
行存储和列存储
行存储和列存储
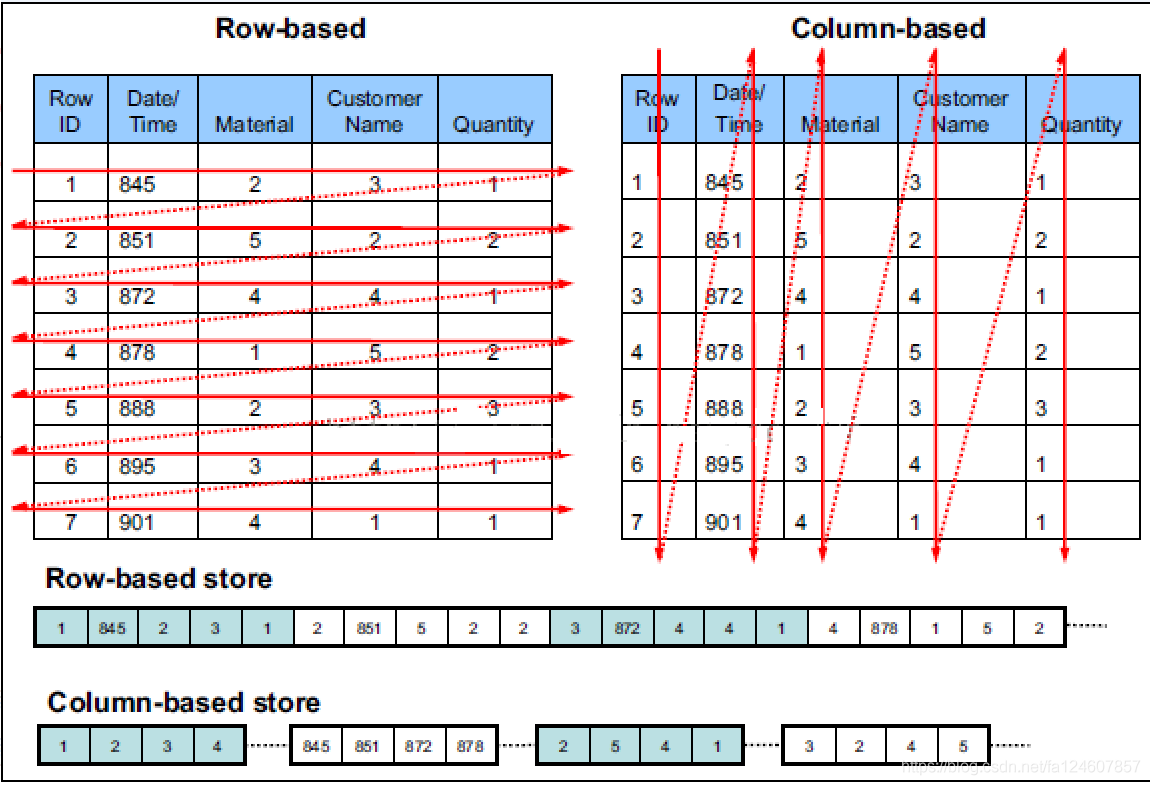
行存储和列存储是存储模型, 逻辑上还是存在行列的. 以块的形式存在
行存储
数据一行行存储. mysql中有一个常见的结构, varchar存储结构就不是固定的, int 是固定长度的, 后面传的数字是表示保留多少位的意思.
面临着一个问题, 每行都不一定大, 空间不好分配.
- 方案1, 补齐, 但是浪费空间.
- 方案2, 使用链表.
从 1G(10亿)数据中取出 100001 ~ 200000 行. 因为页表的存在, 读取一般是 2k, 4k 这样的值. 所以读取硬盘到内存中也是这样的单位.
从基本连续的空间中读取10w 即可.
如果 从1G行中取出数据 100001 ~ 200000 行的name, state列. 先读行, 再取列. 从10w行的数据集中取出name, state列.
读取其中某些字段:
- 1行平均10kb
- 10w行 = 10w * 10kb = 1G数据
- Buffer(2^22 = 4M),需要256(2^8)次读取
- 对10w数据过滤操作
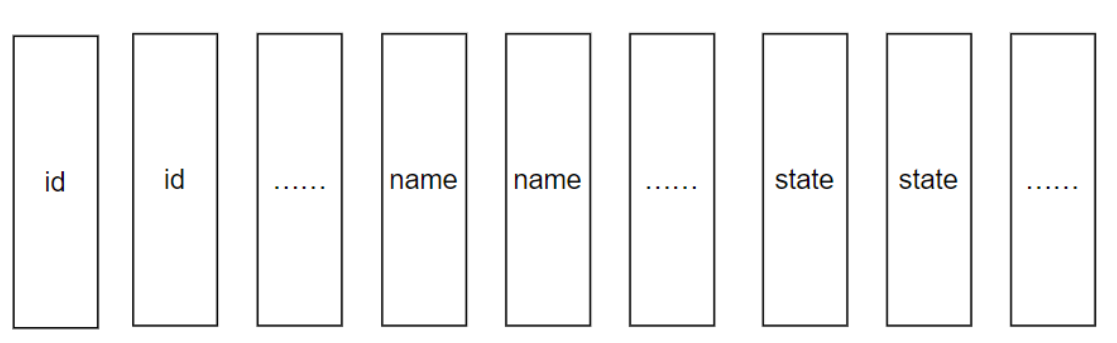
列存储
数据一列列存储. 例如上面每列的第一个 id, 第一个 name, 第一个 state … 就组成了一行.
从 10 亿数据中取出 100001 ~ 200000 行. 需要读取 10w 条 * 列数 数据.
如果要取出 100001 ~ 200000 行 的 name, state 列, 就可以先取列, 再取行, 从2列中读取10w条数据.
读取其中某些字段成本分析:
- 一列的一个条目平均
20byte. - 10w的两列 = 20byte * 10w * 2 = 4M.
- Buffer(4m) 读取1次.
- 不需要过滤操作.
读取所有行的成本:
- 1行平均10kb
- 10w = 100wkb = 1g, 总内存差异不大
4M buffer 其实已经很大了, 如果1000个线程, 就4GB了…
行存储 VS 列存储
- 更新一行的多个值. 行存储有优势.
- 添加一行的数据. 行存储有优势.
- 事务. 行存储, 可以锁一行数据; 列的话, 会影响其它数据, 范围大, 不适合事务.
- 行存储更适合处理事务, 列存储更适合处理查询
流行数据库存储方式
mysql: 行存储, 事务处理是强项.mongodb: nosql(不用sql查询). 文档存储, 存储一个JSON(BSON)文档(树状), 或者一个文本(二进制) 文档, 也叫做对象存储. 类似: Elasticsearch, OSS(Object Store Service), Solr, Lucene(全文搜索引擎).postgre: 对象关系数据库. 结合SQL和NOSQL. 行存储, 某列中的数据, 允许是Binary JSON.HBase: 列存储数据库(底层有分布式文件系统).
博客内容遵循 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 协议