和B设置为联合索引, 顺序是AB. 在where xx=A and xx=B时就会走这个索引, 如果where xx=A也会走这个索引, 但是where xx=B的时候是不走这个索引的.
-- 验证上述说明
explain select * from `person_info_large` where area='' and title=''; -- index_area_title
explain select * from `person_info_large` where area=''; -- index_area_title
explain select * from `person_info_large` where title=''; -- ALL
- 最左前缀匹配原则,
mysql会一直向右匹配直到遇到范围查询(>, <, between, like)就停止匹配, 比如a=3 and b=4 and c > 5 and d = 6, 如果建立(a,b,c,d)顺序的索引, d是用不到索引的, 如果建立(a,b,d,c)索引则会都可以用到, a,b,d的顺序可以任意调整. =和in可以乱序, 比如a=1 and b=2 and c=3建立(a,b,c)索引可以任意顺序,mysql的查询优化器会帮优化索引成可以识别的形式.
MySQL创建联合索引的规则, 首先会对联合索引最左边的字段的数据进行排序, 在第一个字段排序的基础上, 再对后面的第二个索引字段进行排序, 就类似于实现了order by field1, order by field2这样的排序规则. 所以第一个字段肯定是有序的, 而第二个字段则可能无序了, 使用第二个进行条件判定是找不到索引的.
下图, 以 col3 col2 col1 的顺序建立联合索引. MySQL 就会利用 col3 建立B+Tree. 根据 col3 找到 col2, 然后再继续查找下去, 最终定位到要查找的数据. 所以单单只有col2是走不了B+Tree索引的.
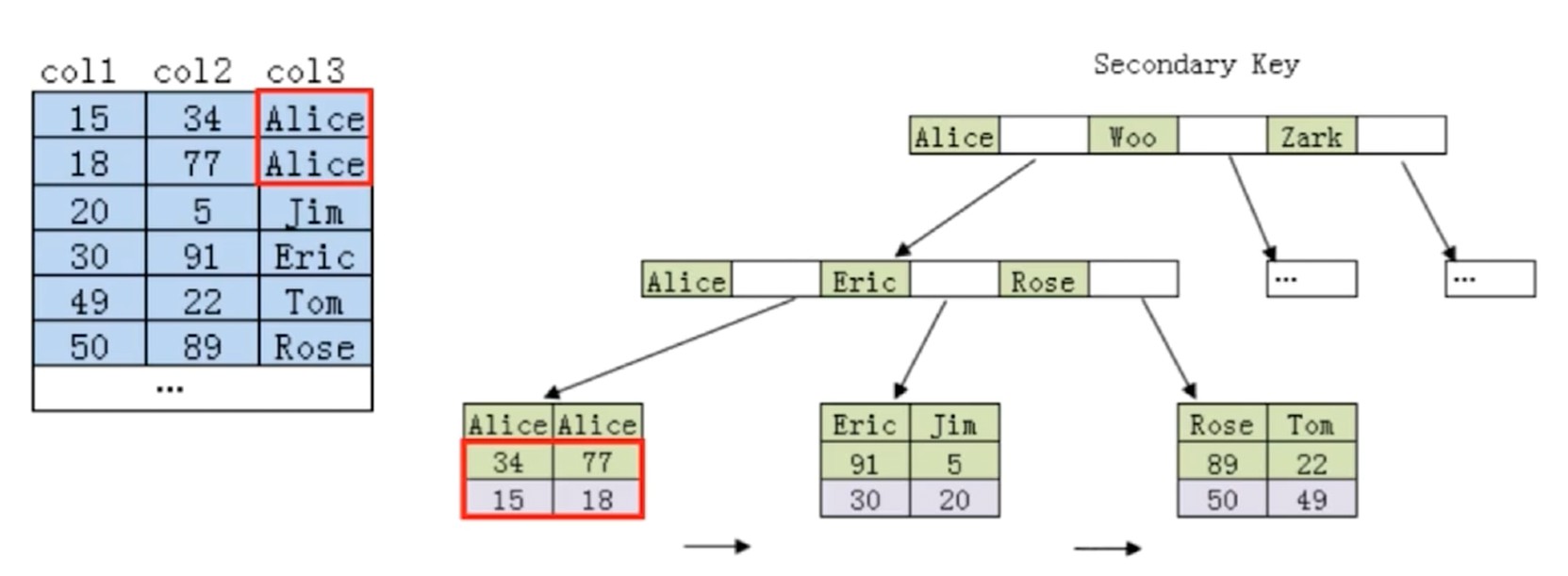
验证例子
创建表staff表. 使用该表创建一个联合索引, 相当于建立了三个索引 id, id_name, id_name_age.
-- 使用存储过程生成一段模拟数据
drop procedure if exists batchStaffData;
DELIMITER $$
create procedure batchStaffData()
begin
declare x int;
declare y int;
set x = 0;
drop table if exists `staff`;
create table `staff`
(
`id` int(10) auto_increment default null,
`name` char(10) default null,
`age` int(10) default null,
key `id_name_age_index` (`id`, `name`, `age`) -- 10 + 3*10 + 10 = 50
) engine = InnoDB
default charset = UTF8MB4;
loop_label:
loop
-- 批量插入100条数据
if x = 100 then
leave loop_label;
end if;
set x = x + 1;
set y = floor(rand() * 100);
insert into staff(name, age) values (concat('lgq', x), y);
end loop;
end $$
DELIMITER ;
call batchStaffData();
全值匹配查询时
explain select * from `staff` where id = 5 and age = 5 and name = 'lgq80';

explain select * from `staff` where id = 5 and name = 'lgq80' and age = 5 ;

explain select * from `staff` where name = 'lgq80' and age = 5 and id = 5;

上边结果可知, 无论使用怎样的顺序, 查询都使用到联合索引. 因为MySQL的查询优化器 explain, 不需要 sql 中的字段顺序和定义的字段顺序一致.
匹配最左边列时
explain select * from `staff` where id = 5;

上面的索引遵循最左匹配原则. 使用了联合索引, 且是使用了联合索引的(id)索引.
explain select * from `staff` where id = 5 and name = 'lgq80';

因为id到name是从左到右匹配, 这两个字段的值都是有序的, 所以符合最左匹配原则.
如果不依次匹配
explain select * from `staff` where id = 5 and age = '5';

从key知道, 虽然使用了联合索引, 但是从 key_len 知道只使用了联合索引的(id)索引. 因为联合索引是按照id字段创建的, 但 age 相对于 id 是无序的, 所以只能使用索引中的id索引.
explain select * from `staff` where name='lgq80'

虽然使用了联合索引, 但是type的方式是index, 是对整个索引进行了扫描, 因为没有从 id 开始匹配, 而 name 单独来说是无序的, 所以没有遵循最左匹配原则. index是从索引字段一个一个查找, 直到找到符合的某个索引, 与 ALL 不同, index是对所有索引树扫描, 而 ALL 是对磁盘数据进行扫描.
匹配范围值时
explain select * from `staff` where id > 1 and id < 3;

在匹配过程中遇到<>=号, 就会停止匹配, 但是 id 本来就是有序的, 所以可以使用联合索引中的的id索引.
explain select * from `staff` where id > 3 and age > 20 and age < 50;

不遵循最左匹配原则, 且在 id > 3 的范围中, age 无序的, 只使用了联合索引的id索引.
explain select * from `staff` where age > 20 and age < 80;

不遵循最左匹配原则, 而 age 又是无序的, 所以全索引扫描.
索引的优化
五个点
- 经常被查询的, 区分度高的列做索引(区分度控制在20%~40%, 越高, 走索引的效率越高)
- 联合索引中的最左匹配原则. 注意
or查询, 可以使用union拆分成2句sql语句. 遇到范围查询就会停止匹配. 模糊查询一定要使用前缀匹配查询, 中间或后缀都会导致索引失效. - 避免回盘排序. 使用没有索引的字段进行排序, 会产生一个
fileSort的内存排序, 如果量大, 还可能会使用磁盘. 因此order by的字段一般会建立一个联合索引, 在过滤之后就可以使用已经排序的内容. 因为B+Tree本身就是一个有序的结构. 这样就可以避免内存或磁盘级别的排序了. - 覆盖索引. 意思就是在索引上就能找到需要的数据, 不需要走二级索引.
- 小表驱动大表.
in join,left join,right join. 做对应的子查询的时候, 一定要使得子查询的内容可以过滤掉大部分的行记录. 然后再将对应的数据带到主查询中.join最好不要超3层.
优化到至少 range 范围。
索引的维护
删除重复和冗余的索引. 重复索引会造成资源的浪费.
primary key(id), unique key(id), index(id)
主键索引 唯一索引 单列索引
主键本来就是一个非空的唯一索引, 就没有必要为id创建唯一索引了. 更没有必要创建二级索引.
冗余索引: index(a), index(a,b)
# 安装相关工具
pacman -S perl-dbi
pacman -S perl-dbd-mysql
pacman -S percona-toolkit
pt-duplicate-key-checker --host=127.0.0.1 --user=root --ask-pass --databases=sakila --tables=film
show indexes from film;
查找未被使用过的索引
select OBJECT_SCHEMA, OBJECT_NAME, INDEX_NAME, b.`TABLE_ROWS`
from performance_schema.table_io_waits_summary_by_index_usage a
join information_schema.tables b on
a.`OBJECT_SCHEMA` = b.`TABLE_SCHEMA` and
a.`OBJECT_NAME` = b.`TABLE_NAME`
where index_name is not null
and count_star = 0
order by OBJECT_SCHEMA, OBJECT_NAME;
更新索引统计信息和减少索引碎片。
analyze table table_name;
-- 使用不当会导致锁表
optimize table table_name;

博客内容遵循 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 协议
本文永久链接是:https://blog.lgq51233.xyz/2020/09/28/MySQL%E7%B4%A2%E5%BC%95/