
Java的阻塞队列
阻塞队列
生产者/消费者 问题
缓冲区通常是有界限的(有大小限制), 也称作 有限缓冲区 问题(bounded-buffer problem). 但是随着时代发展, 缓冲区开始支持自动扩容, 尤其是链表这种跳跃数据结构, 允许节点在内存分配上不连续, 扩容成本非常低, 因此也会使用无界缓冲区(unbounded buffer).

生产者/消费者问题: 一个经典的多处理问题(multi-processing). 生产者产生数据, 消费者消费数据. 中间用一个有界限的缓冲区连接.
int itemCount = 0; // 缓冲区的元素个数
// 生产者
void producer()
{
while (true)
{
if (itemCount == BUFFER_SIZE) // 缓冲区满, 生产者休眠
sleep();
item = produceItem(); // 生产
putItemIntoBuffer(item);
itemCount = itemCount + 1;
if (itemCount == 1) // 刚开始生产, 唤醒消费者
wakeup(consumer);
}
}
// 消费者
void consumer()
{
while (true)
{
if (itemCount == 0) // 如果没有元素消费了, 消费者休眠
sleep();
item = removeItemFromBuffer(); // 取出元素
itemCount = itemCount - 1;
if (itemCount == BUFFER_SIZE - 1) // 队列没有满, 唤醒生产者生产
wakeup(producer);
consumeItem(item); // 消费元素
}
}
死锁问题
生产者等待消费者唤醒, 消费者等待生产者唤醒.
假设缓冲区大小是 100, 当itemCount==100 时, 生产者本来要休眠. 但是如果sleep执行前触发了线程切换, 消费者开始执行. 消费者从缓冲区取出元素, 然后尝试唤醒生产者. 生产者线程收到唤醒信号, 醒来, 然后执行下一句sleep 进入休眠. 消费者继续执行, 当把缓冲区全部清空, 也陷入休眠. 这样, 就构成了死锁.
- 消费者
sleep()前(itemCount == 0), 中断, 切换线程. - 生产者执行并填满队列
- 生产者唤醒消费者
- 消费者执行
sleep()
解决方案
- 对
producer/consumer方法上锁, 这个两个方法就是互斥了. 但是锁范围太大了. - 锁一部分, 锁
itemCount判断和sleep,wakeup操作. 但是程序复杂. Semaphore. 信号量.Condition. 条件变量.
用Semaphore来解决这个问题. Semaphore提供了一对原子操作up down . 生产过程中将**空闲数(emptyCount)减1, 然后将填充数(fillCount)**加1. 消费过程将fillCount减1, 将emptyCount加1. 如果缓冲区满了, emptyCount=1 , 这个时候down操作会导致生产者休眠. 如果缓冲区空了, fillCount=0, down操作会导致消费者休眠.
int fillCount = 0; // items produced 填充数 生产数
int emptyCount = BUFFER_SIZE; // remaining space 空闲数 消费数
void producer()
{
while (true)
{
item = produceItem();
down(emptyCount); // 空闲数-1
putItemIntoBuffer(item);
up(fillCount); // 填充数+1
}
}
void consumer()
{
while (true)
{
down(fillCount); // 填充数-1
item = removeItemFromBuffer();
up(emptyCount); // 空闲数+1
consumeItem(item);
}
}
生产者空位-1, 满位+1, 消费者相反. 解决了程序复杂的问题.
上面操作up和down 操作都是基于CAS的原子操作, up 和down 之间允许多个线程同时进入. 只要fillCount 或者emptyCount 不为0. removeItemFromBuffer和putItemIntoBuffer 可能需要单独上锁, 保证互斥.
生产者/消费者 用途
Web服务.
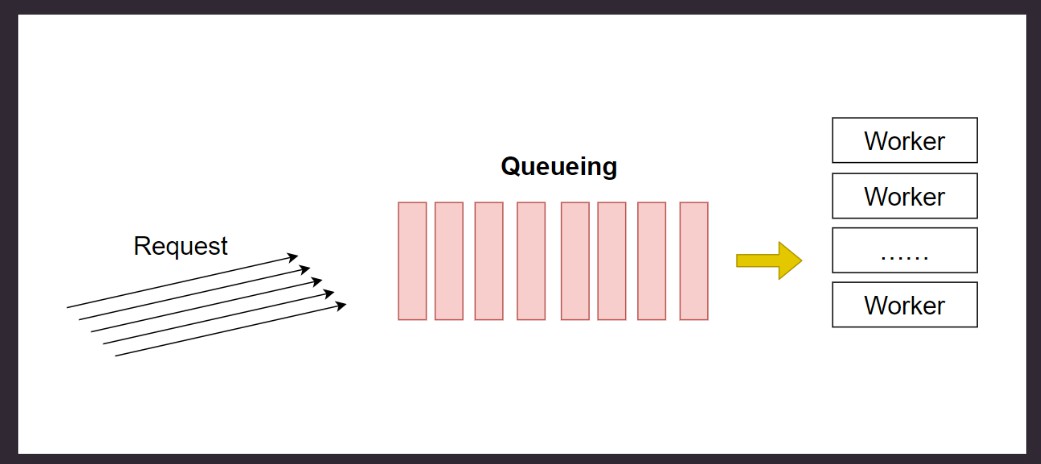
多生产者, 多消费者.
**入队(enqueue)和出队(dequeue)**需要考虑竞争条件.
消息队列.
单播(1:1).
广播(1:n).
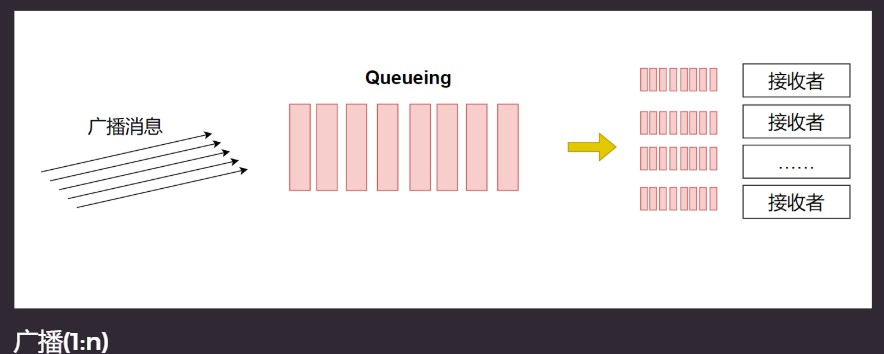
- 缓存所有消息
- 为每个接入消费者创建一套指针(而不是拷贝一份)
- 生产者消费者模型的改造变种
Java中7种阻塞队列实现
Java 提供了 7 种实现, 都是线程安全的.
- ArrayBlockingQueue
- LinkedBlockingQueue
- LinkedBlockingDeque
- PriorityBlockingQueue
- DelayQueue
- LinkedTransferQueue
- SynchronousQueue
三类方法
- 抛异常
- add/remove
- 非阻塞
- offer/poll, 满了返回null表示失败, 如果空了继续poll会失败.
- 阻塞
- put/take. 队列满了put会阻塞; 队列空了take会阻塞.
七种队列详解:
ArrayBlockingQueue: 一个由数组结构组成的有界阻塞队列。LinkedBlockingQueue: 一个由链表结构组成的有界/无界阻塞队列。LinkedBlockingDeque: 一个由链表结构组成的双端阻塞队列。PriorityBlockingQueue: 一个支持优先级排序的无界阻塞队列,队列的元素要具备可比性。线程安全的。DelayQueue: 一个支持延迟获取元素的无界阻塞队列,需要实现延迟接口。LinkedTransferQueue: 一个由链表结构组成的无界阻塞队列,比LinkedBlockingQueue性能高,是无锁操作。SynchronousQueue: 仅允许容纳一个元素的阻塞队列(Match算法)。
阻塞队列接口源码注释
public interface BlockingQueue<E> extends Queue<E> {
// 队尾添加元素 添加失败会抛出异常 IllegalStateException
boolean add(E e);
// 队尾添加元素 添加失败会返回 false
boolean offer(E e);
// 队尾添加元素, 如果满了, 等待指定的时间, 如果还是失败就返回 false
boolean offer(E e, long timeout, TimeUnit unit) throws InterruptedException;
// 往队尾部添加元素 如果满了, 阻塞当前线程, 直到能够添加成功为止
void put(E e) throws InterruptedException;
// 从队列头部取出元素 如果为空, 阻塞等待有元素为止
E take() throws InterruptedException;
// 尝试从队列头部拉取元素, 如果为空, 则最多等待指定时间
E poll(long timeout, TimeUnit unit) throws InterruptedException;
// 获取当前队列剩余可存储元素的数量
int remainingCapacity();
// 从队列中移除指定的对象, 会抛出异常
boolean remove(Object o);
// 判断队列中是否存在某个对象
boolean contains(Object o);
// 将队列中指定的元素转移到集合中
int drainTo(Collection<? super E> c);
int drainTo(Collection<? super E> c, int maxElements);
}
线程安全问题
只考虑单线程. 要处理竞争条件(锁, 同步器等).
BlockingQueue: queue.take() 不需要考虑竞争条件. 心智负担低.
Java中线程安全的数据结构
java.util.concurrent(J.U.C)下的数据结构(ArrayList,HashMap等不是线程安全的)ThreadLocal- 自己实现(上锁, 同步器, 阻塞队列, 无锁编程)
BlockingQueue应用场景
Web 服务器
多生产者+多消费者模型.
- 队列满了就拒绝服务
- 队列空了就休眠
Worker
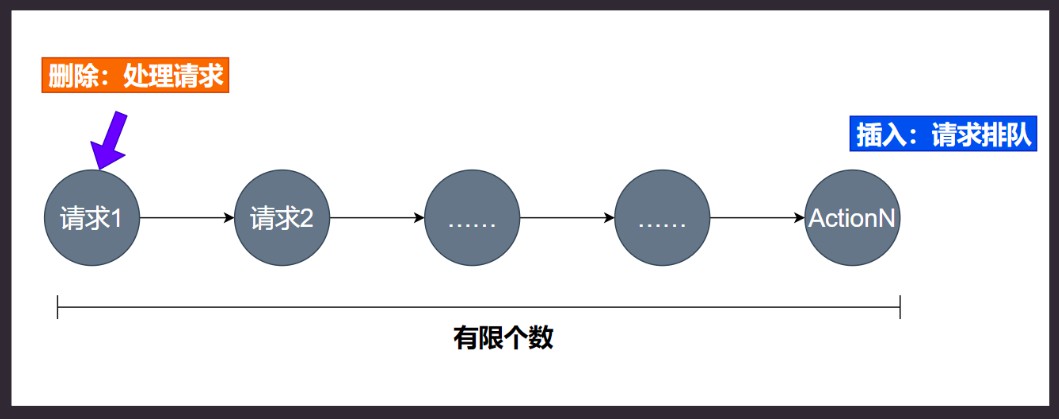
ArrayBlockingQueue 与 ListedBlockingQueue 区别。
- 扩容
List更容易。 Array扩容成本更高。- 数组索引成本低, 查询数组是
O(1)的时间复杂度, 而链表要O(n)的操作。
如果没有需要直接索引元素的需求, 可以考虑用List版本性能更好。
Undo
撤销功能.
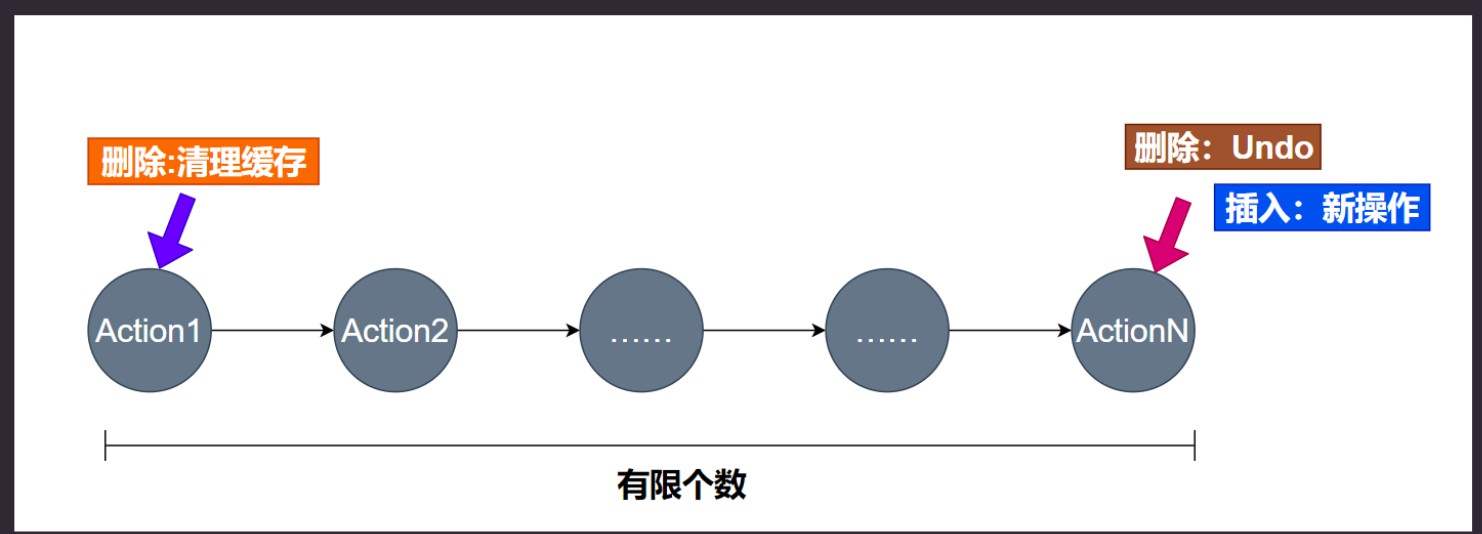
假设一个文本编辑器把所有用户的行为(Action)存入一个队列。那么每次用户发生某个行为, 就需要入队. 队列通常设计成有界的, 比如最多只帮用户存10000个操作历史. 上图中新操作从右边入队得到记录, 超出足够数目(10000)后, 操作从左边删除. 那么, 当需要实现undo功能的时候, 实际上要从右边删除操作. undo是undo最近的操作, 这个时候就需要Deque(双端队列)。
需要双端队列 – LinkedBlockingDeque。
API
putLast/putFirst添加元素, 阻塞, 直到可以放进去.takeLast/takeFirst取出元素, 阻塞.offerFirst/offerLast添加元素, 非阻塞, 没有返回 false.pollFirst/pollLast取出元素, 阻塞.
优先级调度算法
调度任务/进程 – 不限个数。
假设算法规定, 优先级数字越小优先级越高. 那么可以在内存中形成一个树状结构, 父级元素总是比子级元素优先级高. 这个结构虽然是树状, 但是可以使用数组表示, 就是堆(Heap). 每个新元素插入Heap, 都需要一定的操作维护Heap的性质——父级元素比自己元素值小. 优先级队列的出队操作, 每次都从Heap的顶部拿走一个元素, 然后Heap自己会重新恢复到Heap的状态.
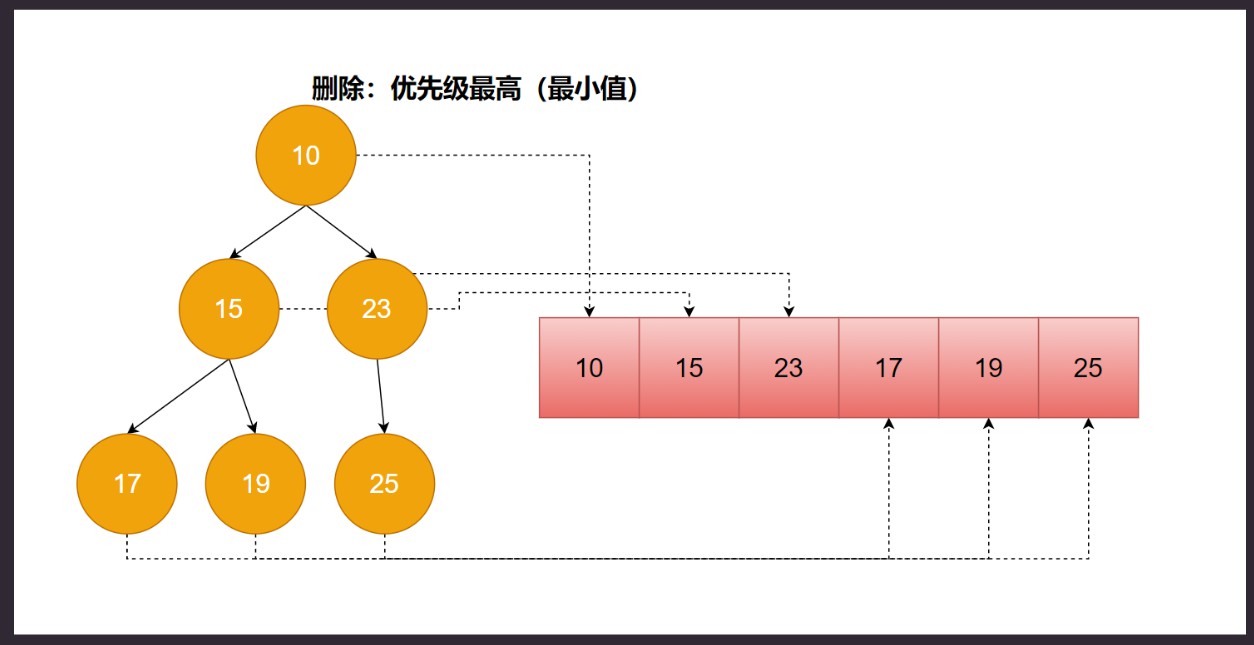
基于 堆(Heap) 实现. 父元素 肯定比 子元素 小, 不关心子节点左右. 上图是 最小堆. 堆的结构很适合优先级的场景。
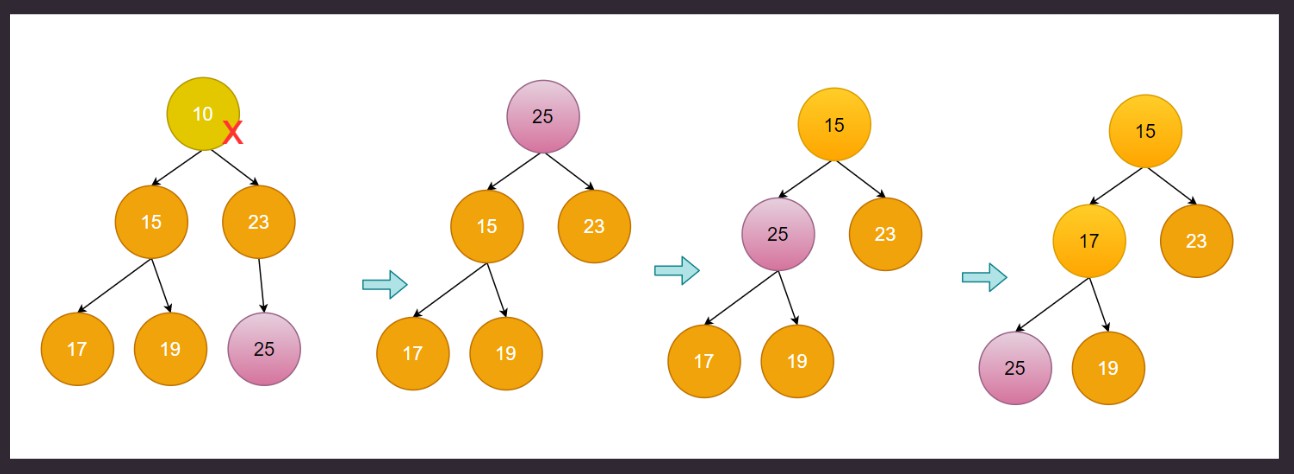
删除最小元素的过程(O(logn)). 堆的删除只能从顶部删除. 然后把堆中最后的元素到堆顶, 和子节点比较, 大于就往下沉。
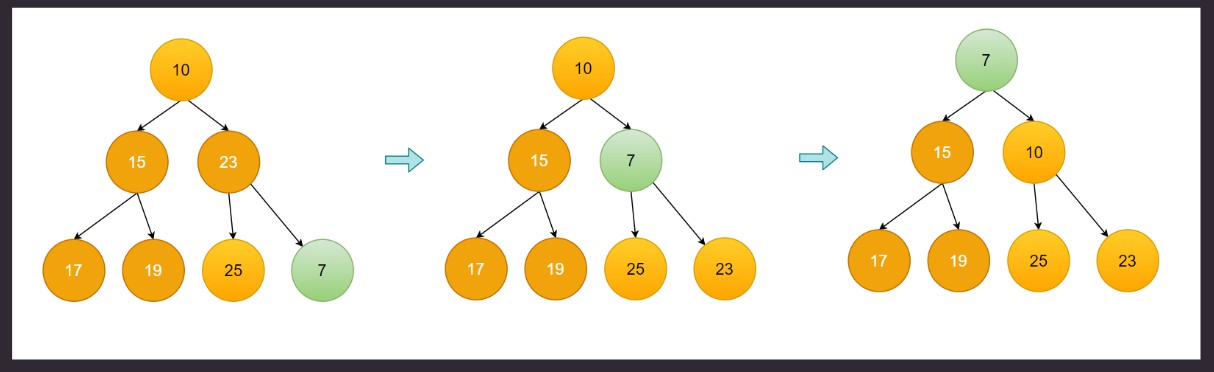
插入元素, 先插入到最后, 然后和父节点比较, 如果小于就向上浮动。
可以使用PriorityBlockingQueue来实现, 线程安全的。
延迟队列
目的:控制流速. 大量任务来临, 系统负载超过临界点(线程频繁切换, 虚拟内存频繁交换, I/O资源争夺)会导致雪崩。

将任务打散到未来来执行.
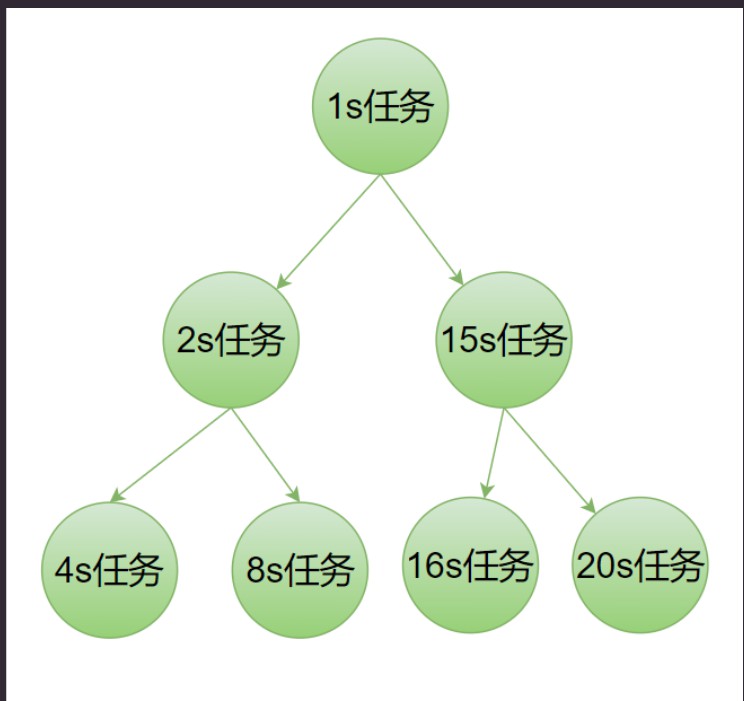
低层维护一个优先级队列PriorityQueue, 每次检查Heap顶部元素的延迟是否超时了, 如果是0就执行。
- 延迟队列适合对任务执行延迟容忍度较高的应用(比如数据分析)。
- 访问拒绝适合实时性要求较高的应用, 例如
Web服务.
控流的其它方案
反向压力(BackPressure), 阻塞任务的提交者。
访问拒绝, 拒绝任务的提交者。
大量的定时任务: 每个订单处理完后1s后给用户发送邮件, 短信; 避免大量定时任务消耗CPU资源(定时器消耗CPU时间较大, 需要设置中断和时钟等等). 甚至不需要定时, 每次取出的时候再算就好了.
大量延迟重试场景:需要发送大量消息给用户. 指数补偿, 1s, 2s, 4s, 8s…
SynchronousQueue 和 LinkedTransferQueue的区别
能力相似, 都提供了 transfer 的能力, 将元素转让给消费者, 如果没有足够的消费者就会拒绝, 是一种传达反向压力的策略.
SynchronousQueue 支持DualQueue/DualStack. 在创建时指定即可. new SynchronousQueue(fair:true/false).
LinkedTransferQueue – 只有DualQueue.
- 都基于双向(Dual)数据结构. 区别:
SynchronousQueue可以选择用双向队列或双向栈,FIFO是公平的,FILO是不公平的.LinkedTransferQueue只有队列的实现. - 都继承于
BlockingQueue接口. 区别:SynchronousQueue的offer方法, 类似LinkedTransferQueue的tryTransfer方法;LinkedTransferQueue的offer方法, 类似传统队列比如ArrayBlockingQueue的offer方法. 因此,LinkedTransferQueue同时兼容了双向队列和单向队列.
ArrayBlockingQueue 和 SynchronousQueue 的区别
ArrayBlockingQueue不能够实现没有足够的消费者就阻塞生产者的逻辑. ArrayBlockingQueue只能在队列已经填满的情况下阻塞, 而SynchronousQueue可以用来实现生产者等待消费者接收元素的逻辑. 比如, 消息处理场景等待接收方接收消息的场景; 再比如线程池中提交任务等待有线程处理的场景. SynchronousQueue支持反向压力, 使生产者和消费者更加默契.
什么是有界队列, 什么是无界队列
- 有界. 缓冲区大小恒定, 一旦队列中的元素达到界限, 那么就会阻塞或拒绝生产者(向队列写入元素的线程).
ArrayBlockingQueue, 扩容慢. - 无界. 缓冲区大小无限.
DelayQueue,LinkedTransferQueue,SynchronousQueue或PriorityBlockingQueue. - 可选.
LinkedBlockingQueue或LinkedBlockingDeque.
LinkedBlockingDeque是一种双向队列, 和SynchronousQueue和LinkedTransferQueue中实现的双向有什么区别
本质上都是双向链表, 但是实现的算法不同.
原理不同: 有无Match操作算法. LinkedBlockingDeque还是传统队列的模式, 两边都可以插入和删除. 而SynchronousQueue和LinkedTransferQueue是生产者和消费者匹配才能算一次消费, 看不到匹配是能感受到的, 就可以休眠或者拒绝等操作.

上图一个DualQueue, 必须生产者的生产(红色)和消费者的消费(绿色)匹配才能够同时删除两个元素. 这样的设计可以同时做到以下2点
- 生产的元素消费不完时, 将元素在队列中等待消费(排队)
- 消费者不足时给生产者反向压力, 阻塞生产者(匹配)
LinkedBlockingDeque只能实现第一个,而SynchronousQueue和LinkedTransferQueue 都可以实现第二个匹配。
BlockingQueue 总结
发邮件,发短信,下载队列,发红包,操作历史维护undo/redo,RPC,Web服务,传输日志,线程池,Nginx的队列,Redis的队列——这些都是生产者/消费者模型。
有界队列非常适合实时性要求较高(需要拒绝服务)的场景, 比如说Web请求, 如果生产太快, 为了保护服务器本身最好的方法就是拒绝一部分服务. 为什么可以拒绝服务?这是因为用户等不起. 用户等待1s跳出率10%, 等待2s就有30%, 等待10s, 就90%跳出了. 等待20s?没人用了. 这种情况下, 队列中能存储大量的元素反而变得没有意义, 反而是有界队列(或者有界缓冲区)非常有用, 一旦缓冲区满, 超出服务器的处理能力, 就DOS(Deny Of Service)一部分的请求, 保证另一部分请求正常被处理。
无界队列适合对实时性要求不那么敏感的场景, 比如说下载大量文件,发大量红包和短信,这些场景,就可以考虑用无界队列. 无界队列更关心事情都要做完, 而不是事情必须在限定的时效内做完.


博客内容遵循 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 协议
本文永久链接是:https://blog.lgq51233.xyz/2020/09/28/Java%E7%9A%84%E9%98%BB%E5%A1%9E%E9%98%9F%E5%88%97/