
JVM GC
GC Garbage Collection
对象被判定为垃圾的标准 : 没有被其他对象引用.
GC 指标
GC 指标: 吞吐量, 延迟, 脚印
吞吐量(Throughput)
- 程序工作时间占比(没有STW). GC没有占用的CPU时间.
-XX:GCTimeRatio=99. 默认就是99. 就是说吞吐量占比就是99%, 也就是 GC 只占用 1%.- 提高 Throughput.
- 给更大的内存. -Xmx4G. GC频率变低.
- 更改 GC 算法
- 多线程能不能提高 Throughput? 不能. 100s的工作, 分成10个线程执行, 不能做到10s完成. 线程的切换也需要时间. 10个线程不代表10核(并行). CPU的占用率没有下降.
- 需要吞吐量的应用
- 离线任务
- 抢购服务
- 竞技游戏服务
- 音视频服务
网络中吞吐量指在单位时间内传输的数据量.
阿姆达尔定律(衡量并行计算的定律)
- 可并发部分(90%)
- 不可并发部分(10%)
- 10个线程的极限倍数:
1 / (90% / 10 + 10%), 5倍左右, 和10 倍差远了.
公式: 1 / ((1 - P) + P/N), P是可以并发部分, N是核数
延迟(Latency)
指 GC 造成的停顿时间(STW)时间.
Pause Time.
Throughput 小那么 Latency 就低? 没有必然的关系。
这个时间指峰值.
延迟的要求和应用的特性相关. 例如: 打游戏, 连麦…
多线程能不能减少Latency? 可以,加快GC回收。
内存大也能减少 Latency。
脚印(FootPrint)
指最终应用对内存的需求,也就是内存的使用,内存的消耗。
内存使用速度 100m/s, 回收速度 80m/s. 不全部回收持续下去会 Out Of Memory. 需要STW.
如果10s 做一次FGC(STW全部回收). 10s中产生 1000m, 回收 800m,还有 200m。Latency上升(STW次数多了), 峰值就是 200M 内存(FootPrint), 还没有被回收的.
GC 其实也是在控制 FootPrint, 以不至于太高.
判断算法
判定是否为垃圾的算法
- 引用计数算法
- 可达性分析算法
引用计数算法
- 通过判定对象的引用数量来决定对象是否可以被回收
- 每个对象实例都有一个引用计数器, 被引用则+1, 完成引用则-1. 例如在某个方法里定义了一个引用变量, 指向一个对象实例, 当方法执行完毕后, 由于该变量是局部变量, 结合之前 JVM 的内存模型, 该变量是存储在
JVM Stack上的, 所以会被释放掉. - 任何引用计数为 0 的对象实例可以被当作垃圾收集
优点 : 执行效率高, 程序执行受影响较小
缺点 : 无法检测出循环引用的情况, 容易导致内存泄漏. 例如: 父对象有对子对象的引用, 子对象也反过来引用父对象, 这样的话, 他们的引用计数就永远不可能为零了, 也没有纠错机制.
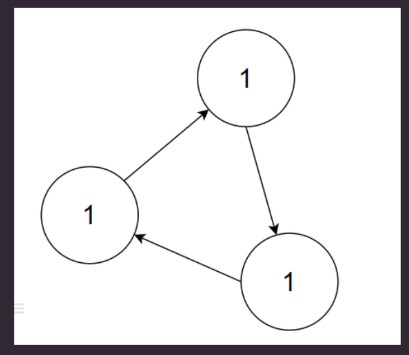
可达性分析算法
通过判定对象的引用链是否可达来决定对象是否可以被回收, 是从离散数学中图论引入的. 程序把所有的引用关系看作一张图, 通过一系列名为 GC Root 的对象作为起始点, 从这节点开始向下搜索, 搜索所经过的路径被称为引用链. 当一个对象与 GC Root 没有任何引用链相连, 从图论上讲, GC Root 到这对象是不可达的.
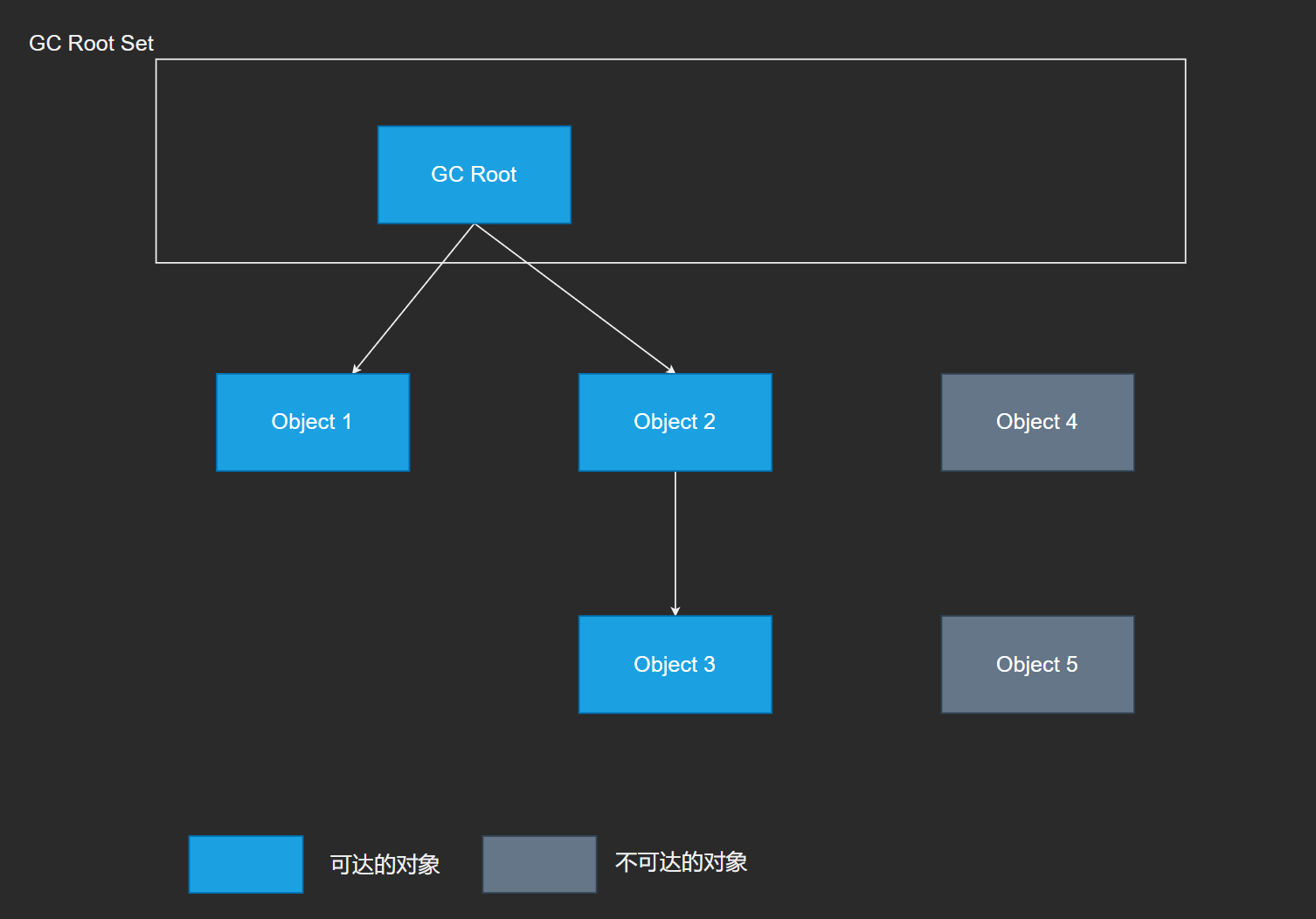
可以作为GC Root的对象
- 虚拟机栈中引用的的对象(栈帧中的本地变量表). 在一个方法里
new Object(), 并赋值给了一个局部变量, 在该局部变量没有被释放前, 这个object就是GC Root. - 方法区中的常量引用的对象. 比如在类里面定义了一个常量, 而该常量保存的是某个对象地址, 那么被保存的对象也就成为了
GC Root. - 方法区中的类静态属性引用的对象.
- 本地方法栈 JNI(Native方法) 引用的对象.
- 活跃线程的引用对象. 万物皆为对象, 所以线程也会成为 GC Root, 而它引用的对象也是判定是可达的。
总结: 方法区中的常量, 静态变量的引用; 当前活跃栈中的引用。
GC清理算法
双色标记-清除
Mark and Sweep
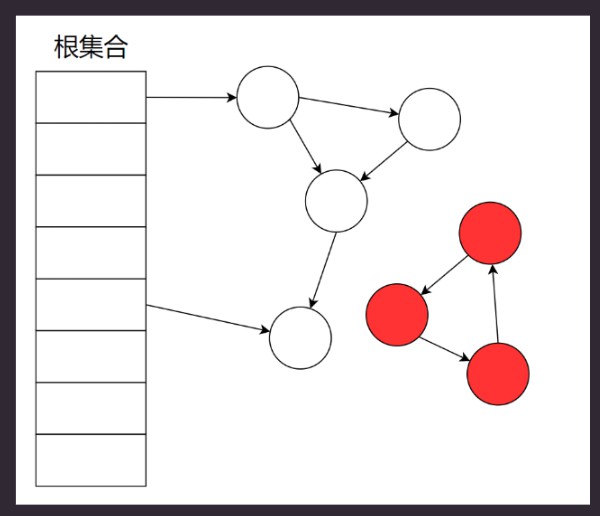
红色的那3个就是可以被回收的对象. 因为没有连接到根节点了.
解决了循环引用的问题. 少回收的对象被称作 浮动垃圾.
Root集合: 方法区中的常量, 静态变量的引用. 当前活跃在栈中的引用.
遍历图用 bfs 还是 dfs ? 一样的. 都要解决[环]的问题. 在链表中处理环可以使用 快慢指针, 而图中处理环只能使用集合。
分两个阶段
- 标记(Mark): 上色,对存活(可达)的对象进行标记.
- 清除(Sweep): 对堆内存从头到尾进行线性遍历, 回收不可达对象内存. 分阶段(2 phase): 需要 finalize 的类; 不需要 finalize 的类(直接回收).
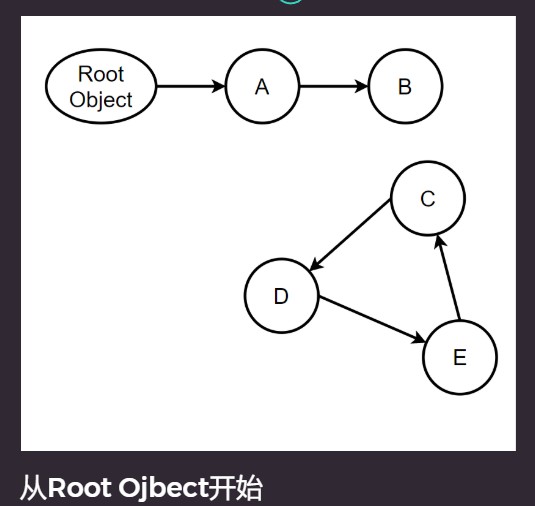
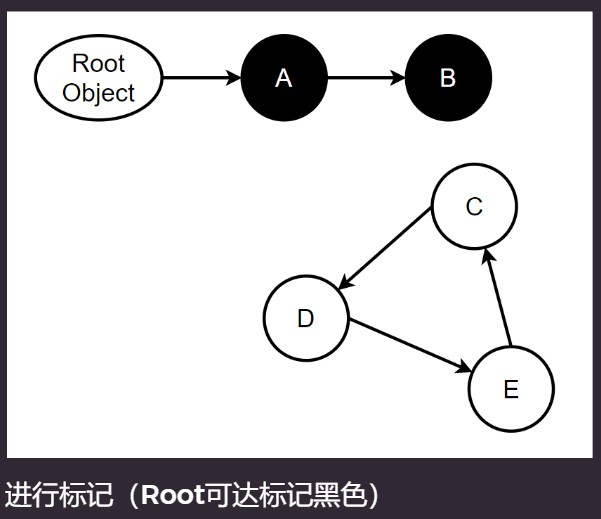
白色是不可达的, 黑色是可达的标记, 不需要GC.
缺陷: Mark-And-Sweep期间可能出现 Mutation 的情况.

Mutation: 一种状态, 程序执行变更, 并发下可能导致的问题.
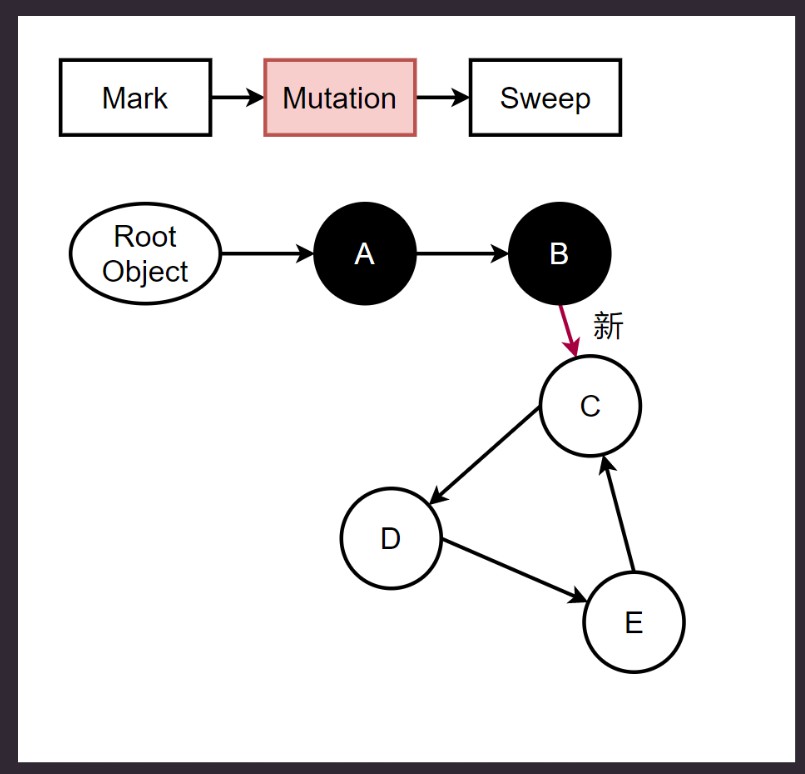
如果Mutation后, 另外线程将C置为黑色(并发造成, 可见性问题), 但是Sweep会继续, 然后把C, D, E都回收.
然而实际这种情况应该由C开始都需要重新标记.
三色标记-清除
三色标记-清除, 解决上面的情况.
增加一种颜色, 灰色: 代表不确定, 不确定集合: {C}. 有Mutation就进行ReMark.
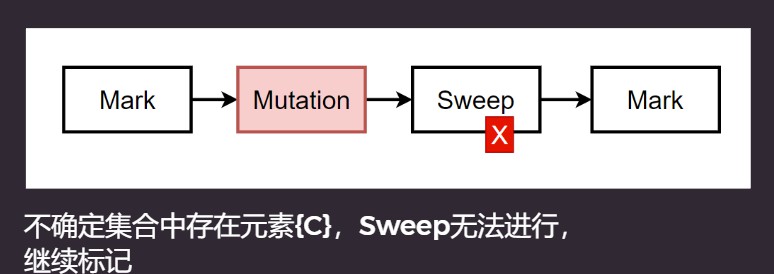
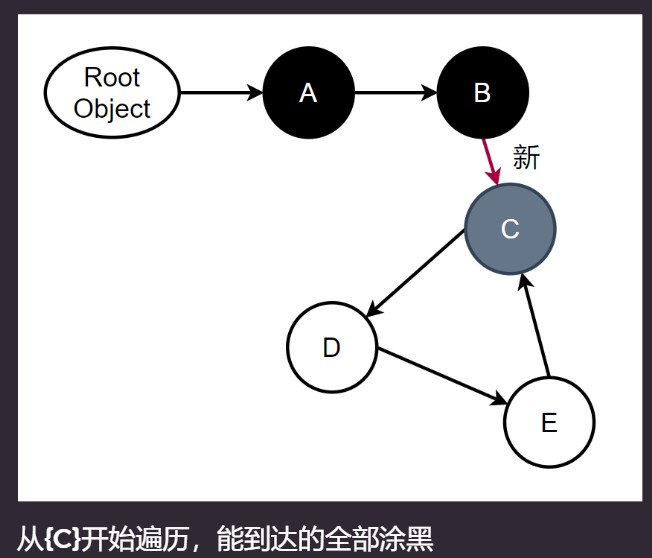
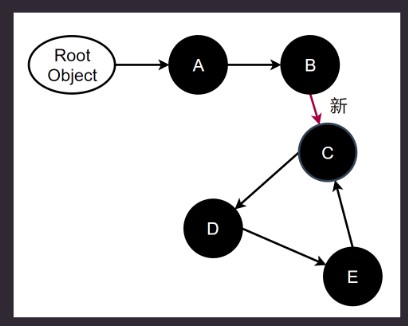
灰色代表还没有未完成的标记.
Sweep过程中, 如何定位所有白色对象? Java 可以遍历Heap中的所有对象(GC提供能力)
复制-整理
内存碎片化. 由于不需要进行对象的移动, 并且只对存活的对象进行处理, 因此容易产生大量的不连续的内存碎片. 很容易导致, 在之后要生成较大对象时, 无法找到足够的连续内存, 而不得不提前触发另一次 GC.
- 分为对象面和空闲面
- 对象在对象面上创建
- 存活的对象被从对象面复制到空闲面
- 将对象面所有对象内存清除
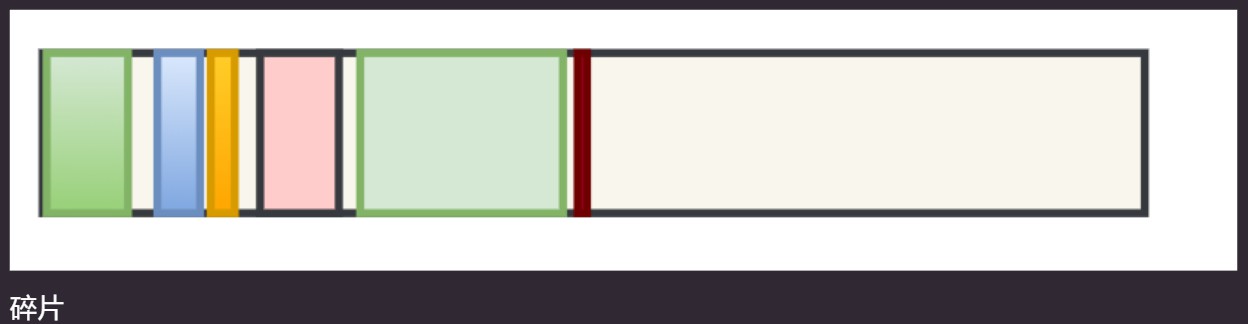
整理–compact
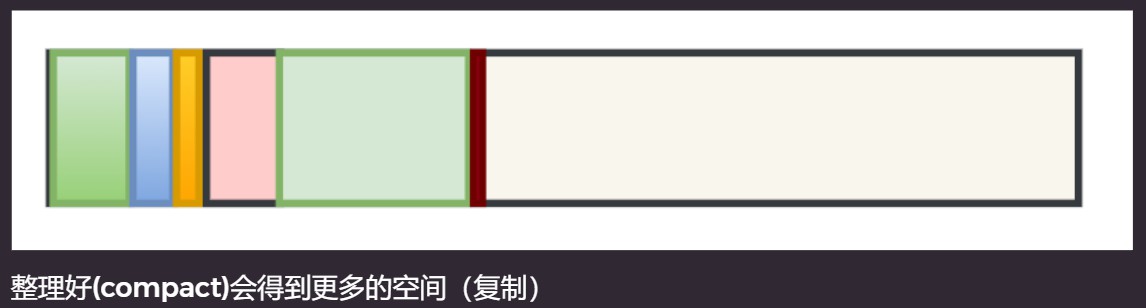
- 解决碎片化问题
- 顺序分配内存, 简单高效
- 适用于对象存活率低的场景(年轻代)
标记-整理
Compacting
- 标记 : 从根集合进行扫描, 对存活的对象进行标记
- 清除 : 移动所有存活的对象, 且按照内存地址次序依次排列, 然后将末端内存地址以后的内存全部回收
在 标记-清除 算法的基础上进行了对象的移动, 因此成本更高, 但是解决了内存碎片的问题.
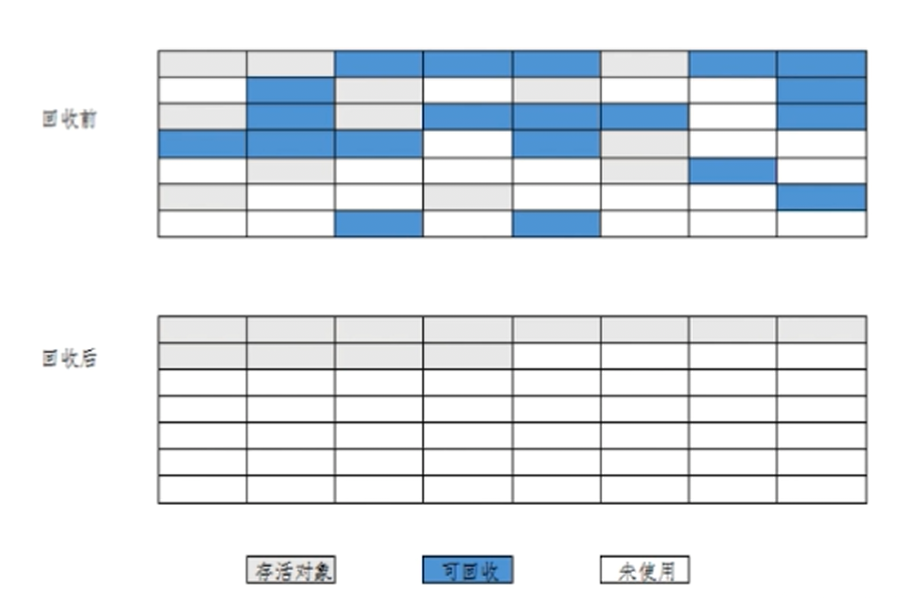
- 避免了内存的不连续性
- 不用设置两块内存互换
- 适用于存活率高的场景(老年代)
分代收集算法
- 垃圾回收算法的组合拳.
- 按照对象生命周期的不同划分区域以采用不同的垃圾回收算法.
- 目的 : 提高 JVM 的回收效率.
jdk6, jdk7 -> Young Generation, Old Generation, Permanent Generation
jdk8 之后 -> Young Generation, Old Generation
年轻代的对象存活率低, 就使用 标记-复制算法, 而老年代对象存活率高, 就使用 标记-清除算法 或者 标记-整理算法.
Heap 分代组成
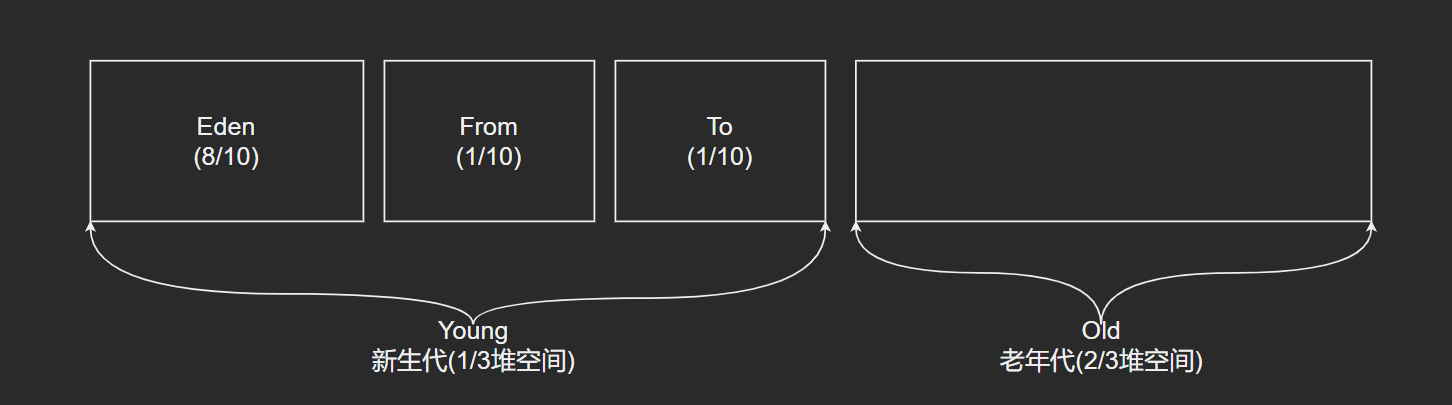
新生代
尽可能快速收集掉那些生命周期短的对象. 分为 2 个区域.
- Eden 区
- 两个 Survior 区(From, To), 哪个是From或To是不固定的, 会随着垃圾回收的进行相互转换.
分一个内存区域给新创建的对象(死亡率高.) – 新生代(New Generation, Eden), 也称为伊甸区.
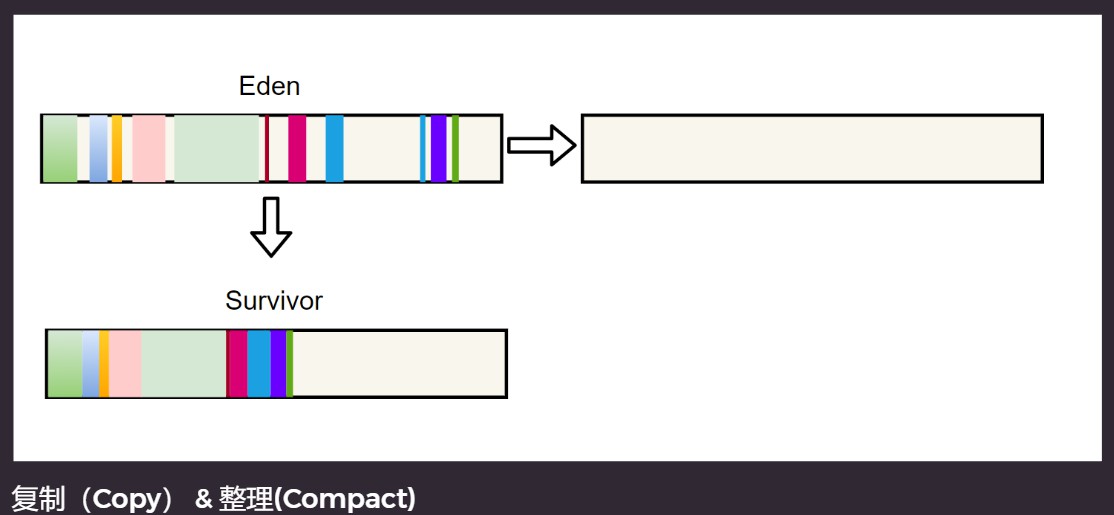
划分一个新的区, 边 copy 边 compact. 这个区就是 存活区 (Survivor).
整理频繁的话, survivor 可以比 Eden 小, 使用-XX:SurvivorRatio=8(默认)参数. 比例 Survivor:Eden = 1:8.
如果 Survivor 也满了, 就会去到 老生代(Tenured).
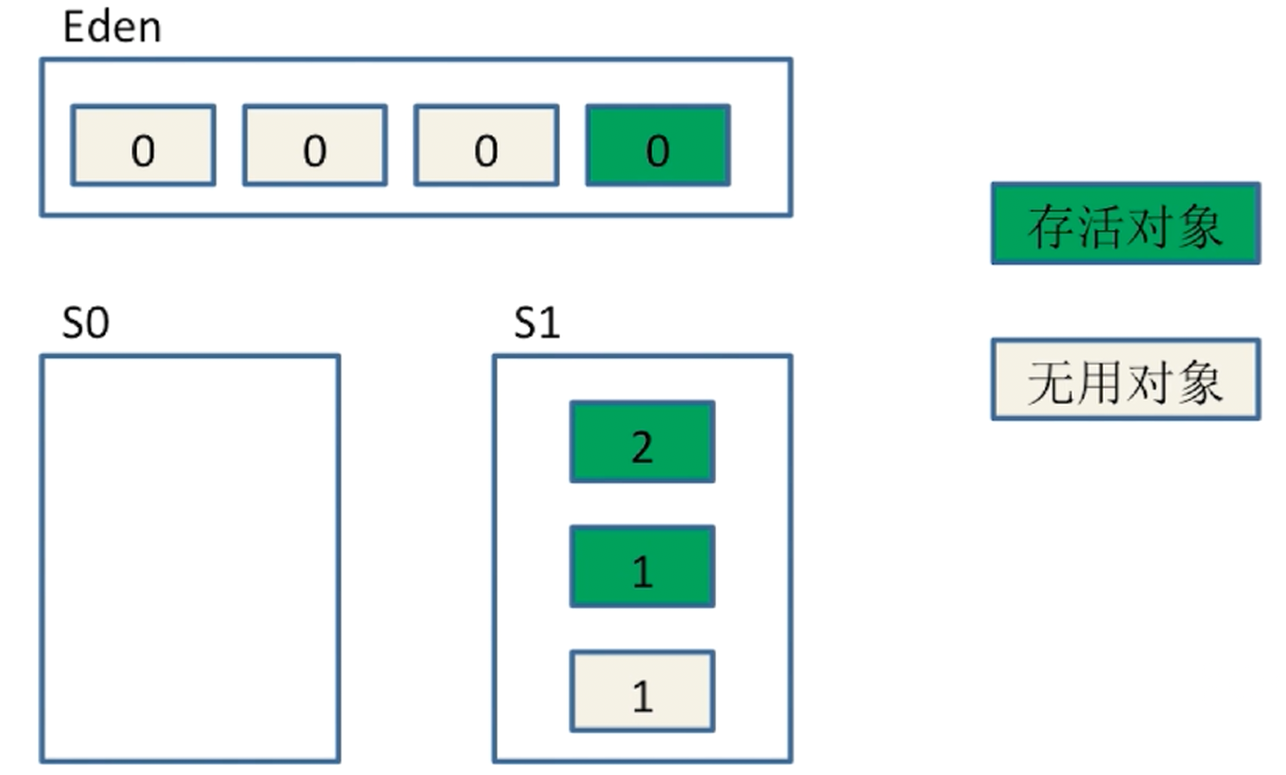
大致流程 :
-
Eden区产生四个对象(填满了), 触发Minor GC后, 剩下一个对象, 这时会把对象放进Survior(S0) 区, 放进去的区域S0就是From区, 对应的另外一个S1就是To区, 这时存活的对象会被 +1. - 接着,
Eden区再次被填满了, 有2个无用对象, 这时又会触发一次Minor GC, 把所有的对象(3个)都放进S1中, 同时也都 +1, 这时,S1变成了From区,S0变成了To区, 然后清空Eden和S0区域. Eden区又一次被填满, 又触发一次Minor GC, 此时Eden区有一个是存活对象, 而S1有两个存活对象, 然后把存活对象都放在S0区, 年龄都 +1, 清空其他区域. 对象每熬过一次Minor GC,其age都会 +1, 当对象的age达到某个值的时候, 默认是 15 岁(可以通过-XX:MaxTenuringThreshold来调整), 就会进入老年代, 但是也是不一定的, 只要分配较大的连续内存空间.
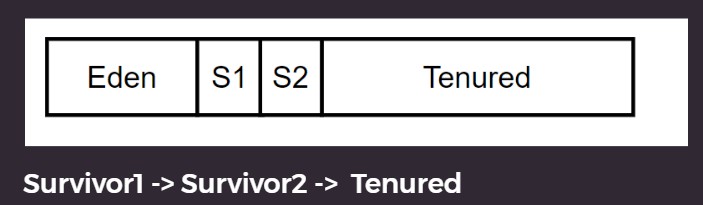
Survivor 分2个区域. 老生代是对象死亡概率最低的. 如果 S2 的都进入 Tenured , 这时候 S2 就空了, S1 和 S2 就可以交换, 减少一次复制.
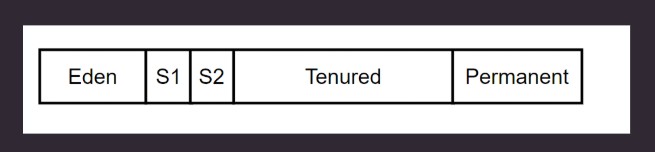
永生代, JDK之后去除了. 现在 Method Area 已经在堆外内存了。
对象是如何晋升到老年代的?
- 经历一定
Minor GC次数依然存活的对象. Survivor区中放不下的对象.- 新生成的大对象(
-XX:+PretenuerSizeThreshold), 超过这个Size的对象生成, 这个对象立马放进老年代.
老年代
存放生命周期较长的对象. 占用的内存一般比新生代的大. 新生代使用的是复制-整理算法, 而老年代则使用 标记-清除算法 或者 标记-整理算法.
Full GC和Major GC. 一般来说, 老年代的回收一般伴随着年轻代的回收. 而Major GC一般指 老年代的 GC 回收.Full GC比Minor GC慢, 但执行频率低.
触发 Full GC 的条件
- 老年代空间不足.
- 永久代空间不足(JDK7以及以前版本).
CMS GC时出现promotion failed(指survivor放不下, 要放进老年代时, 老年代也放不下去),concurrent mode failure(执行 CMS GC 的同时, 也有对象放入老年代中, 而此时老年代空间不足).Minor GC晋升到老年代的平均大小(统计得到的)大于老年代的剩余空间. 例如: 程序第一次触发Minor GC后, 有 6M 的对象晋升到 老年代, 当下一次Minor GC发生时, 首先检查老年代的剩余空间是否大于 6M, 如果小于的话就执行Full GC.- 调用
System.gc(), 显式调用, 提醒JVM的作用。 - 使用
RMI来进行RPC或管理的JDK应用, 每小时执行一次Full GC。
Stop-the-World
- JVM 由于要执行 GC 而停止了应用程序的执行。
- 任何一种 GC 算法中都会发生。
- 多数 GC 优化通过减少 Stop-the-world 发生时间来提高程序性能, 使程序具有高吞吐, 低延迟, 低脚印的特点。
SafePoint
JVM 的 GC 就像清洁工.
- 分析过程中的对象引用关系不会发生变化的点.
- 产生
Safepoint的地方 : 方法调用, 循环跳转, 异常跳转等 - 安全点数量得适中
常见的 GC
不同 GC 是可以并存的.
Serial Collector
Serial – 连续的. 已弃用.
- Single Thread. 也就是说 双色标记-清除 也够用了, 因为没有并发问题.
- STW GC完才继续, 与之相反的是 concurrent.
-XX:+UseSerialGC- 算法: Root Tracing & Mark-Sweep
- 场景:
- 吞吐量小
- 容忍延迟
- 单核, 内存小: 0~100M
Parallel Collector
Parallel [ˈpærəlel], 并行收集器. Serial 的升级版. 已弃用.
- 理论上提供最大的
Throughput.(任务拆分, 线程创建, 切换, 结果合并…) MultiThread- STW 和 Serial 一样, 不过是并行的. Not Concurrent, 就是 Mark/Sweep/Mutation不是交错执行的.
-XX:+UseParallelGC- 算法: Root Tracing & Mark-Sweep
- 场景: 吞吐量要求 > 延迟要求.
Concurrent Mark Sweep
CMS, 并发标记-清除. 逐渐弃用. jdk9之后被标记为过时了, jdk14已经移除.
- 减少 Pause Time
- STW
- 算法: Root Tracing & TriColor Mark-Sweep & Copy/Compact & Aging(多种算法组合)
-XX:+UseConcMarkSweepGC-XX:+CMSIncrementalMode. 开启增量CMS模式(i-cms). 延迟高的场景可以打开.
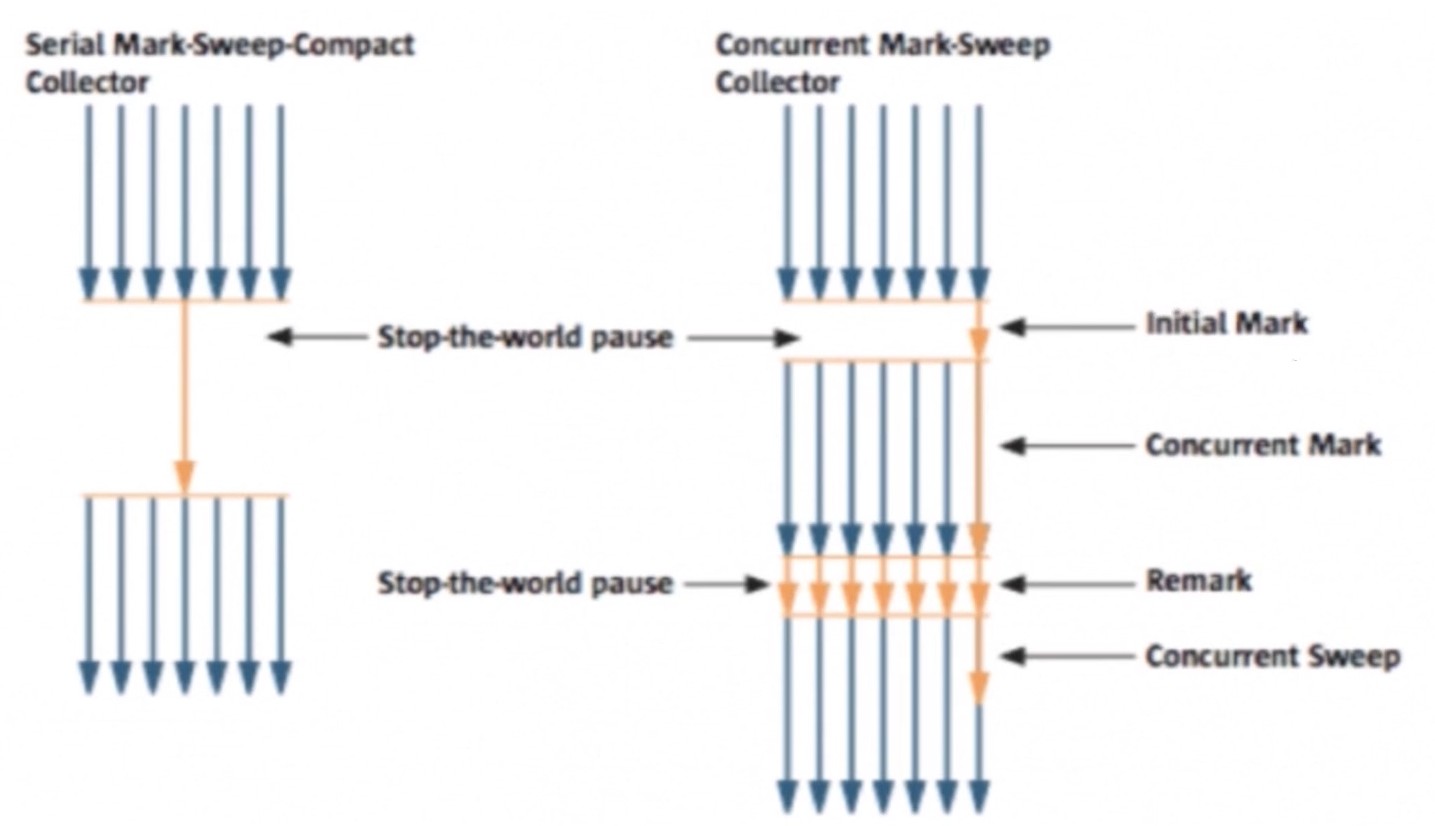
七个步骤
initial mark(STW): 标记可直达的老年代的根存活对象(可达性分析,速度很快).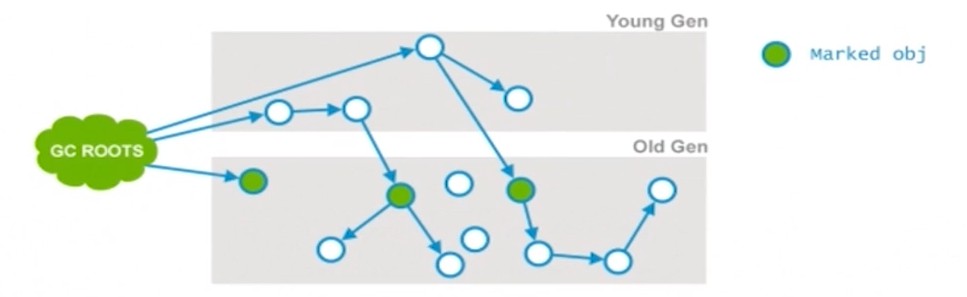
concurrent mark: 并发标记(和应用程序并发执行), 通过第一阶段标记出来的存活对象, 继续递归遍历老年代, 并标记可直接或间接到达的所有老年代存活对象. 因为是并发执行的,所以Current Obj的引用被改变了,会在下一个阶段处理。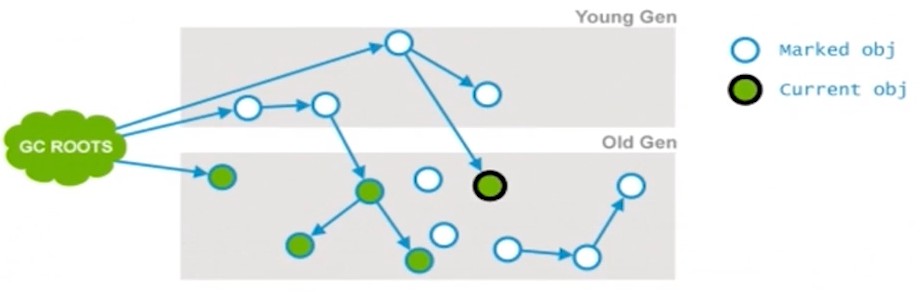
concurrent preclean: 并发预清理, 将重新扫描前一个阶段的Dirty对象(mutation, 因为并发执行的,所以引用关系会改变,而Dirty对象就是在前两个阶段之间被标记的, 三色标记法), 并标记被Dirty对象直接或间接引用的对象, 然后清除Card标识.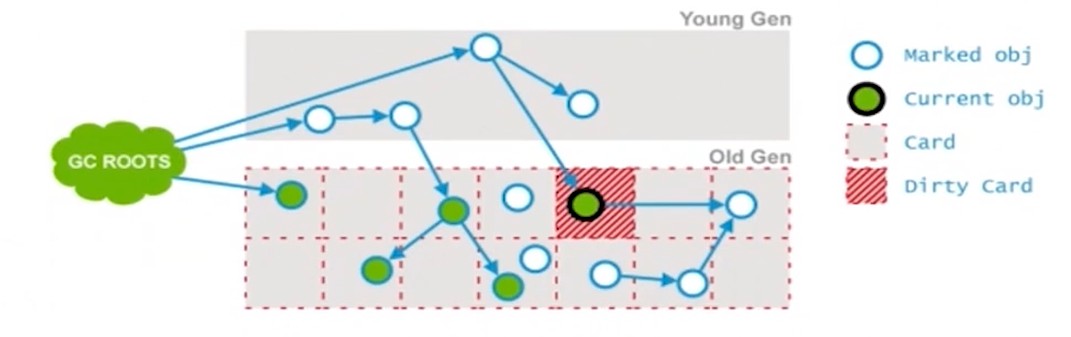
concurrent abortable preclean: 可中止的并发预清理. 尽可能承担更多的并发预处理工作, 从而减轻在Final Remark阶段的STW, 同时也处理 From 和 To 区的对象, 标记可达的老年代对象, 并处理 Dirty 对象.remark(STW): 重新标记. 重新扫描之前并发处理阶段的所有残留更新对象,最终生成一个最终要清理对象的视图。concurrent sweep: 并发清理, 清理所有未被标记的死亡对象, 回收被占用的空间.concurrent reset: 并发重置. 清理并恢复 CMS GC 过程中的各种状态, 重新初始化 CMS 相关数据结构.
从上可以知道, CMS 调优主要是为减少 initital mark 和 remark.
Minor vs Major
- Minor GC. Eden GC. JVM 无法分配更多内存. 如果有个 Object 在 Eden 中有个引用指向 Tenured. 只会回收新生代, 不会回收老生代.
- Major GC. Tenured GC. 大多数内存的回收.
- Full GC. Both.
浮动垃圾(Floating Garbage)的问题. 在一次周期, Mark中可能有 Mutation, 导致一些本来就是垃圾的对象没有被回收, 要等下一次周期.
场景
- 覆盖
Serial/Parallel Collector的场景. - 需要减少
pause time的场景。
G1
Garbage First。使用分区算法,不要求eden,年轻代或老年代的空间是连续的。
-XX:UseG1GC, 使用 复制+标记-整理算法, 既用于年轻代, 也用于老年代.
目标: 大内存. 兼顾 Latency 和 Throughput. JDK1.7之后的回收器,目标是替换代替JDK5中 CMS。
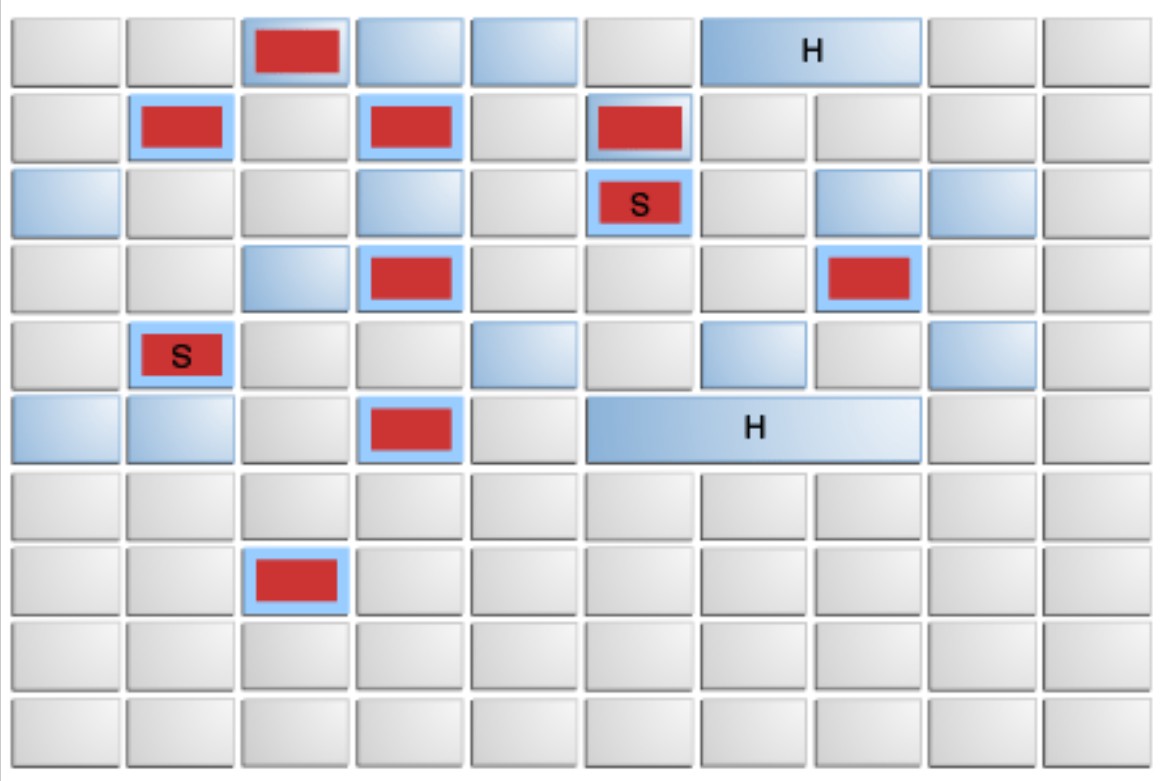
红色块: 新生代; 深蓝块: 老年代. 每个生代划分成了一个小区域. 每个线程处理的就是一小块. 天生适合并发处理. 但是, 格子里的对象, 可能会有指向其它格子的引用, 就是格子之间可能会有引用关系.
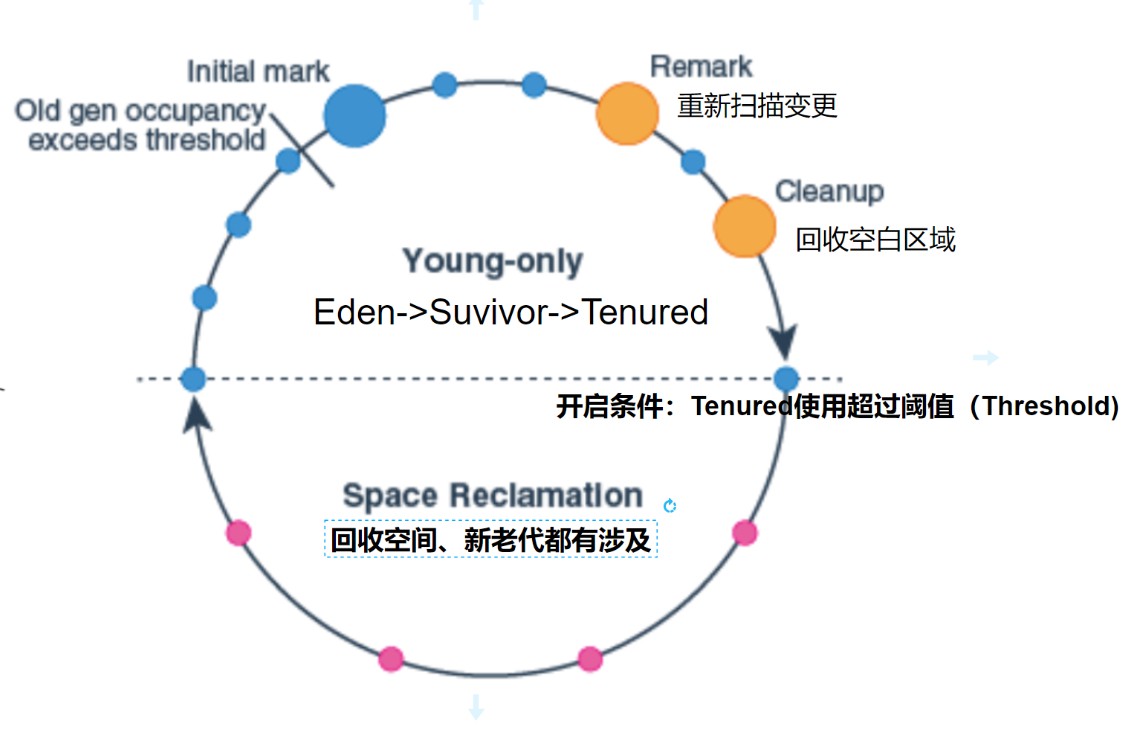
G1本质是用空间换时间,减少了路径的扫描,让G1可以更快地决策。
步骤
- 初始标记。从GC Root开始标记直接可达的对象。
- 并发标记。从GC Root开始对堆中的对象进行可达性分析,找出存活对象。
- 最终标记。标记那些在并发标记阶段发生变化的对象,将其回收。
- 筛选回收。对各个Region的回收价值和成本进行排序,根据用户所期待的GC停顿时间指定回收计划,回收一部分Regin。
G1 特点
并行和并发
分代收集
空间整合, 解决了内存碎片的问题
可预测的停顿
将整个
Java Heap内存划分成大小相等的 Region [ˈriːdʒən].年轻代和老年代不再物理隔离
G1了解哪个区域最空; 帮助最快回收最多内存.
ZGC
低延迟的GC. JDK11的GC(实验性).
- 最大延迟时间几个ms
- 暂停时间不会随堆大小, 存活对象数目增加
- 8MB ~ 16TB
Epsilon GC, 没有GC的GC, 可用于测试.
GC 分类
新生代垃圾收集器
- Serial 收集器 (-XX:+UseSerialGC, 复制算法)
- 单线程收集, 进行垃圾收集时, 必须暂停所有工作线程
- 简单高效, Client 模式下默认的年轻代收集器
- ParNew 收集器 (-XX:+UseParNewGC, 复制算法)
- 多线程收集, 其余的行为, 特点和 Serial 收集器一样
- 单核执行效率不如 Serial, 在多核下执行才有优势, 因为存在进程交互开销
- 默认开启的线程数与 CPU 的核心数相同
- Parallel Scavenge 收集器 (-XX:+UseParallelGC, 复制算法)
- 吞吐量 = 运行代码用户时间/(运行用户代码时间+垃圾收集时间)
- 比起关注用户线程停顿时间, 更关注系统的吞吐量
- 在多核下执行才有优势, Server 模式下默认的年轻代收集器
- 使用
-XX:UseAdaptiveSizePolicy, 把内存管理交给 JVM 完成
老年代垃圾收集器
- Serial Old 收集器 (-XX:+UseSerialOldGC, 标记-整理算法)
- 单线程收集, 进行垃圾收集时, 必须暂停所有工作线程
- 简单高效, Client 模式下默认的老年代收集器
- Parallel Old 收集器 (-XX:+UseParallelOldGC, 标记-整理算法)
- 多线程, 吞吐量优先
- CMS 收集器 (-XX:+UseConcMarkSweepGC, 标记-清除算法)
- 初始标记 : stop-the-world, JVM 停止当前任务, 这个过程从垃圾回收的根对象开始, 只扫描和 GC Root 关联的对象, 并做标记, 此过程很快完成.
- 并发标记 : 并发追溯标记, 程序不会停顿. 在初始标记基础上追溯标记. 应用程序线程和追溯线程并发执行.
- 并发预清理 : 查找执行并发标记阶段从年轻代晋升到老年代的对象.
- 重新标记 : STW, 扫描 CMS 堆中的剩余对象. 从根节点开始, 并处理对象关联.
- 并发清理 : 清理垃圾对象, 程序不会停顿.
- 并发重置 : 重置 CMS 收集器的数据结构.
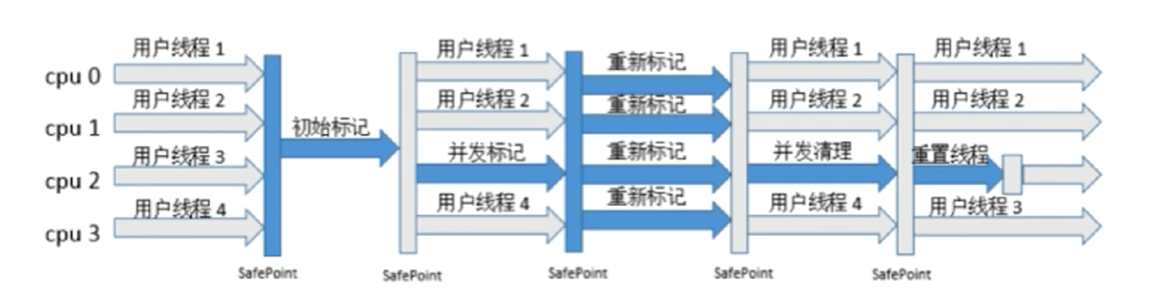
有个很明显的缺点, 会带来内存碎片化的问题!!!
回收整个JVM堆
- G1 收集器。
博客内容遵循 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 协议