
计算机网络
计算机网络
- ISP(Internet Service Provider): 网络服务提供商
- 中国电信, 中国移动, 中国联通等…
计算机网络层级结构
层次结构设计的基本原则

分层实现不同功能.

- 各层之间是相互独立的
- 每一层要有足够的灵活性
- 各层之间完成解耦
OSI 七层模型
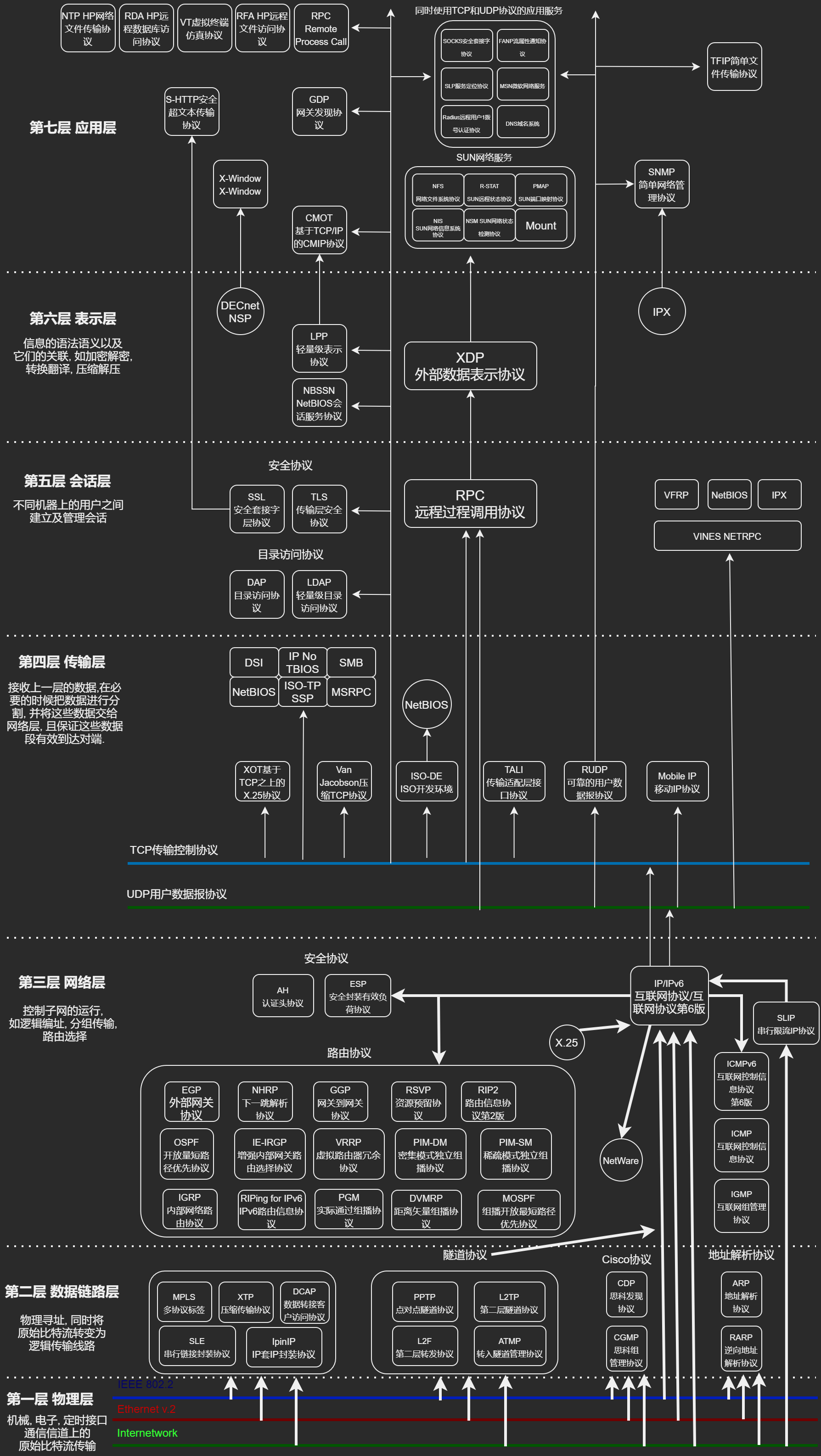
- 应用层: 为计算机用户提供接口和服务
- 表示层: 数据处理(编码解码, 加密解密)
- 会话层: 管理(建立, 维护, 重连)通信会话
- 传输层: 管理端到端的通信连接.
- 网络层: 负责数据的路由(决定了数据在网络中的路径).
- 数据链路层: 管理相邻节点之间的数据通信
- 物理层: 数据通信的光电物理特性
不能成为标准的原因
- OSI 专家缺乏实际经验
- 制定周期过长, 按OSI标准生产的设备无法及时进入市场
- 设计不合理, 一些功能在多层重复出现
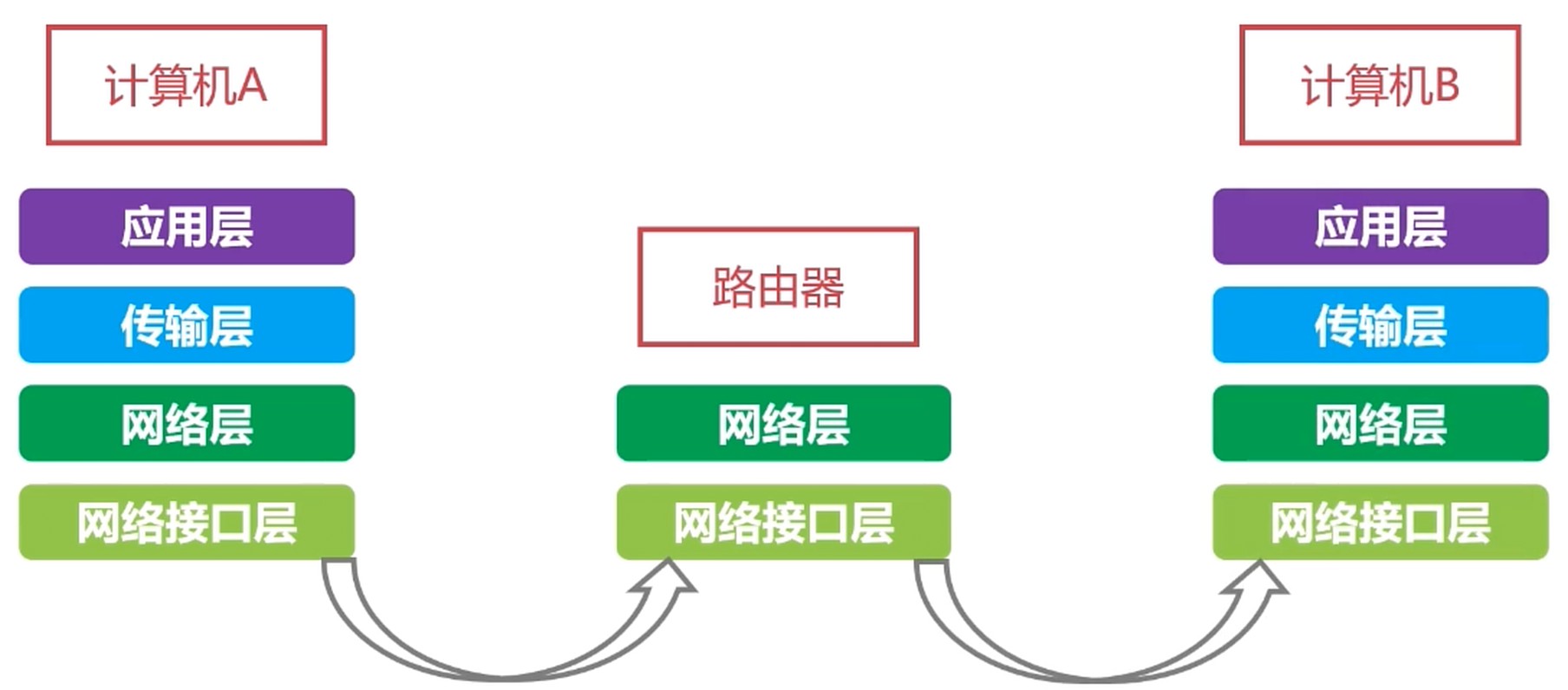
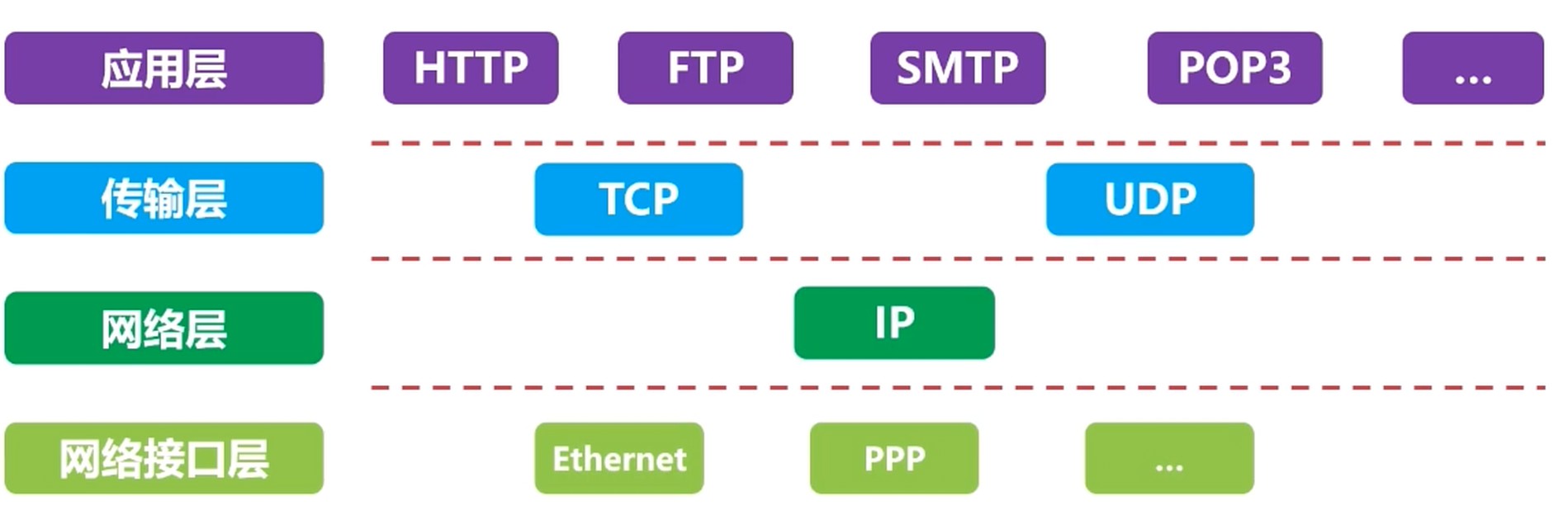
TCP/IP 四层模型
- 应用层. HTTP/FTP/SMTP/POP3
- 传输层. TCP/UDP
- 网络层. IP/ICMP
- 网络接口层. Ethernet/ARP/RARP
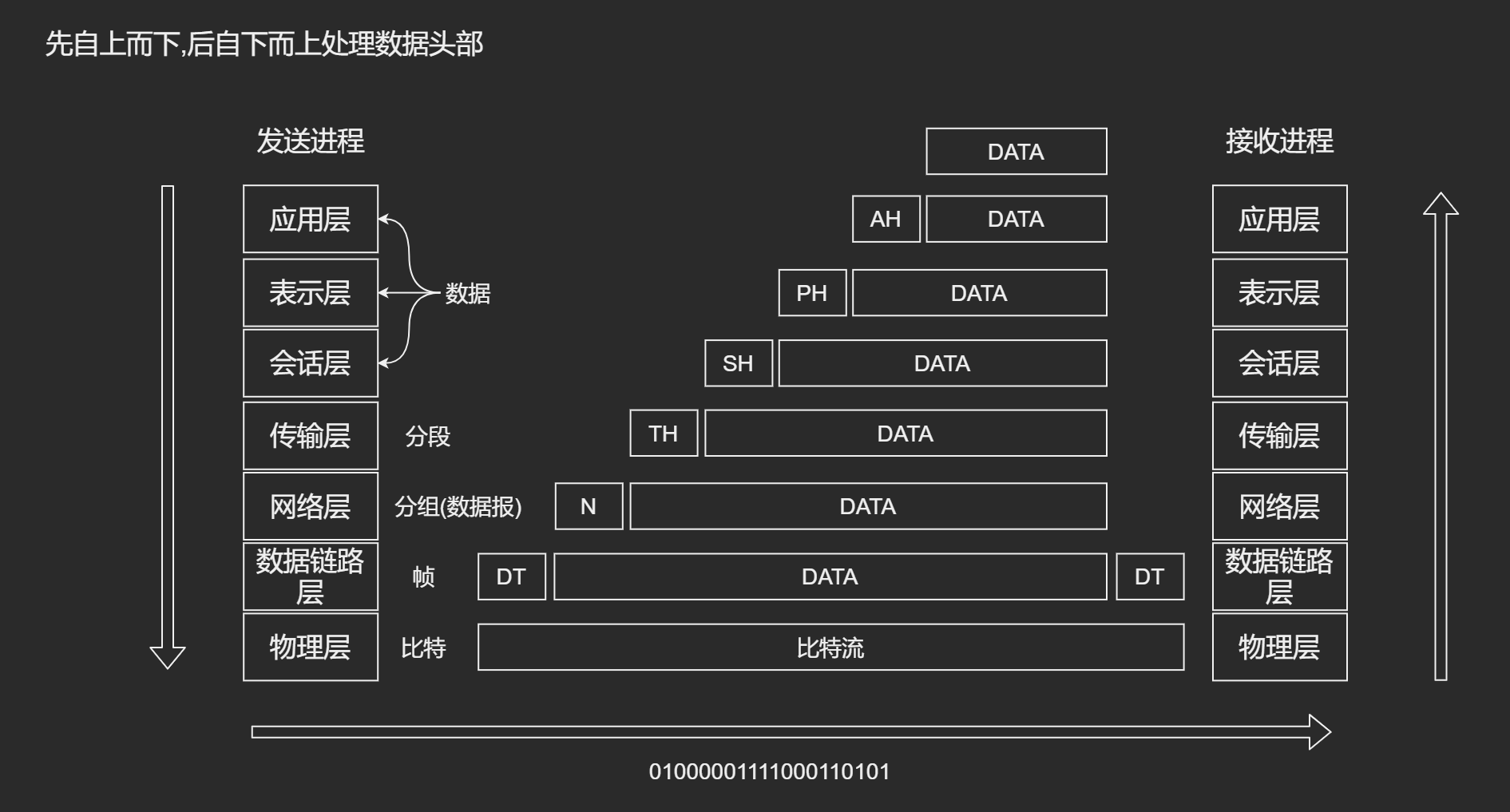
中间窄, 两端大的沙漏形状.
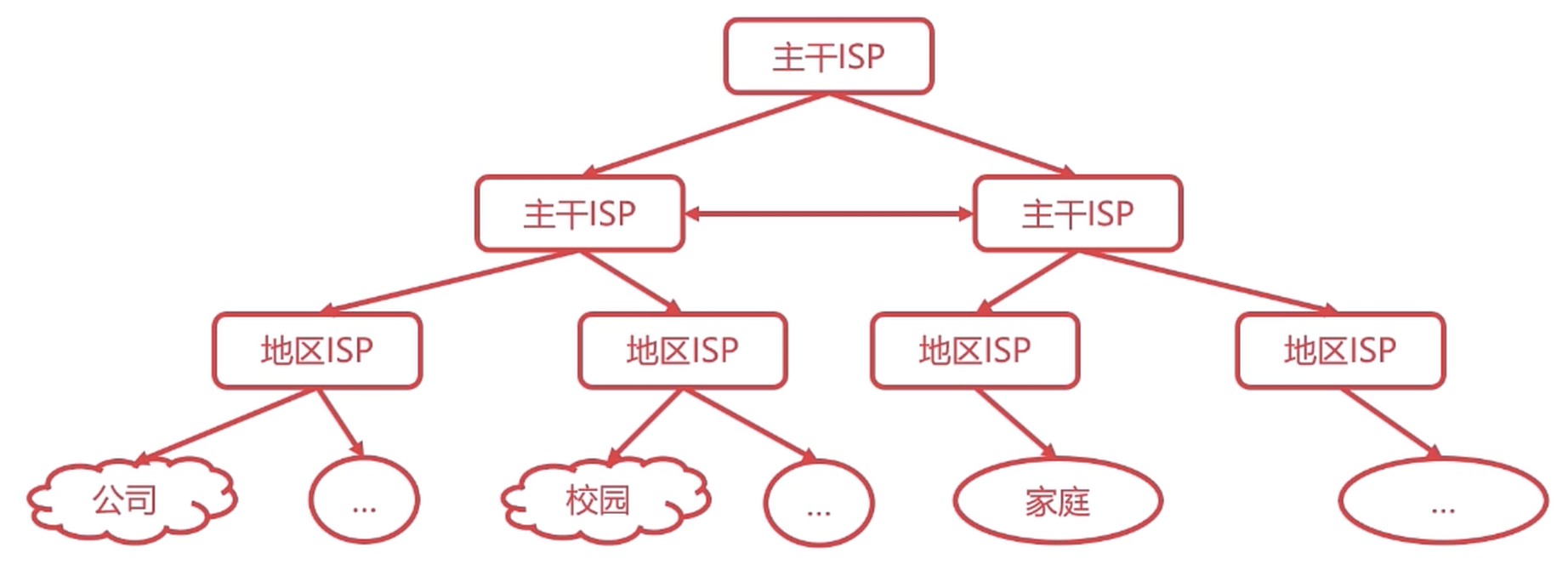
互联网的网络拓扑
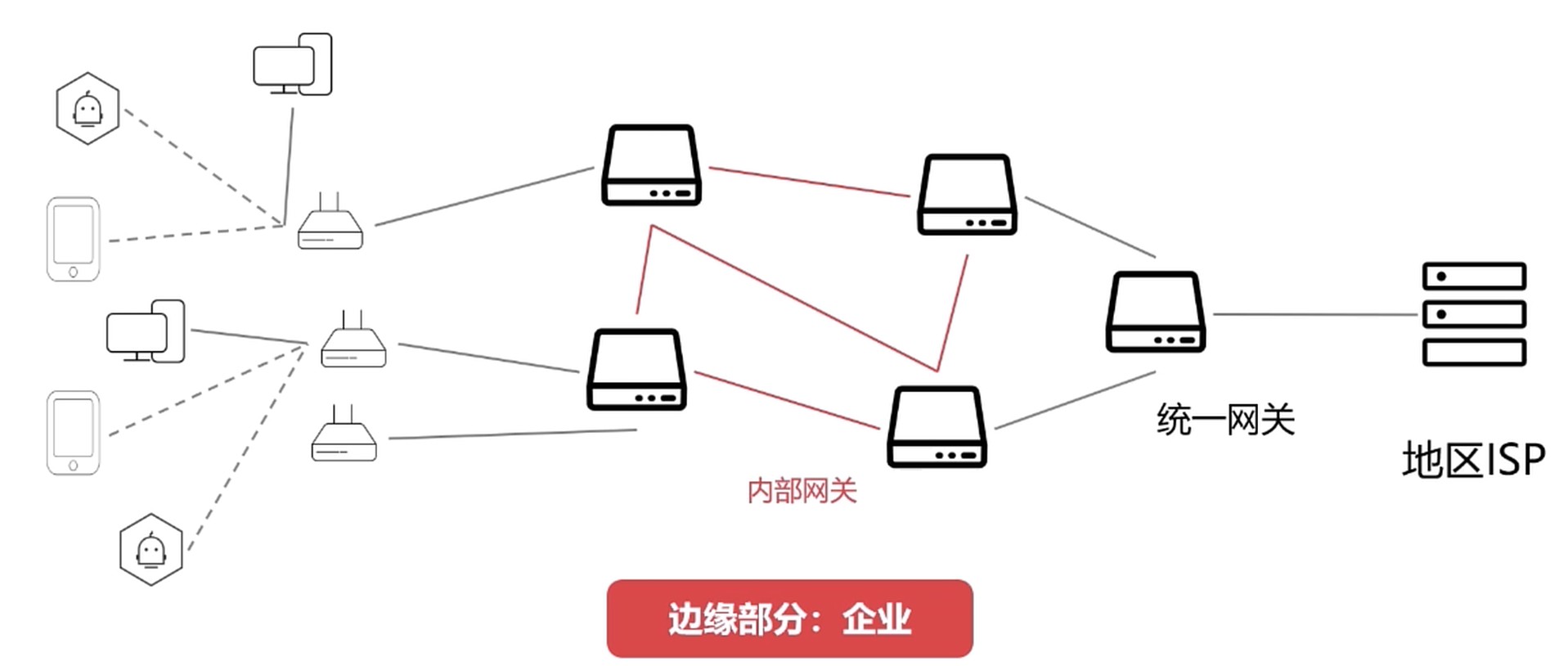
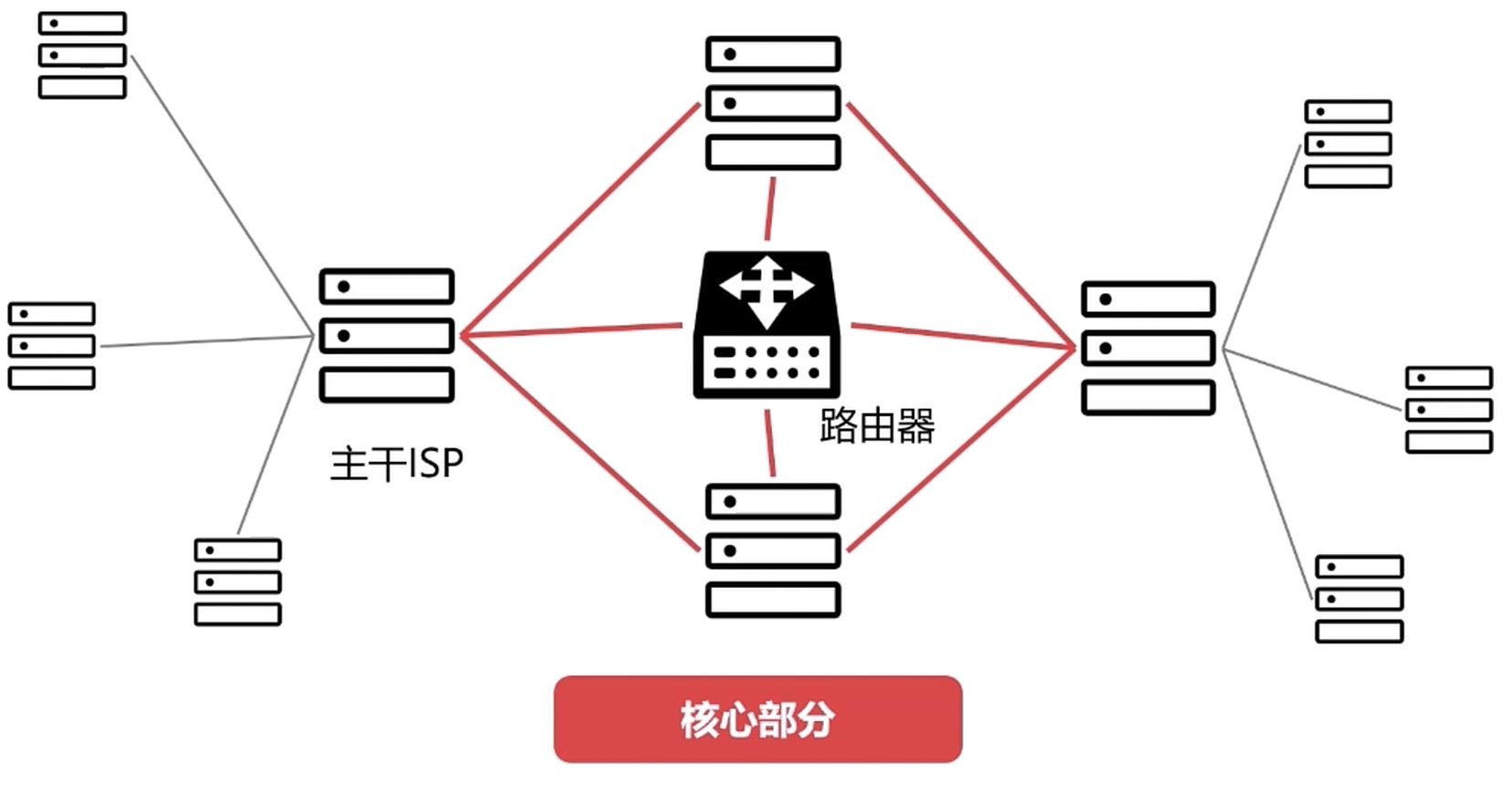
分为 边缘部分 和 核心部分
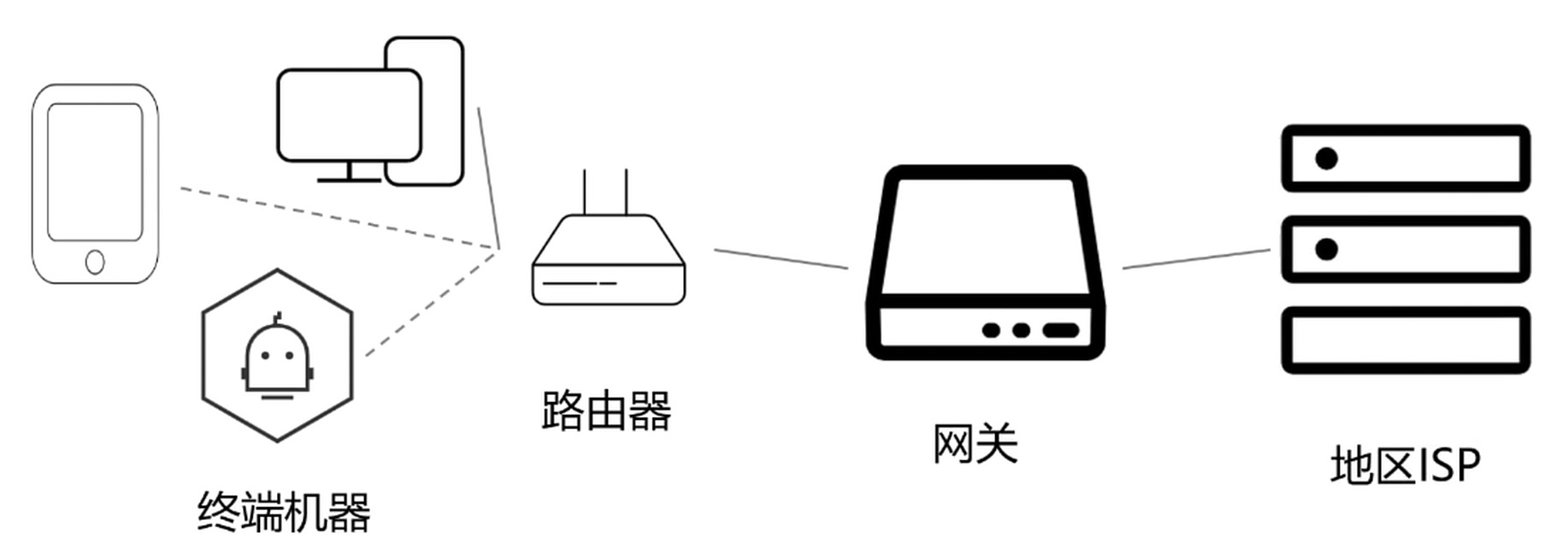
边缘部分–家庭
边缘部分–企业. 内部网关最后收敛, 通过一个网关与区域ISP连接
核心部分
网络拓扑
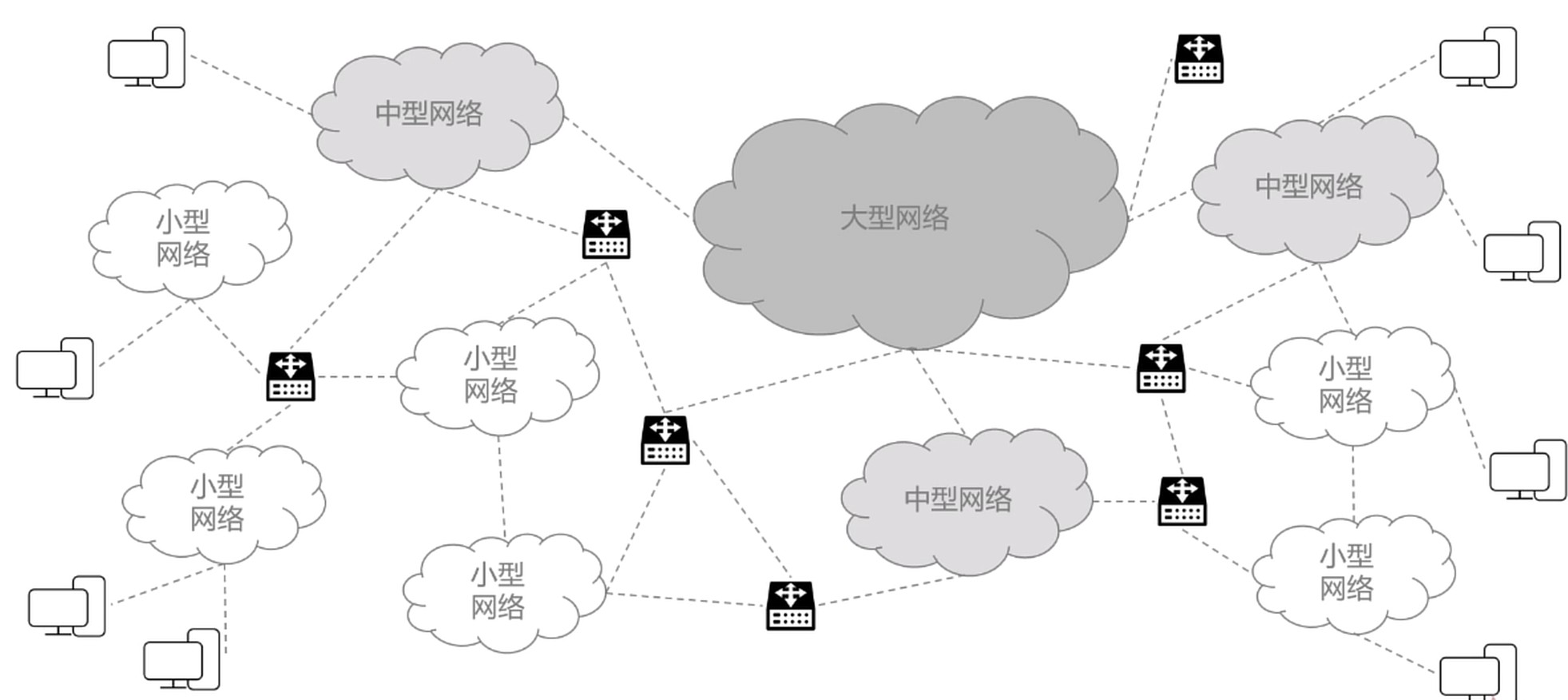
现在互联网络树状结构
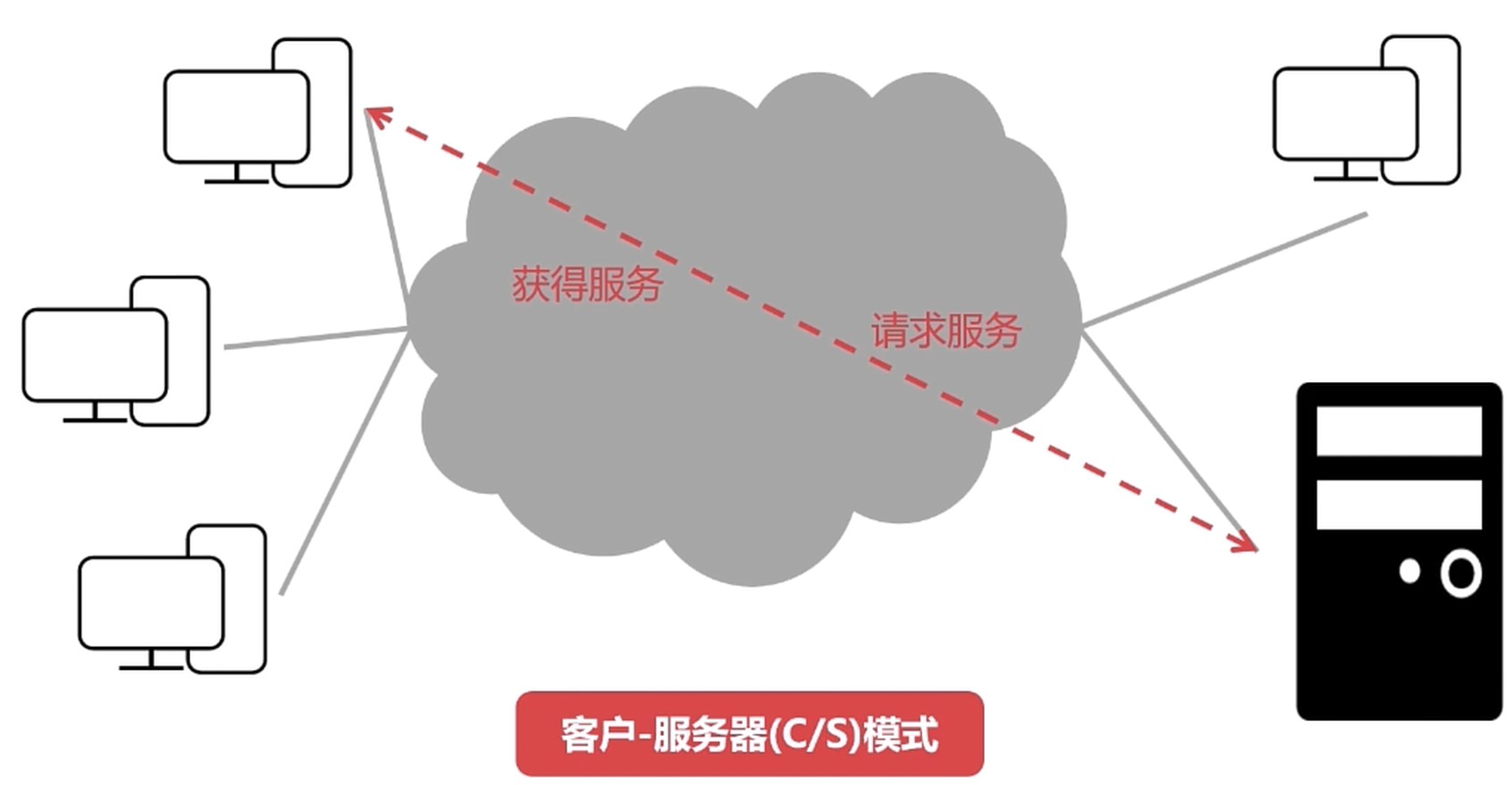
客户-服务(C/S)模式
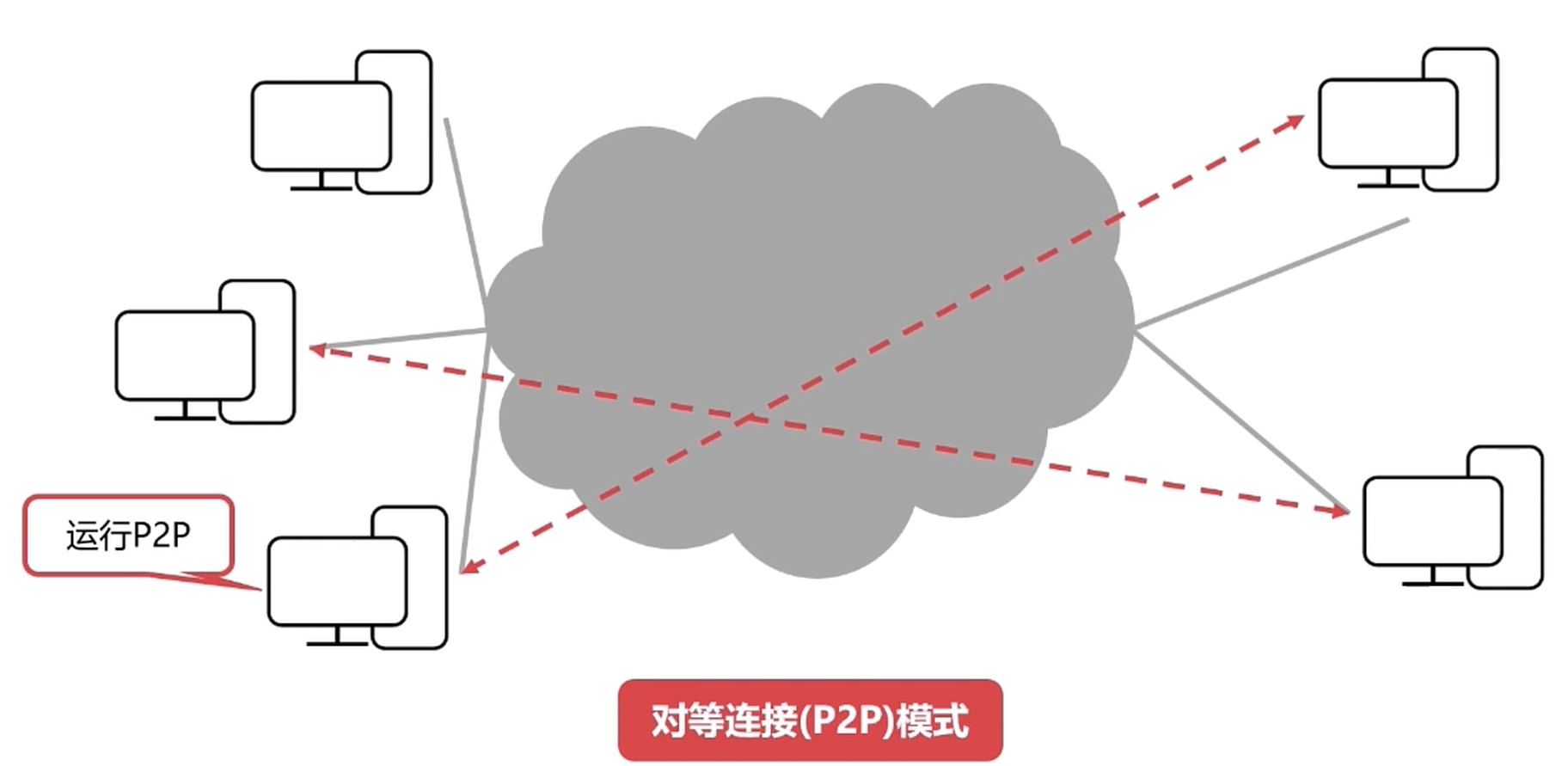
对等连接(P2P)模式
网络性能指标
速率: bps=bit/s
时延
- 发送时延
- 数据长度(bit)/发送速率(bit/s): 受限于计算机网卡
- 传播时延
- 传输路径距离/传播速率(bit/s): 受限于传输介质
- 排队时延
- 数据包在网络设备中等待被处理的时候
- 处理时延
- 数据包到达设备或者目的的机器被处理所需要的时间
总时延 = 发送时延 + 传播时延 + 排队时延 + 处理时延
往返时间 RTT
RTT: Route-Trip Time, 评估网络质量的一项重要指标.
- 表示数据报文在端到端通信中来回一次的时间
- 通常使用 ping 指令来查看 RTT
物理层
- 连接不同的物理设备
- 把链路层的传过来的数据转成比特流, 传输比特流
连接介质
- 双绞线

- 同轴电缆
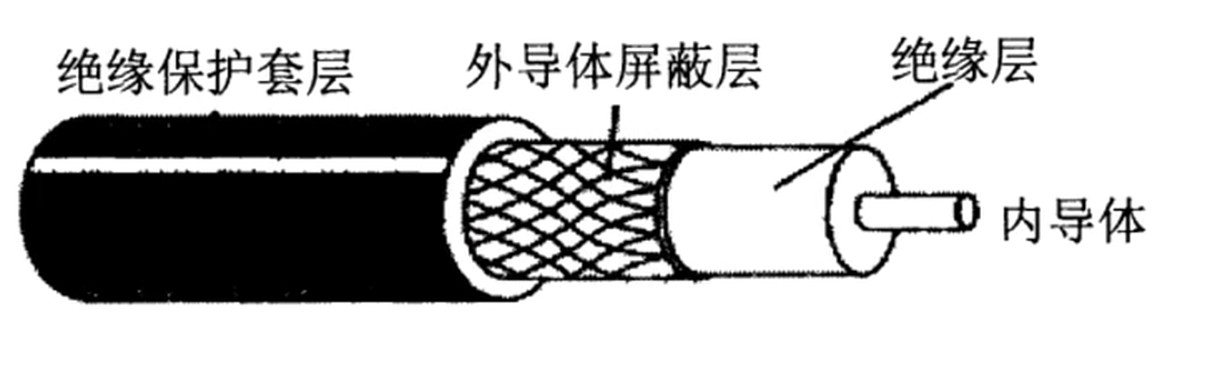
- 光纤
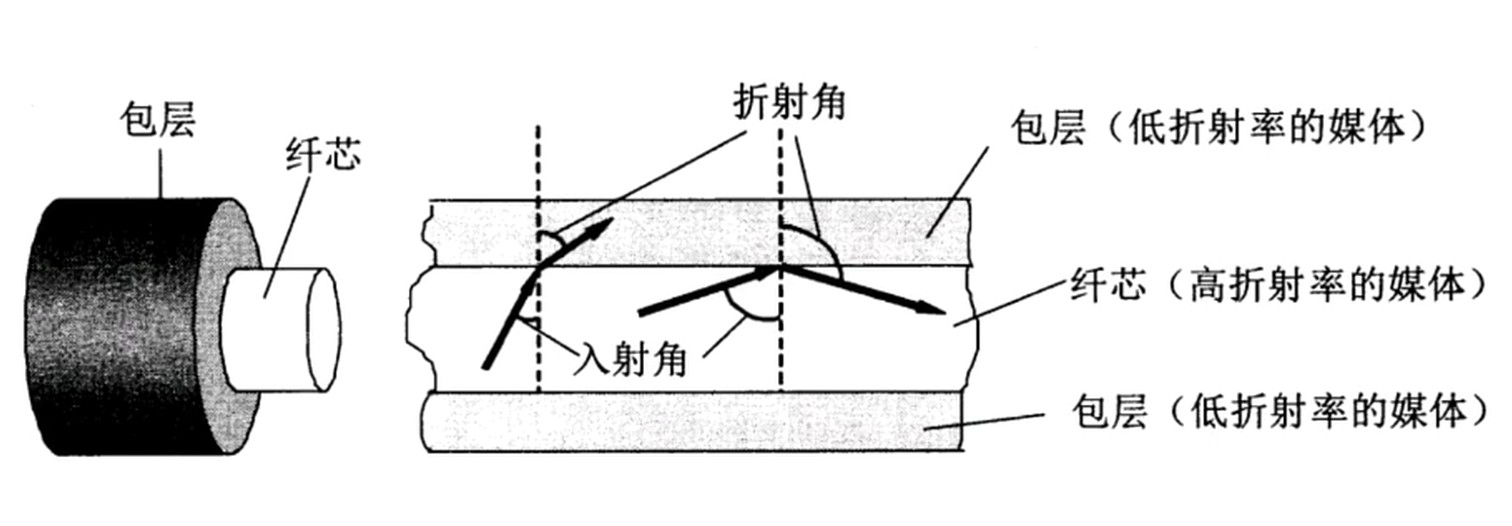
- 无线
- 红外线
- 激光
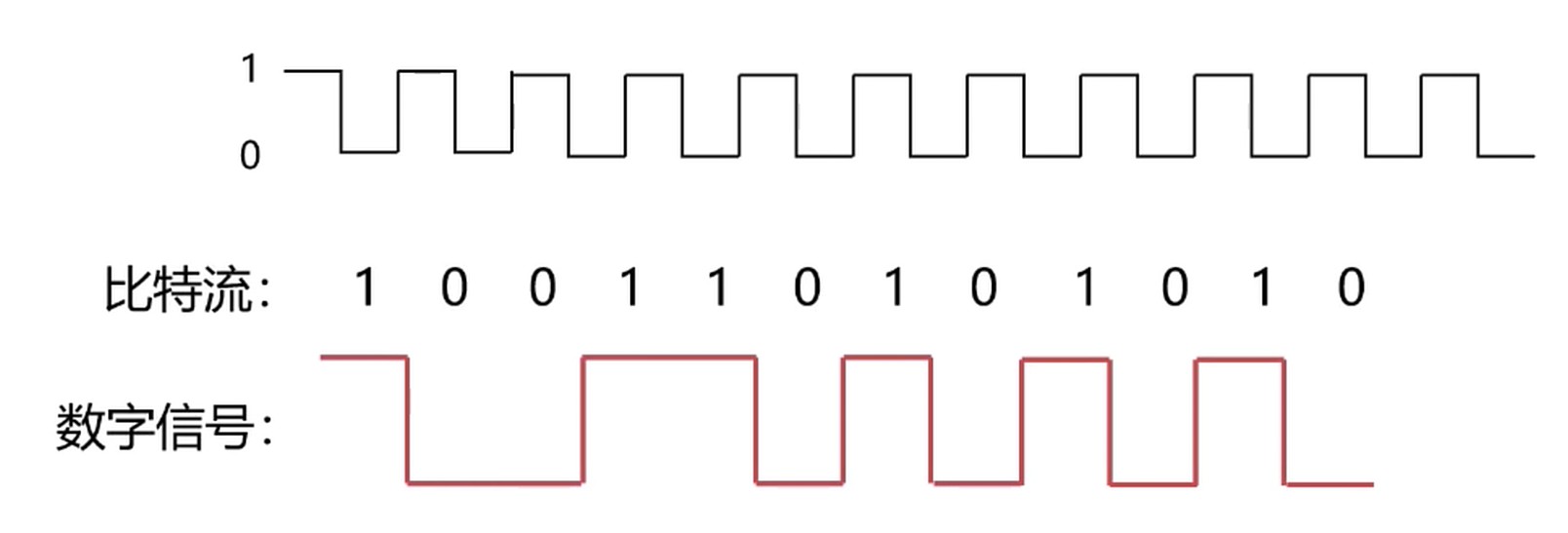
比特流, 使用高低电平来表示0和1.
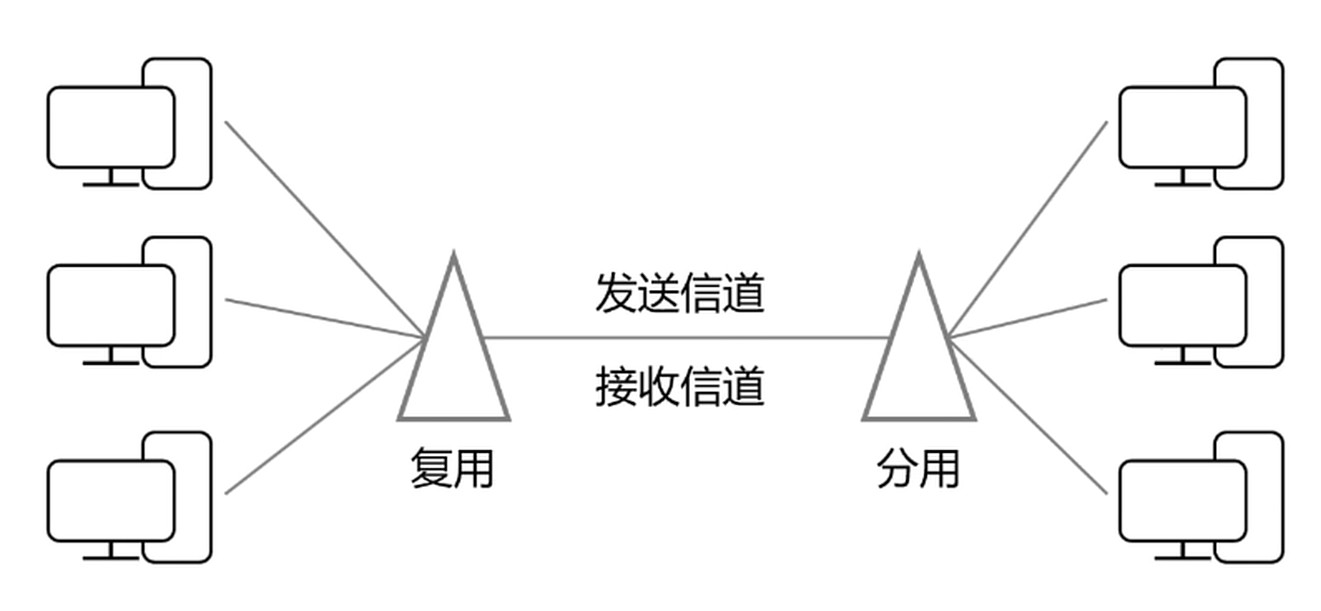
信道
- 信道是往一个方向传送信息的媒体.
- 一条通信电路包含接收信道和一个发送信道.

分类
- 单工通信信道
- 只能一个方向通信, 没有反方向反馈的信道
- 无线电视, 无线收音机等
- 只能一个方向通信, 没有反方向反馈的信道
- 半双工通信信道
- 双方都可以发送和接收信息
- 不能双方同时发送, 也不能同时接收
- 全双工通信信道
- 双方都可以发送和接收信息
- 双方可以同时发送, 同时接收
分用-复用技术
提高信道的利用效率
- 频分复用
- 时分复用
- 波分复用
- 码分复用
链路层
- 封装成帧
- 透明传输
- 差错检测
封装成帧
- “帧”是数据链路层数据的基本单位
- 发送端在网络层的一段数据前后添加特点标记形成”帧”
- 接收端根据前后特定标记识别出”帧”

物理层表示的是0和1

透明传输
- “透明”在计算机领域是非常重要的一个术语
- “一种实际存在的事物却看起来不存在一样”
- “即是控制字符在帧数据中, 但是要当做不存在去处理”
帧数据中可能出现控制字符
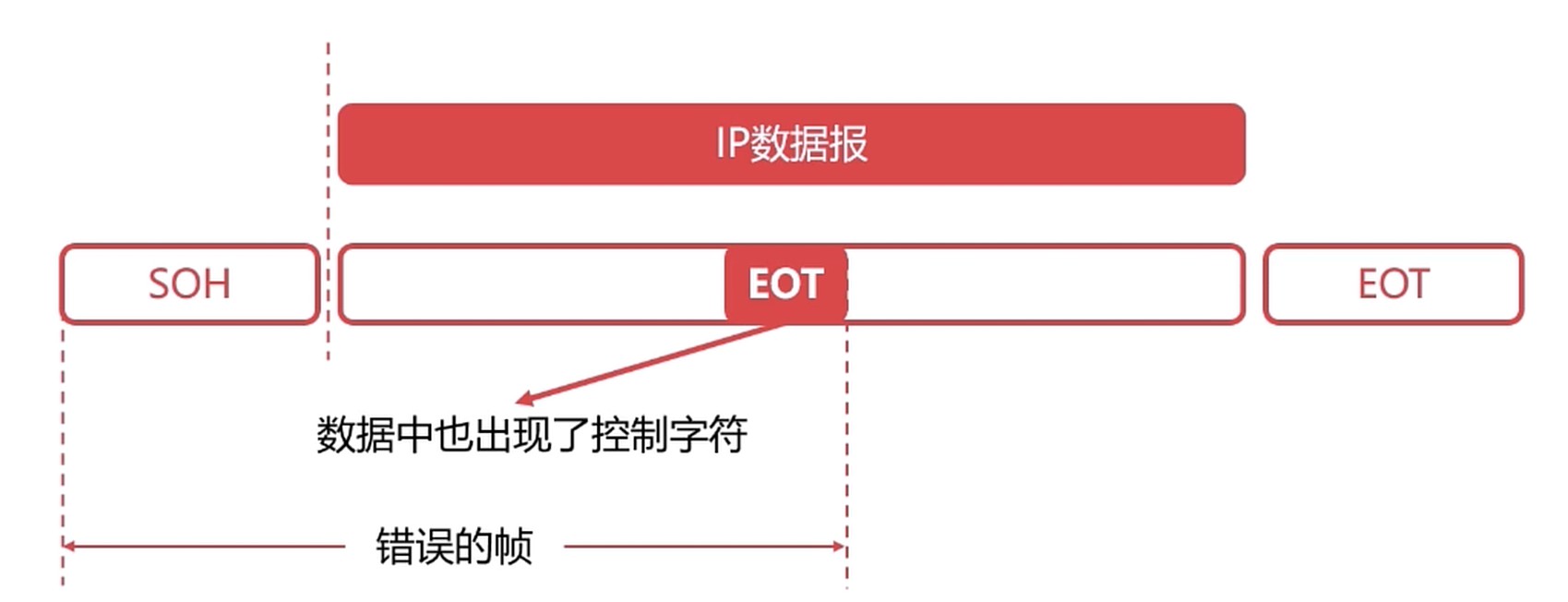
解决方案: 加个转义字符, 如果是转义字符就加多个转义字符.

差错检测
- 物理层只管传输比特流, 无法控制是否出错
- 数据链路层负责起”差错检测”的工作
奇偶校验码
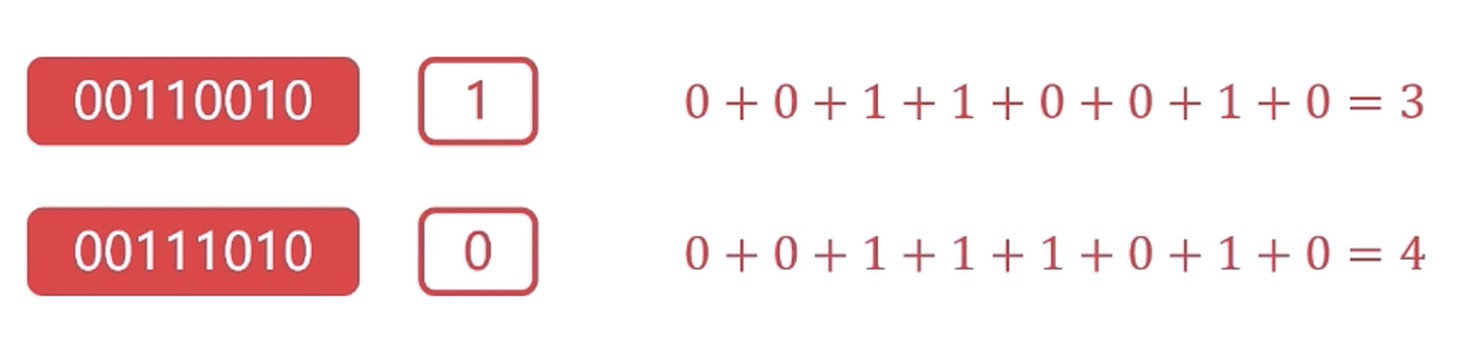
局限: 如果出现的错误数是偶数的话, 就检测不到错误.
循环冗余校验码 CRC
- 一种根据传输或保存的数据而 产生固定位数校验码 的方法
- 检测数据传输或保存后可能出现的问题
- 生成的数据计算出来并且附加到数据后面
方法一: 模”2”除法
- 二进制下的除法
- 与算术除法类似, 但除法不错位, 实际是”异或”操作
异或: 两个比特位不同则为1
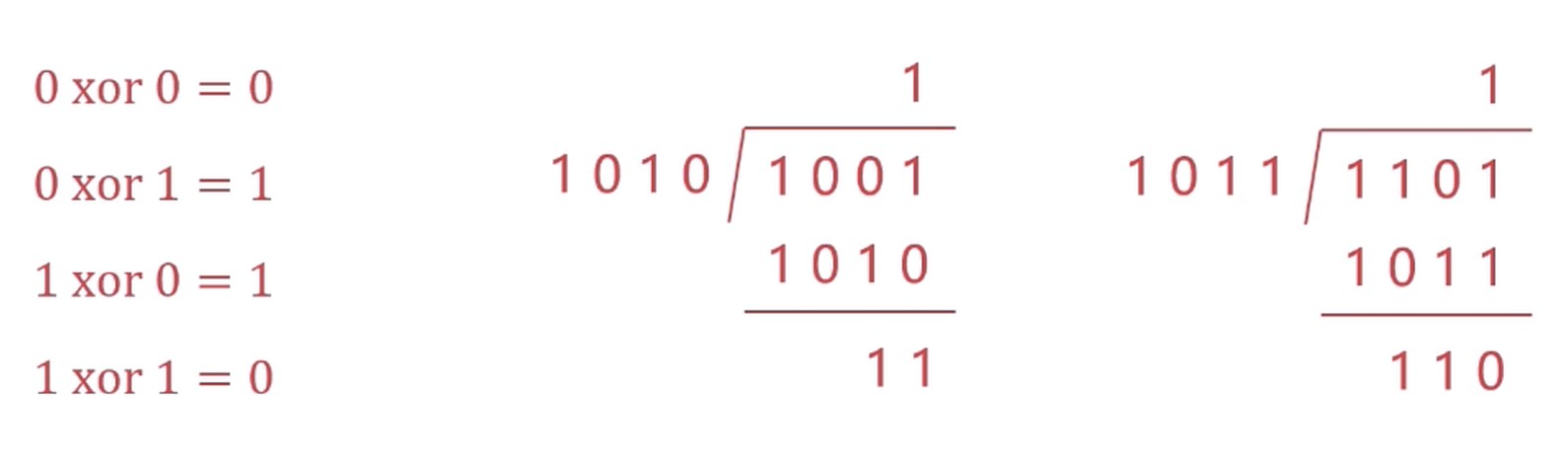




接收端接收到数据除以G(x)的位串, 根据余数判断是否出错
- CRC 的错误检测能力与位串的阶数r有关.
- 数据链路层只进行数据的检测, 不进行纠正, 只要有错, 就丢弃掉.
最大传输单元 MTU
MTU(Maximum Transmission Unit)
- 数据链路层的数据帧也不是无限大的.
- 数据帧的长度受MTU限制.
- 数据帧过大或过小都会影响传输的效率.
以太网的MTU一般是1500字节.
路径MTU
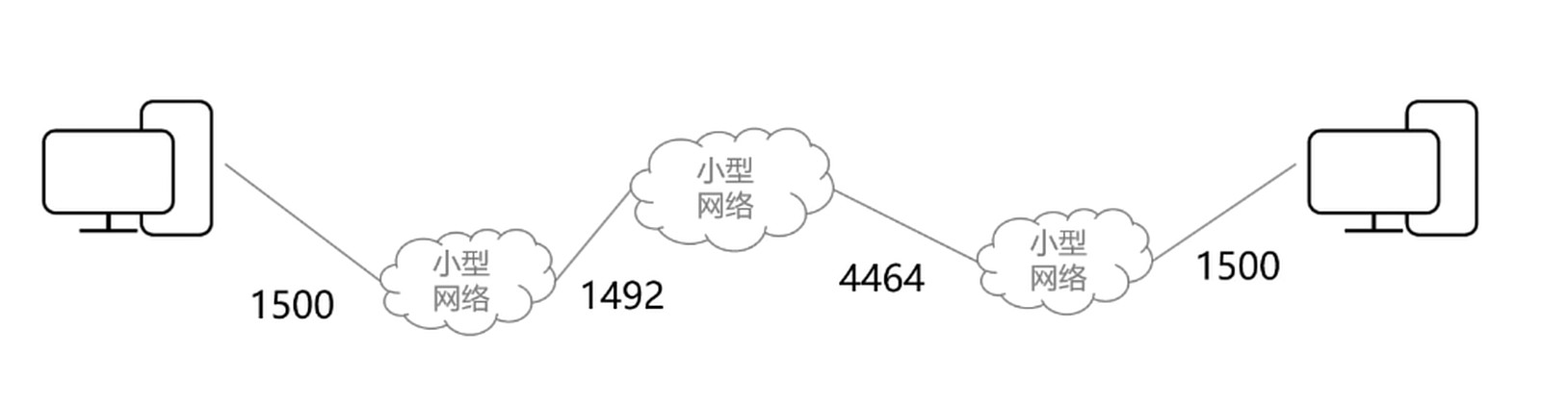
整个链路的MTU是被最小的MTU限制(木桶效应).
以太网协议
- Ethernet 是一种广泛使用的局域网技术
- 一种应用于数据链路层的协议
- 可以完成相邻设备的数据帧传输
帧的组成格式
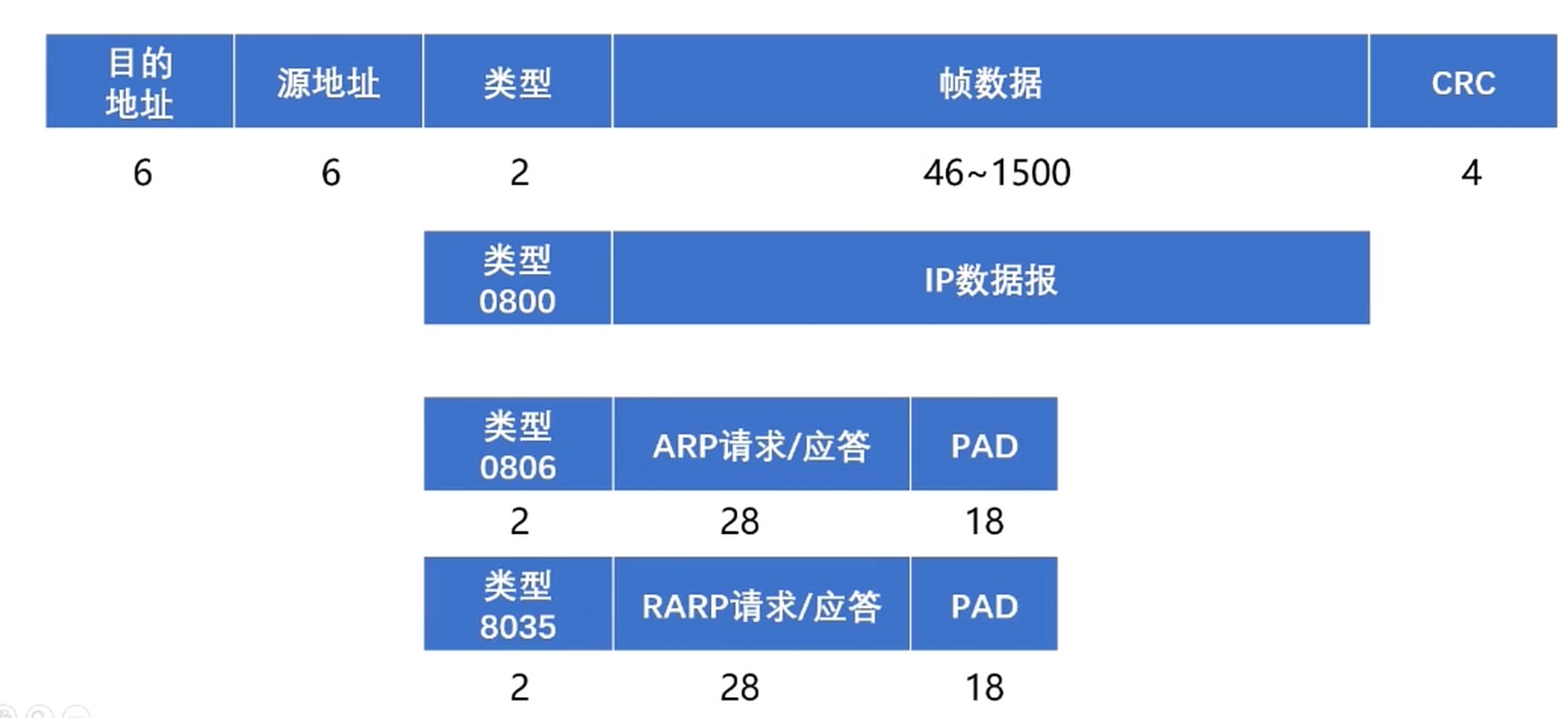
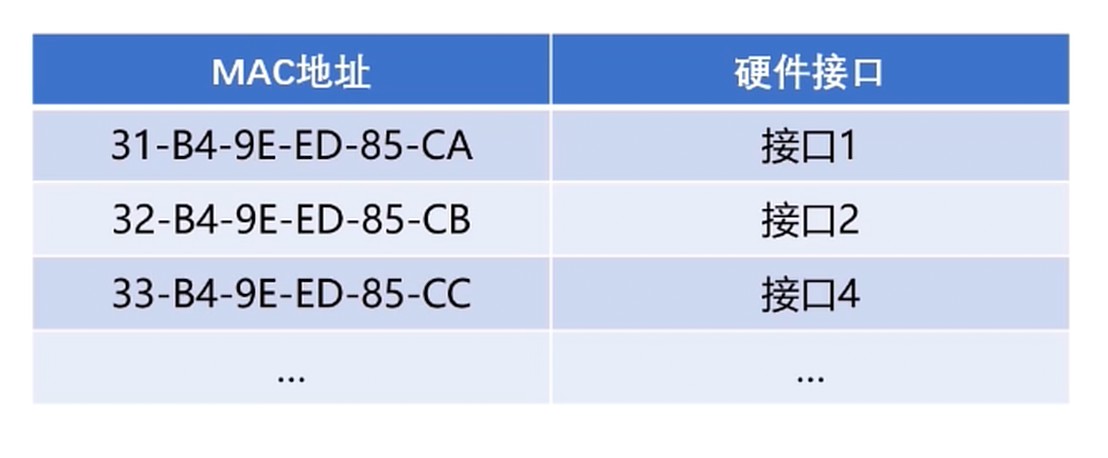
mac地址表
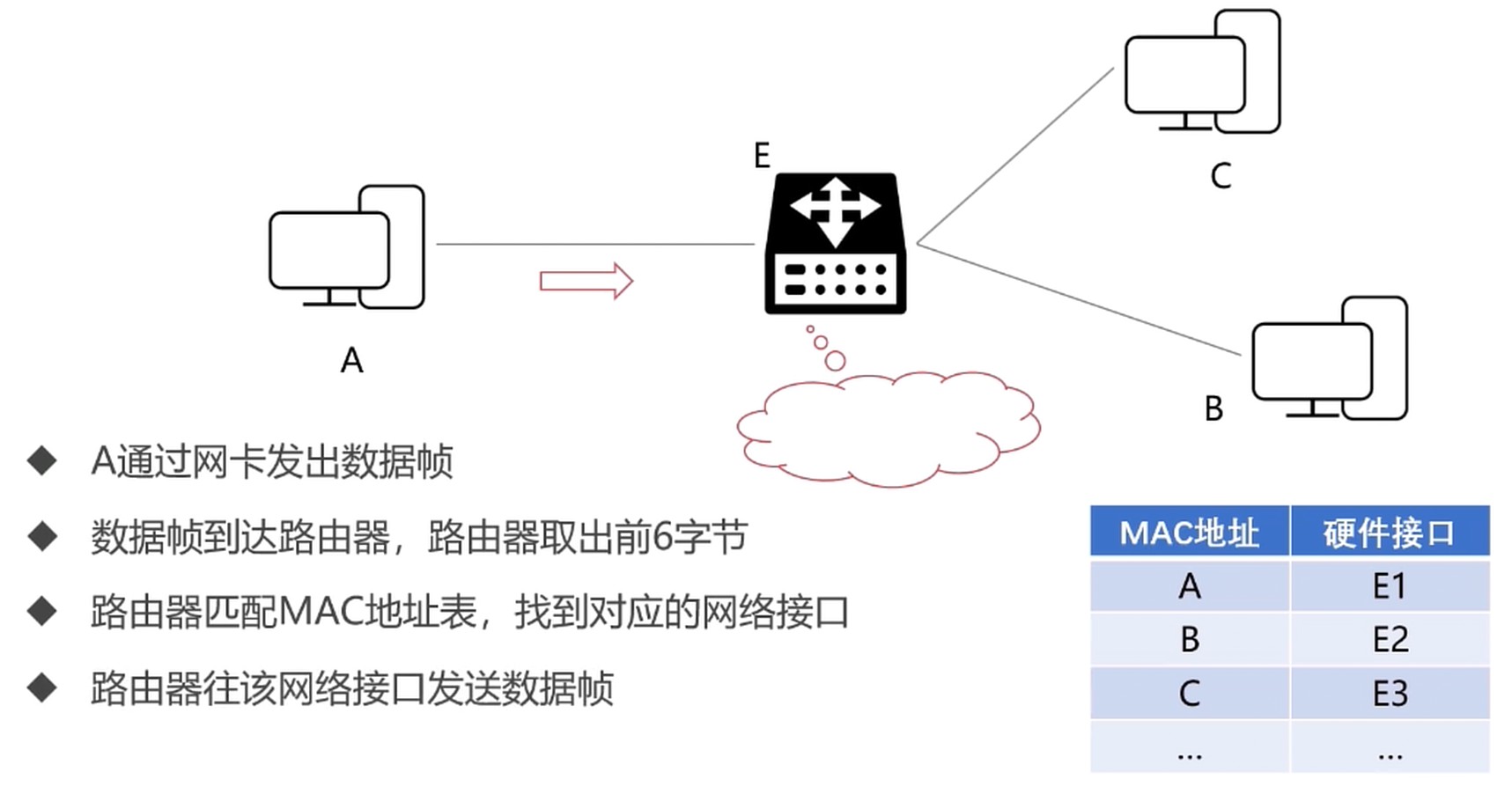
以太网协议
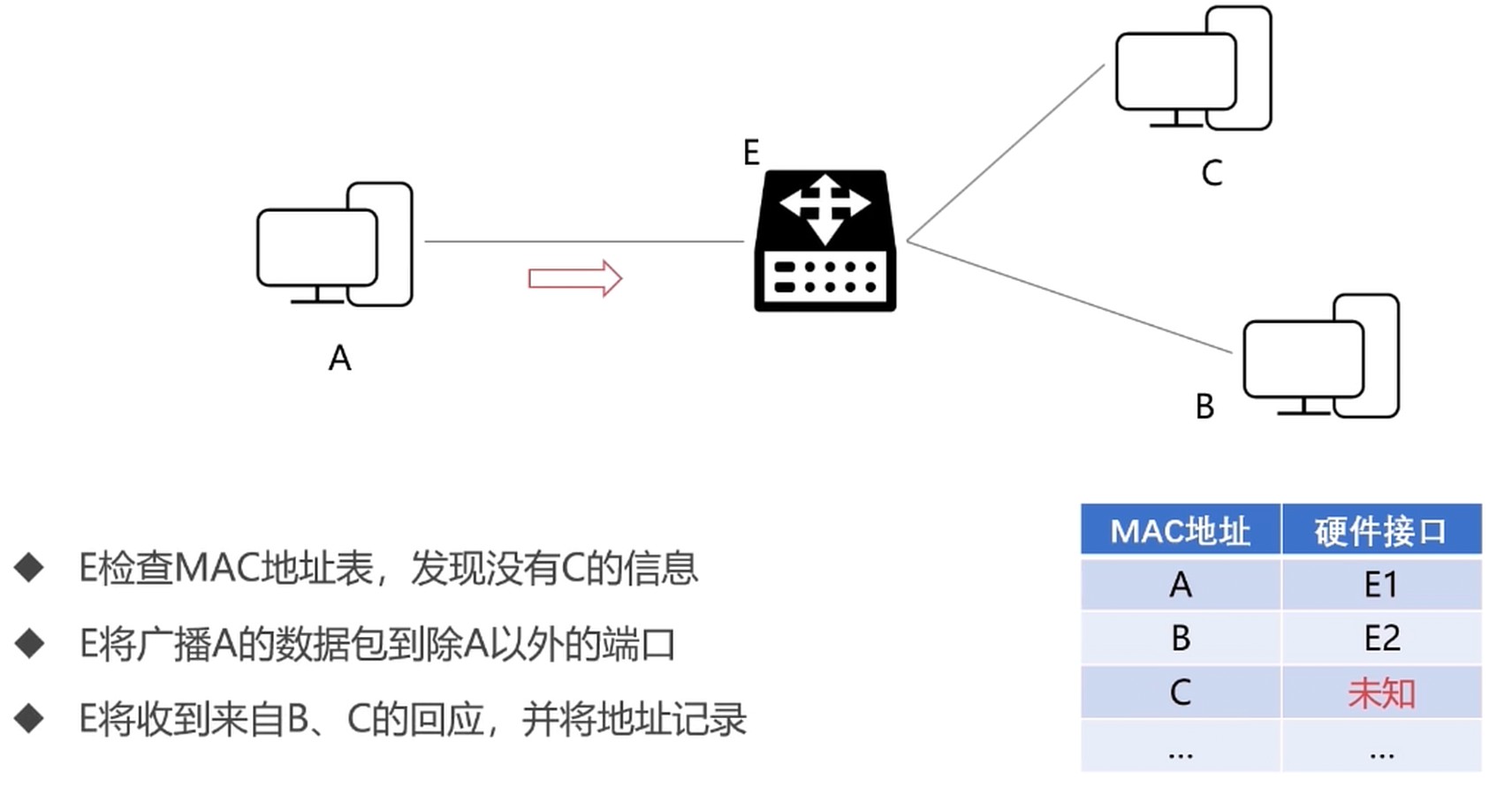
如果 MAC表中没有找到硬件接口, 会进行广播.
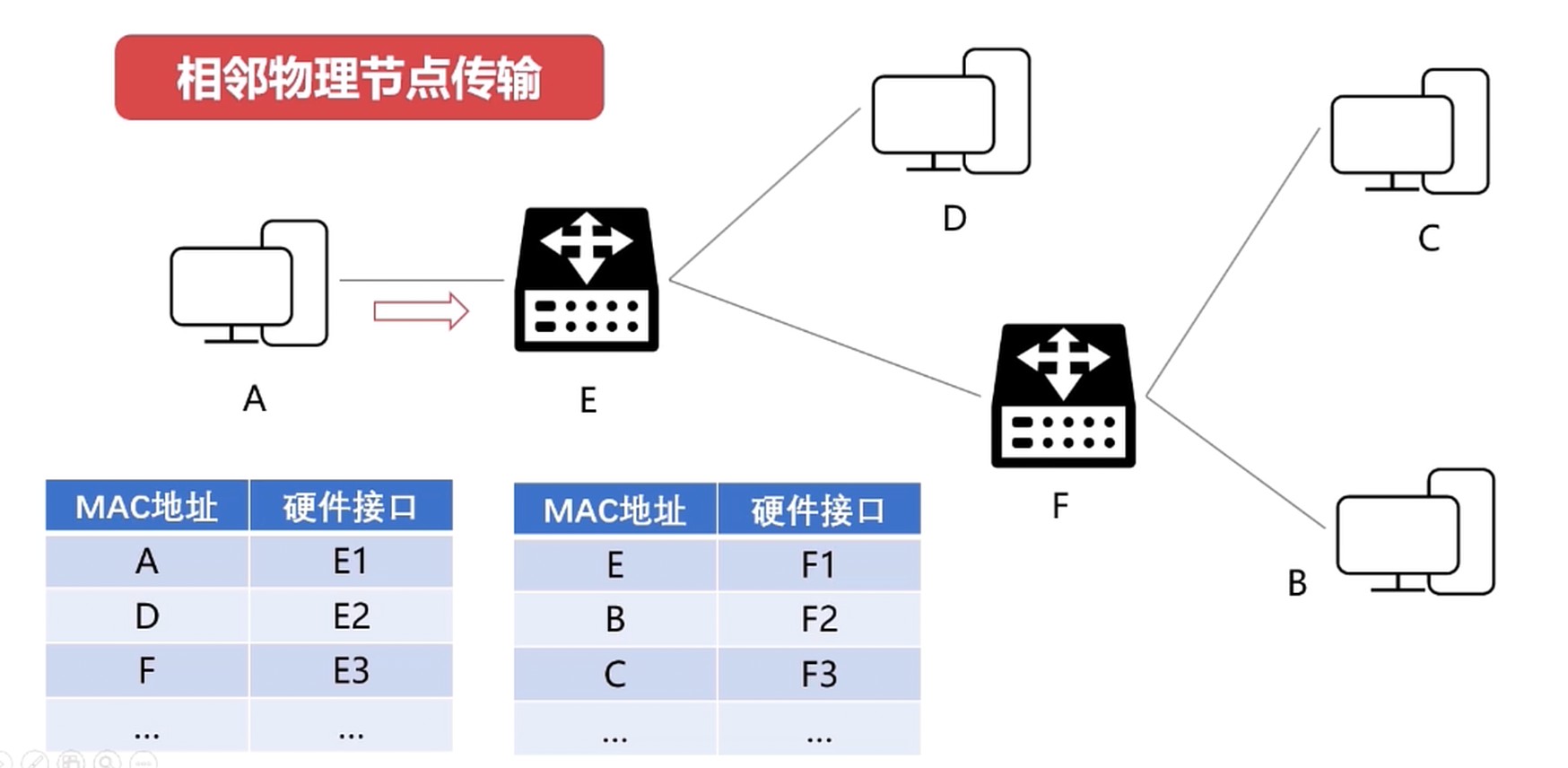
相邻物理节点传输
MAC 地址
MAC地址, 也就是物理地址, 硬件地址.
每个设备都拥有唯一的MAC地址.
MAC地址共48位, 使用十六进制表示.
Windows 下使用 ipconfig /all 查看.
网络层
IP协议
虚拟互连网络
实际的计算机网络是错综复杂的
物理设备通过使用IP协议, 屏蔽了物理网络之间的差异
当网络的主机使用IP协议连接时, 则无需关注网络细节
IP协议使得复杂的实际网络变成一个虚拟互连的网络
IP协议使得网络层可以屏蔽底层细节而专注网络层的数据转发
IP协议解决了在虚拟网络中数据报传输路径的问题
IP协议格式
在数据链路层, 有MAC地址就可以进行数据帧的传输了.

- 长度为32位, 常分成4个8位, 42亿个左右
- 常使用点分十进制来表示

IP协议格式
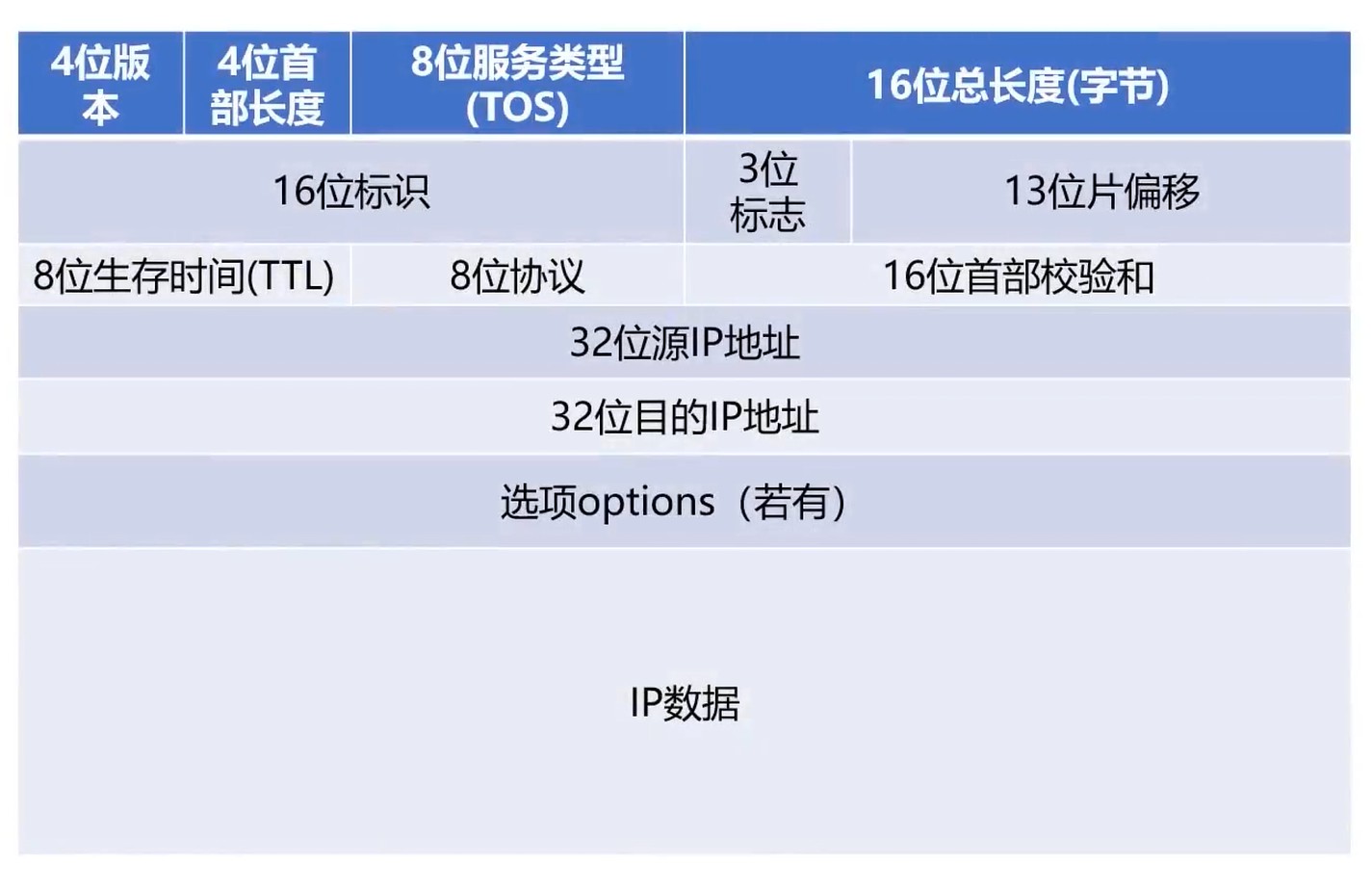
所以一个IP协议的头部至少有20字节的长度. 一行4字节, 必须的存在有5行.
版本: 占四位, 通信双方版本必须一致, 当前是4, 也就是IPv4, 之后会是IPv6
首部长度: 占4位, 最大数值为15, 表示IP首部长度. 单位是”32位字”(4字节), 也就是首部最大长度是60字节.
总长度: 占15位, 最大数值是 65535, 表示的是IP数据报总长度(IP首部+IP数据). 这个数据是比 MTU 高的, 所以传输䣌时候会进行分片.
TTL: 占8位, 表明IP数据报文在网络中的寿命, 每经过一个设备, TTL减1, 当TTL=0时, 网络设备必须丢弃该报文. 避免网络数据无限地进行传输.
协议: 占8位, 表面IP数据所携带地具体数据是什么协议的(如: TCP, UDP等)

首部校验和: 16位, 校验IP首部是否出错.
源IP地址: 发送数据报机器的地址
目的IP地址: 数据报要到达的IP地址
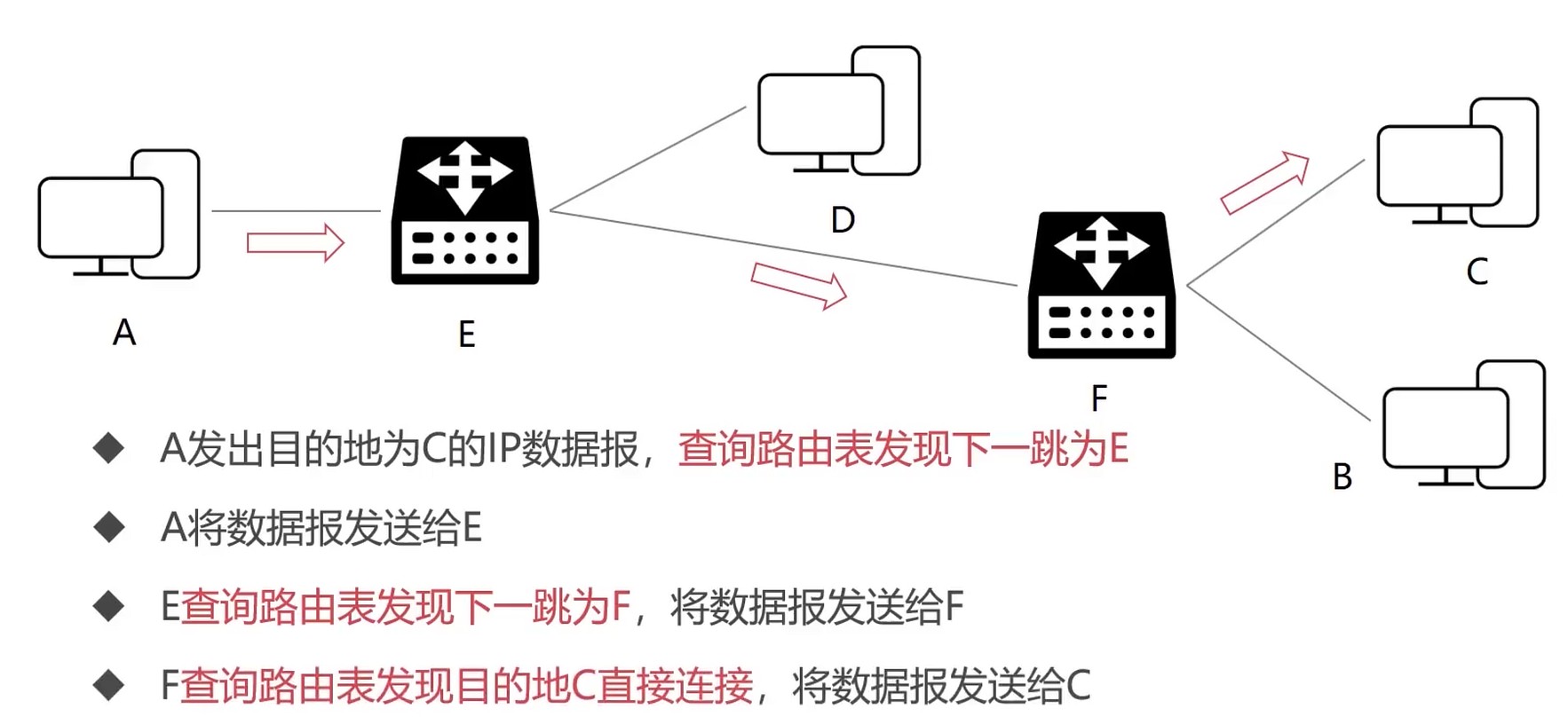
IP协议转发

逐跳: hop by hop
路由表

计算机或者路由器都拥有路由表.
转发流程
结合数据链路层看
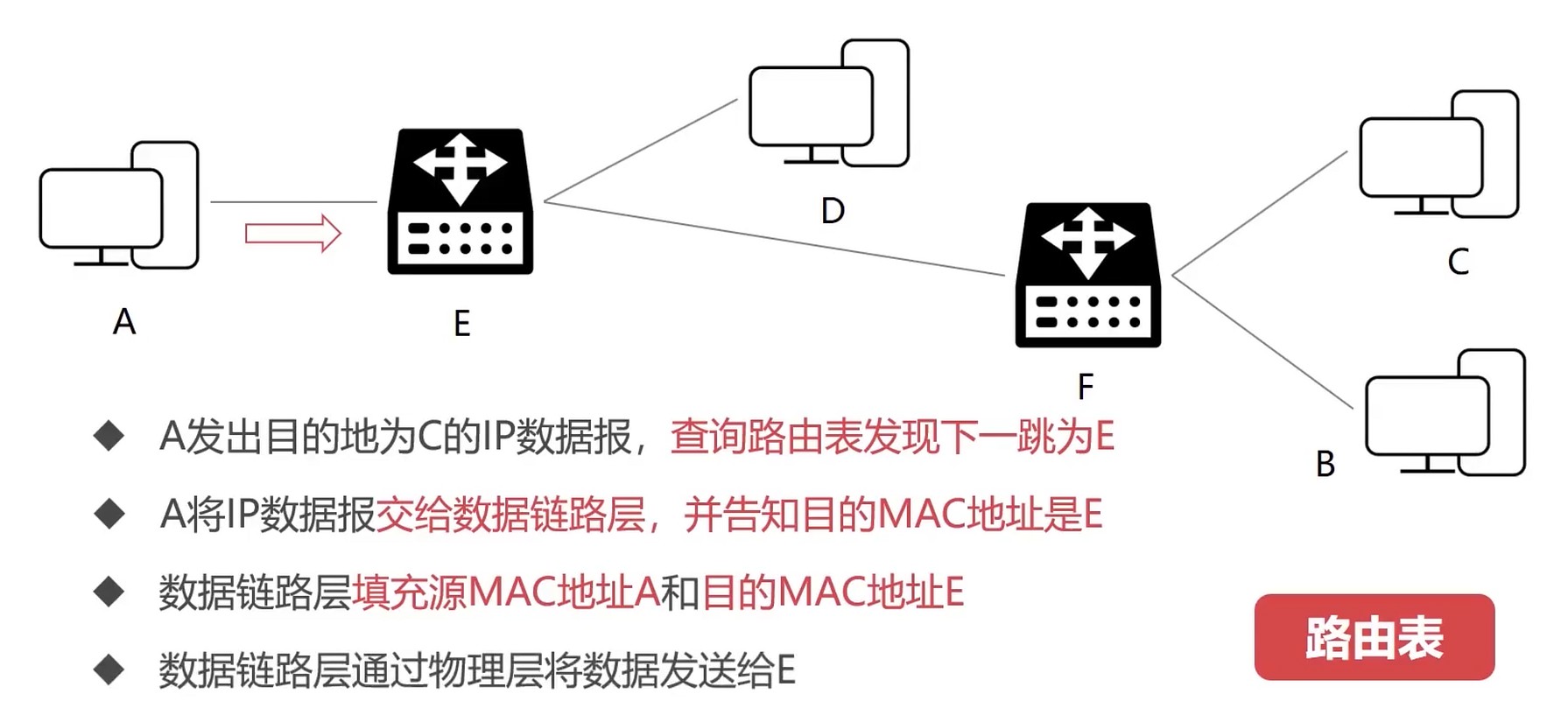
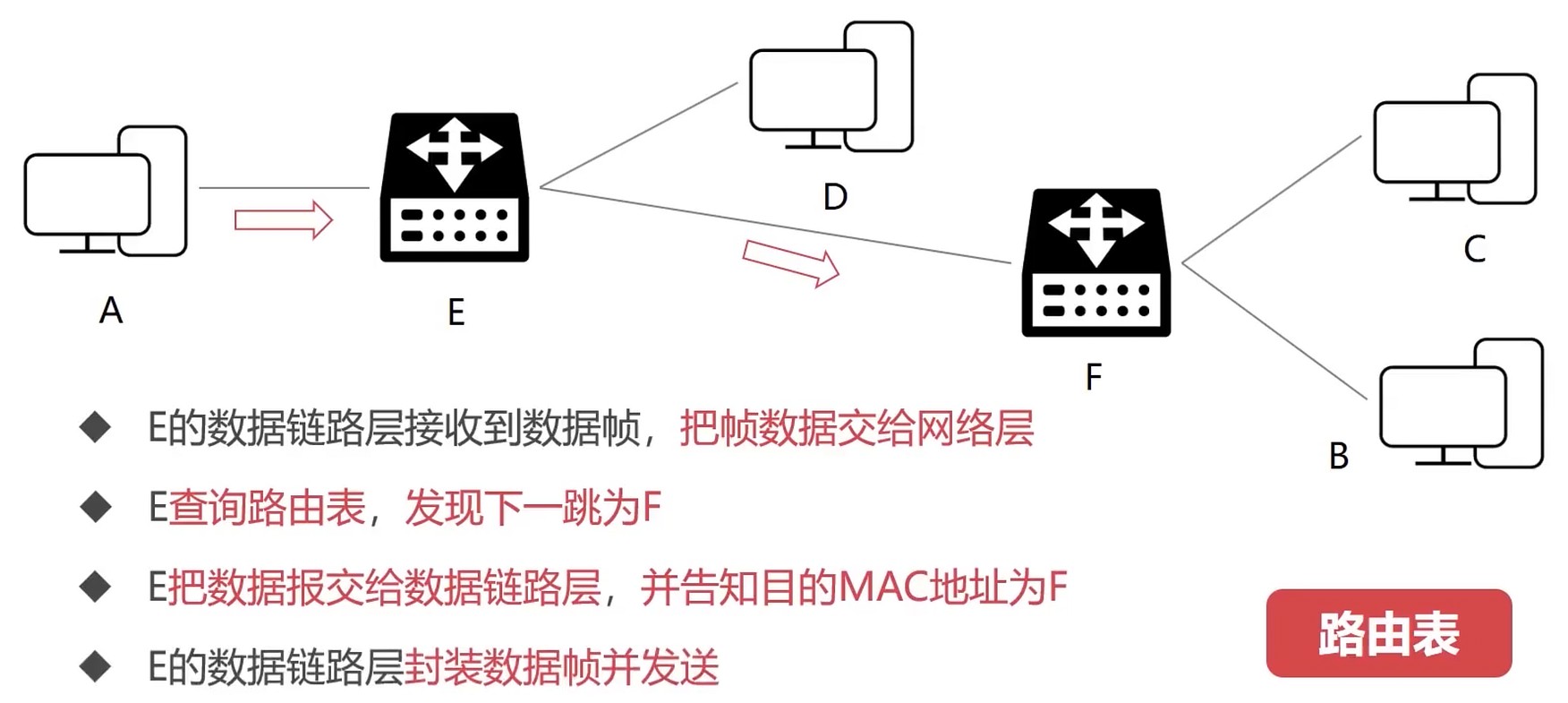
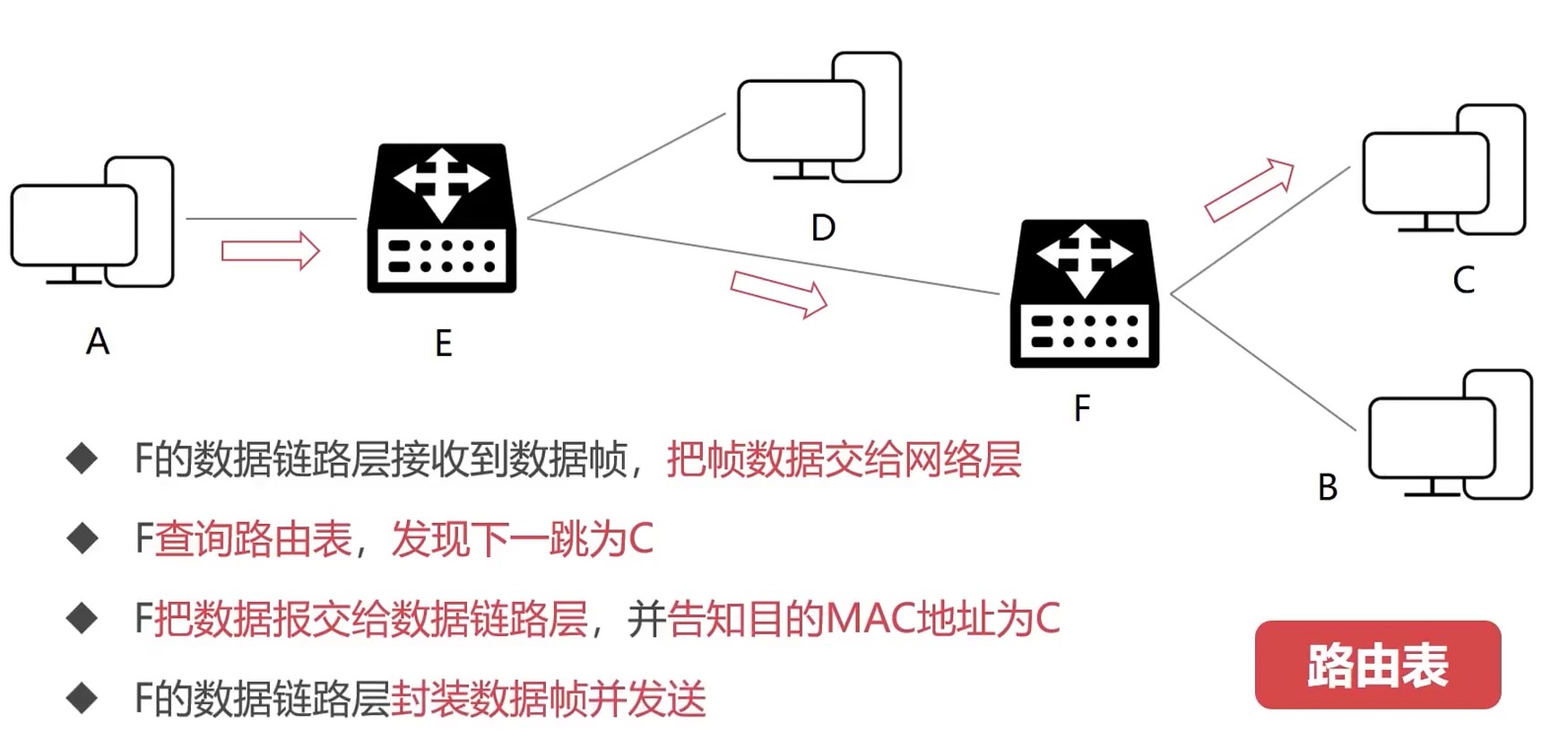
- 数据帧每一跳MAC地址都在变化
- IP数据报, 每一跳的IP地址始终不变
- A通过ARP协议知道MAC地址
ARP协议与RARP协议
- ARP(Address Resolution Protocol) 地址解析协议
把 网络层 32位的IP地址 转换成 数据链路层 48位的MAC地址.
ARP缓存表
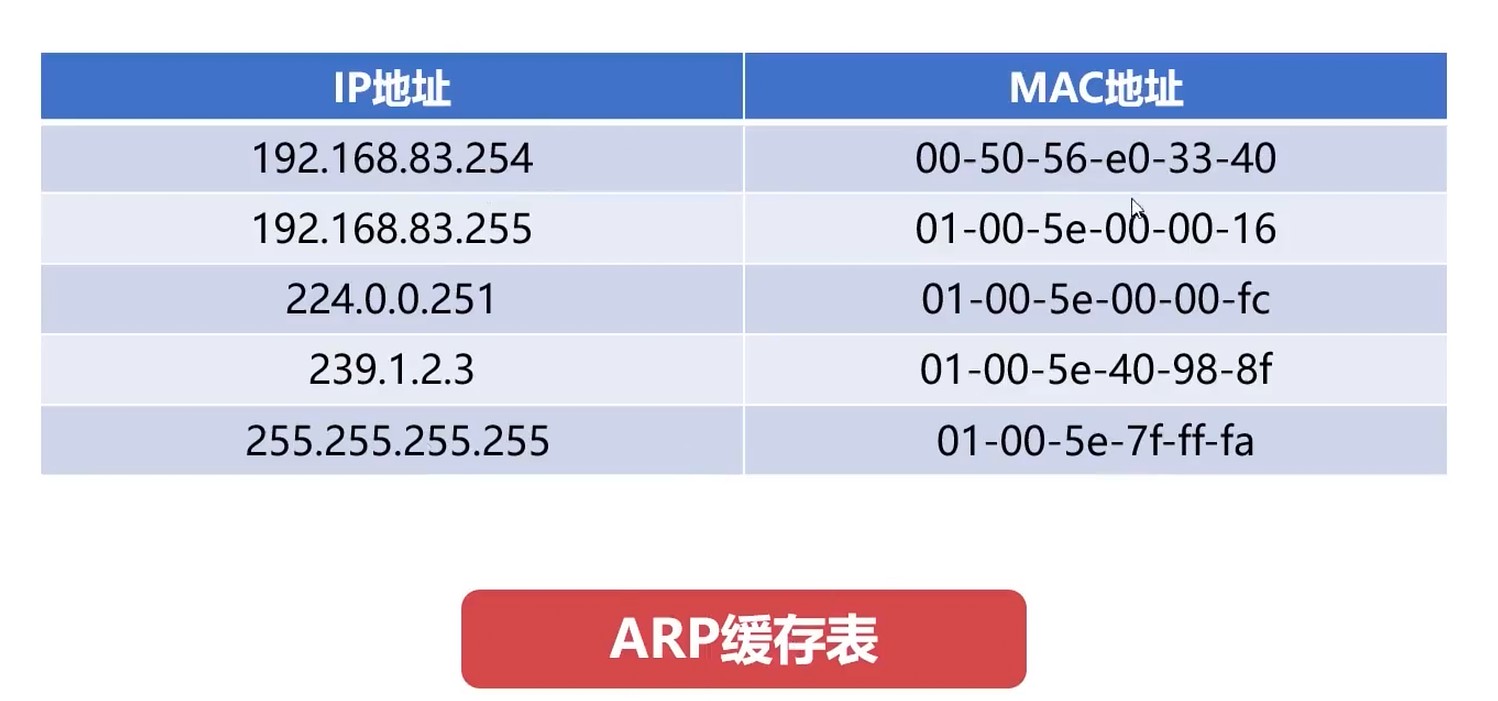
- ARP缓存表缓存有IP地址和MAC地址的映射关系
- ARP缓存表缓存没有IP地址和MAC地址的映射关系
- 通过广播询问
- ARP缓存表中的记录不是永久有效的, 有一定的期限
# 查看 arp 缓存表
# windows
arp -a
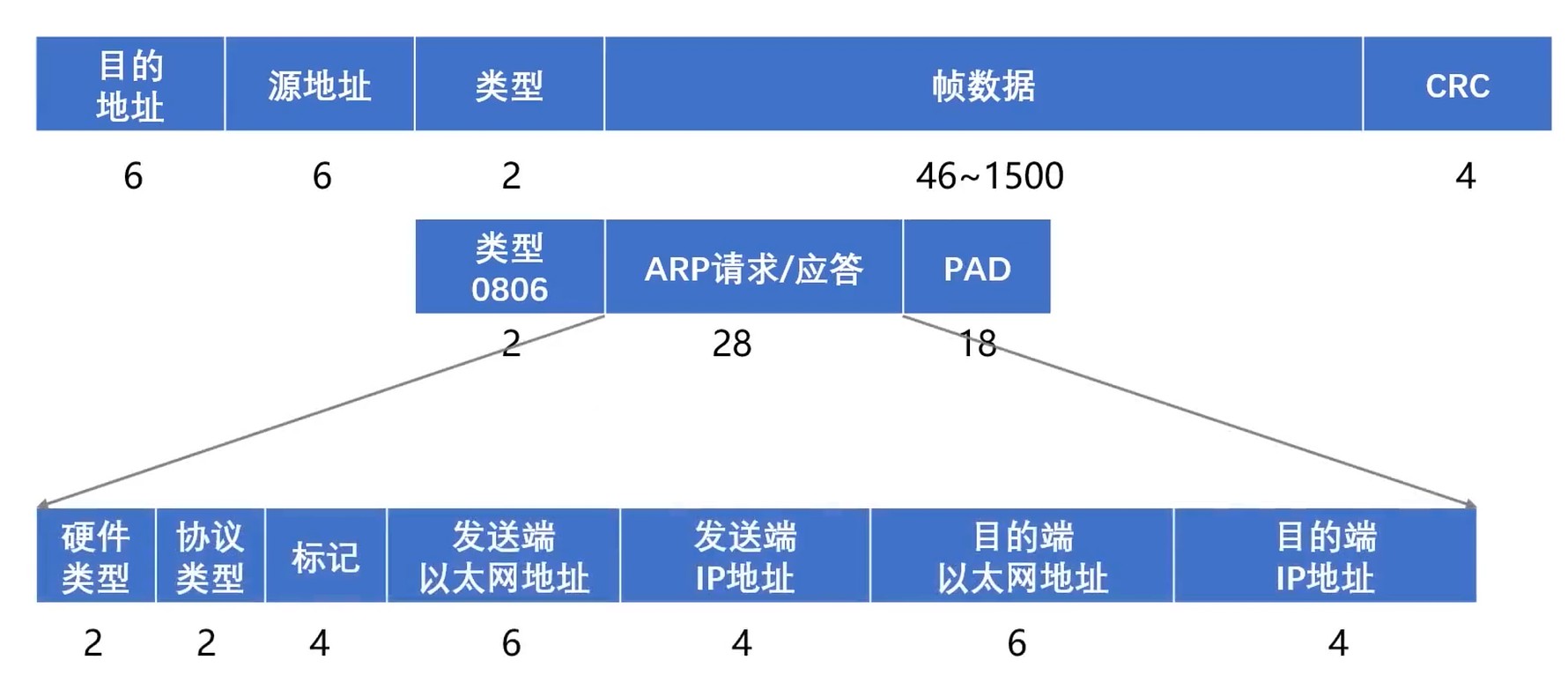
因为使用了 IP地址, 所以属于 网络层 的内容.
- RARP(Reverse Address Resolution Rotocol) 逆地址解析协议
把 数据链路层 48位的MAC地址 转换成 网络层 32位的IP地址 .
总结
- (R)ARP 协议是 TCP/IP协议 里面基础的协议
- ARP和RARP协议的操作对程序员是透明的
- 理解(R)ARP协议有助于理解网络分层的细节
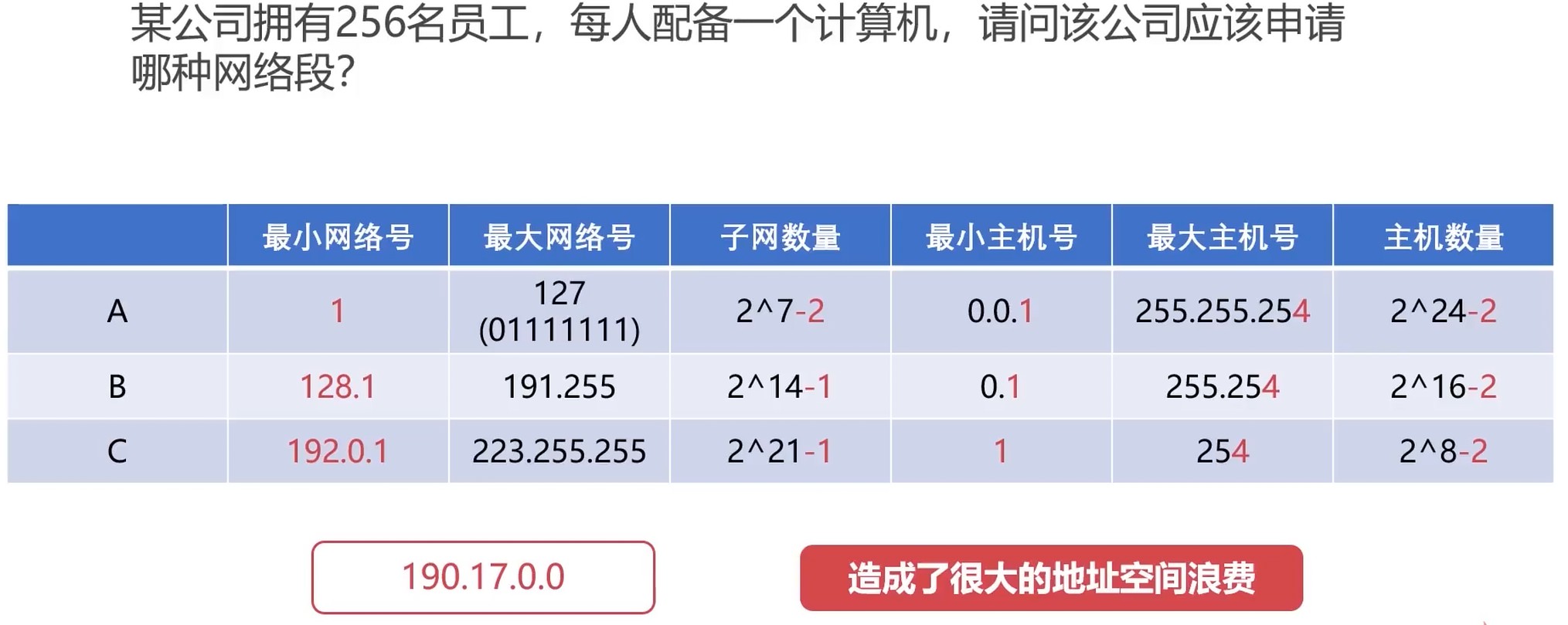
IP地址的子网划分
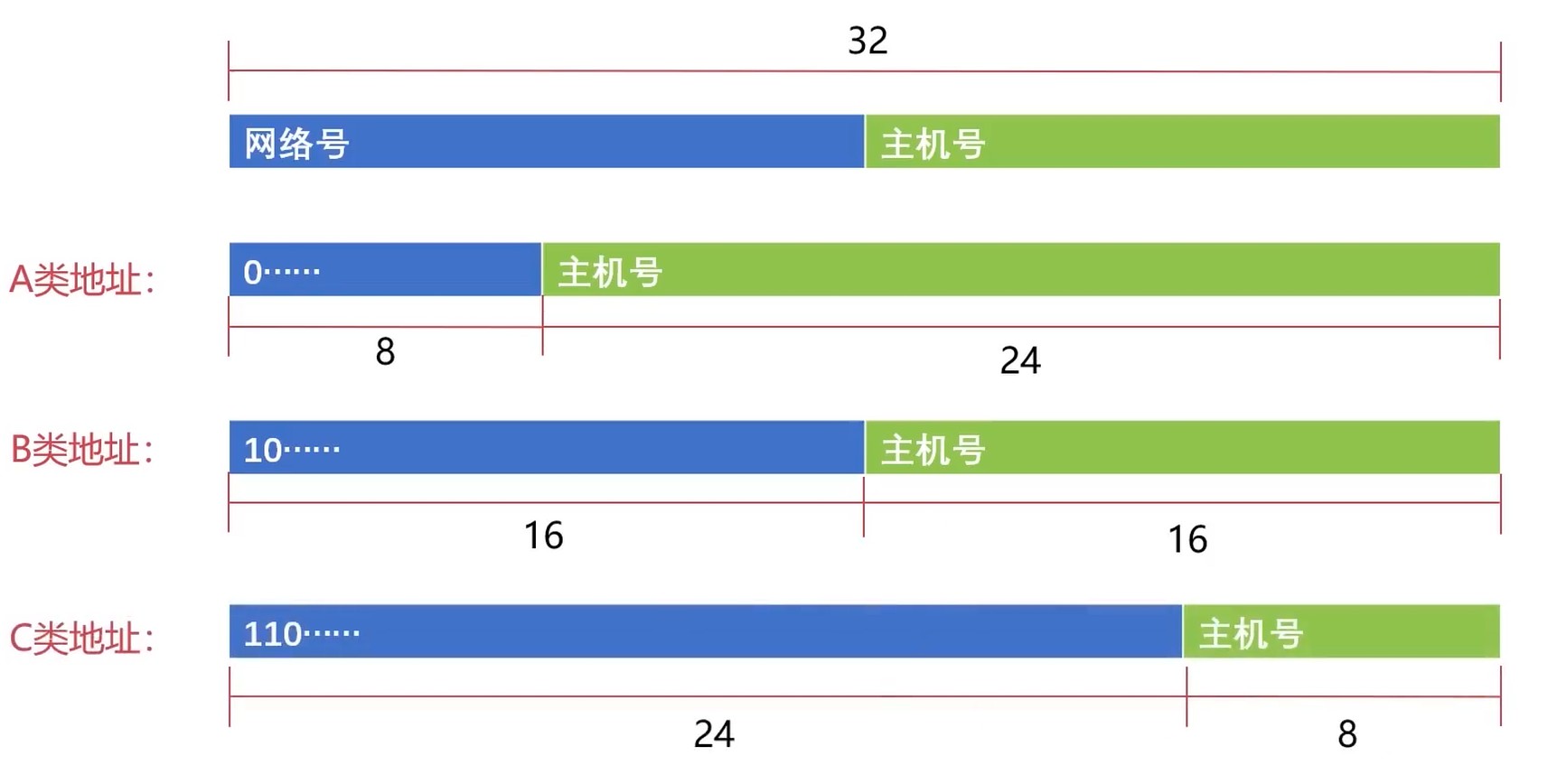
IP地址类别和组成

特殊主机号
- 主机号全0表示当前的网络段, 不可分配为特定主机
- 主机号全为1表示广播地址, 向当前网络段所有主机发消息
特殊网络号
- A类地址网络段全0(00000000)表示特殊网络
- A类地址网络段后7位全是1(01111111:127)表示回环地址
- B类地址网络段(128.0)是不可使用的
- C类地址网络段(192.0.0)是不可使用的
通过提取前8位判断是哪类地址.
回环地址: Loopback Address. 代表设备的本地虚拟接口, 默认看作是永远不会宕掉的接口. 一般用来检查本地网络协议, 基本数据接口等是否正常的.

子网划分
对最后8位判断进行划分.
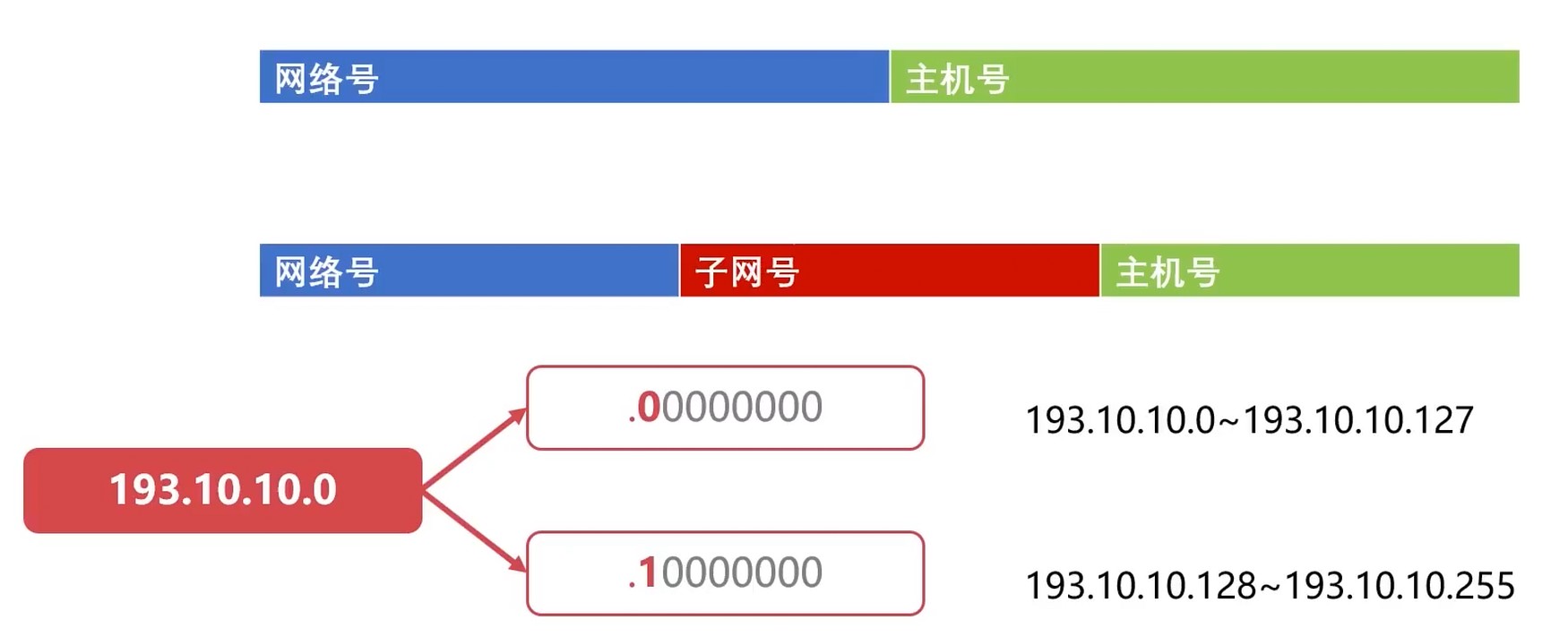
子网掩码: 判断某个ip的网络号
- 和IP地址一样, 都是32位的
- 子网掩码由连续的1和连续的0组成
- 某个子网的子网掩码具备网络号位个连续的1

子网掩码计算

无分类编址CIDR
- CIDR 中没有 A, B, C 类网络号和子网的划分概念
- CIDR 将 网络前缀 相同的IP地址称为一个 “CIDR地址块”
网络前缀 是任意位数的
斜线计法
- 193.10.10.129/25 表示网络前缀有25位
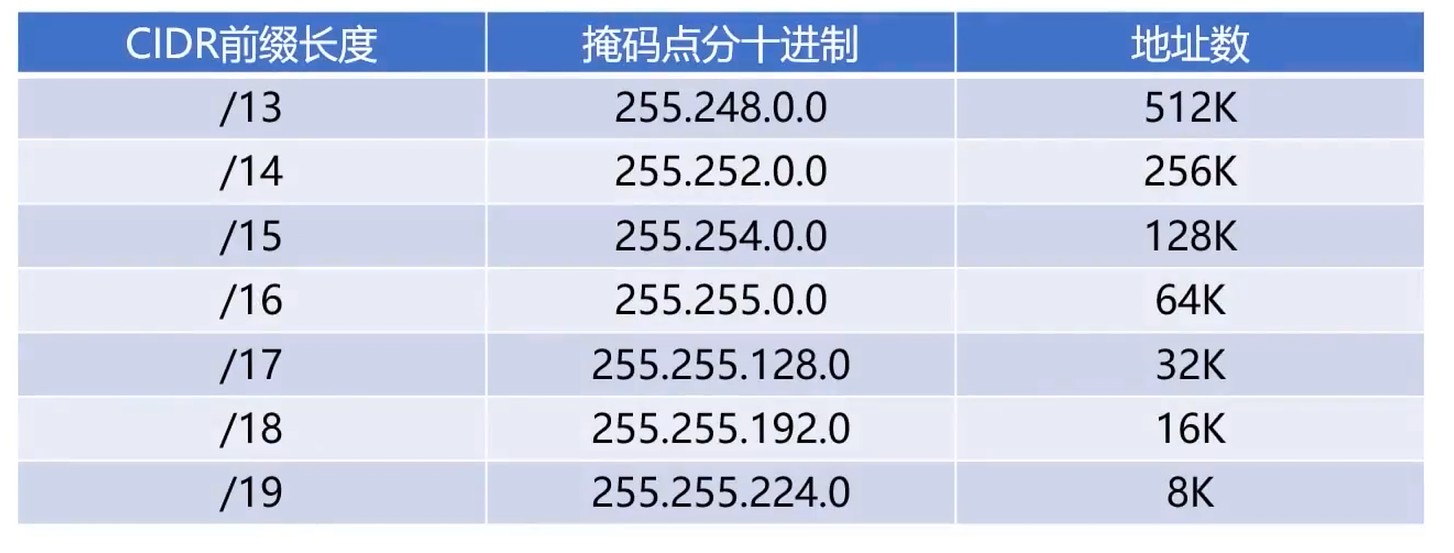
相比原来的子网划分更加灵活.
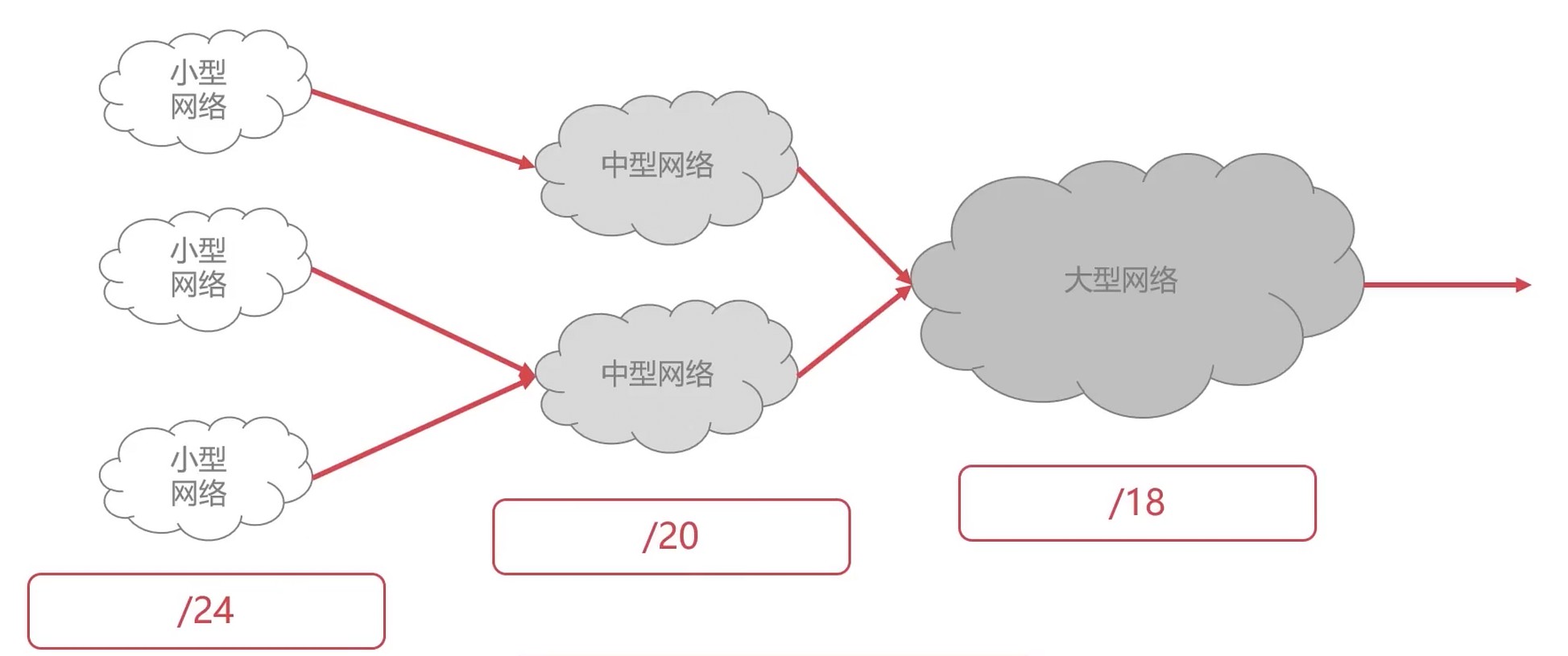
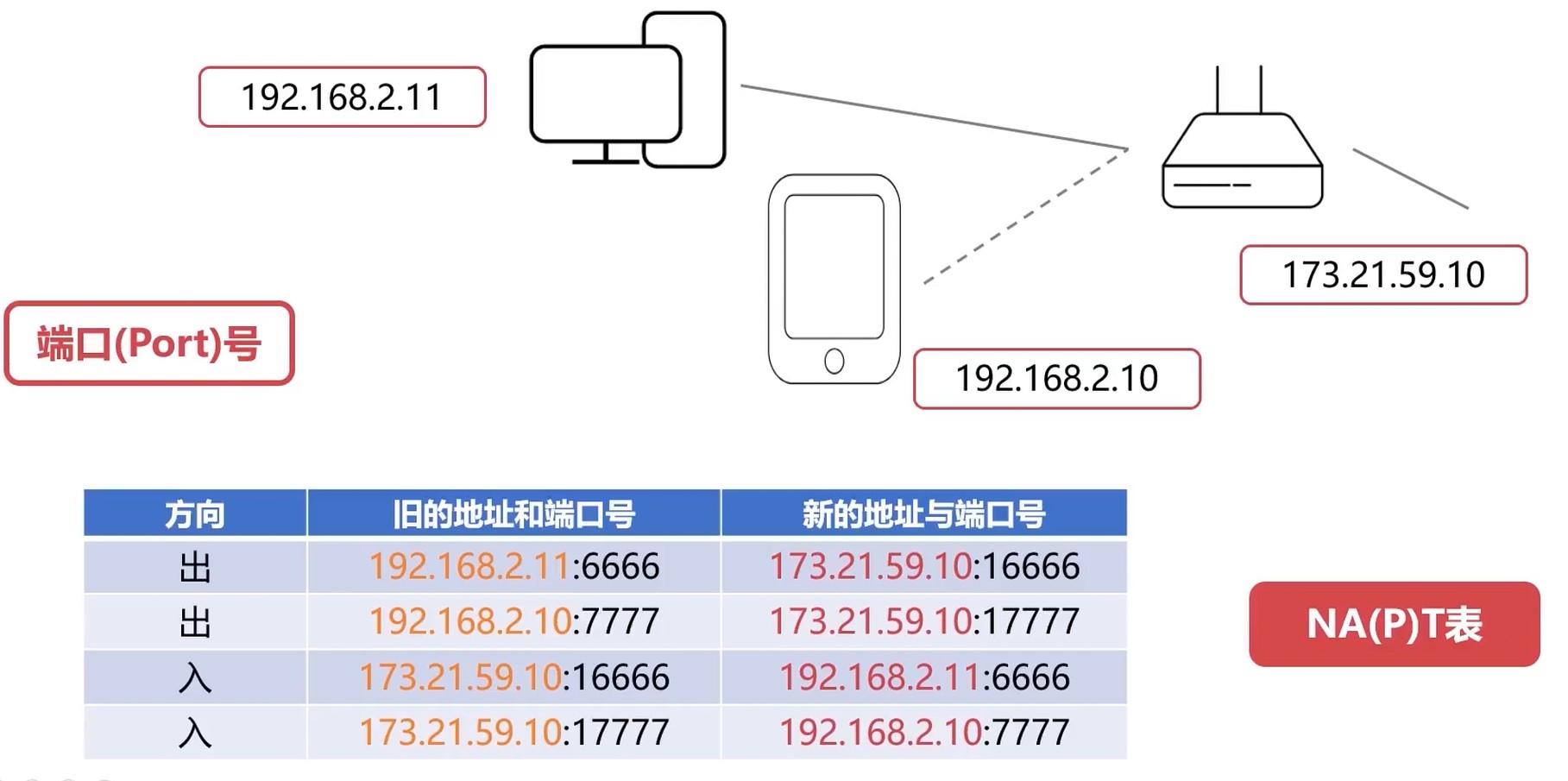
网络地址转换NAT技术
- 内网地址
- 内部机构使用
- 避免与外网地址重复
- 外网地址
- 全球范围使用
- 全球公网唯一

内网这么多设备, 用同一个ip访问, 那么怎么知道是哪个设备访问的? NAT技术
- 网络地址转换NAT – Network Address Translation
- NAT技术用于多个主机通过一个公有ip访问互联网的私有网络中
- NAT减缓了IP地址的消耗, 但是增加了网络通信的复杂度
ICMP协议
- 网络控制报文协议: Internet Control Message Protocol
- ICMP 协议可以报告错误信息或者异常情况
- 辅助IP协议可以更好地传输数据
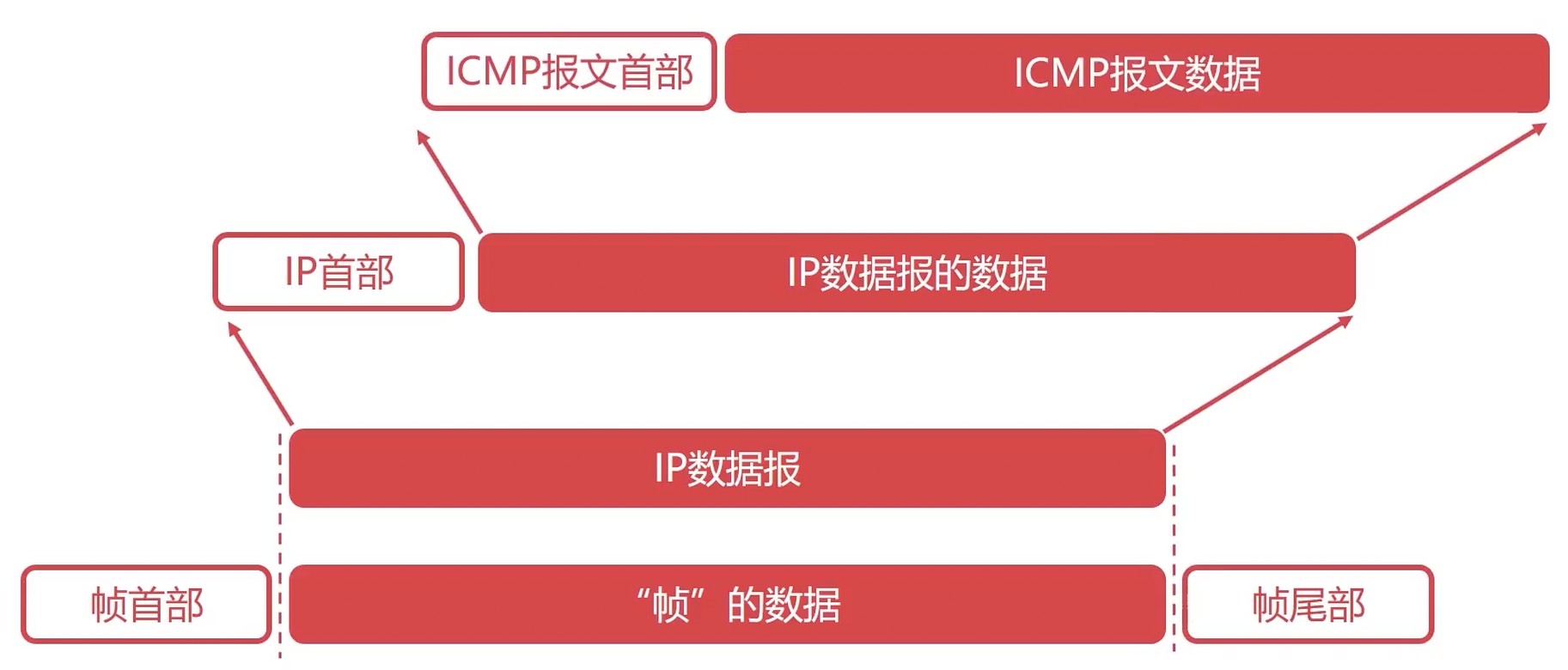
ICMP报文结构

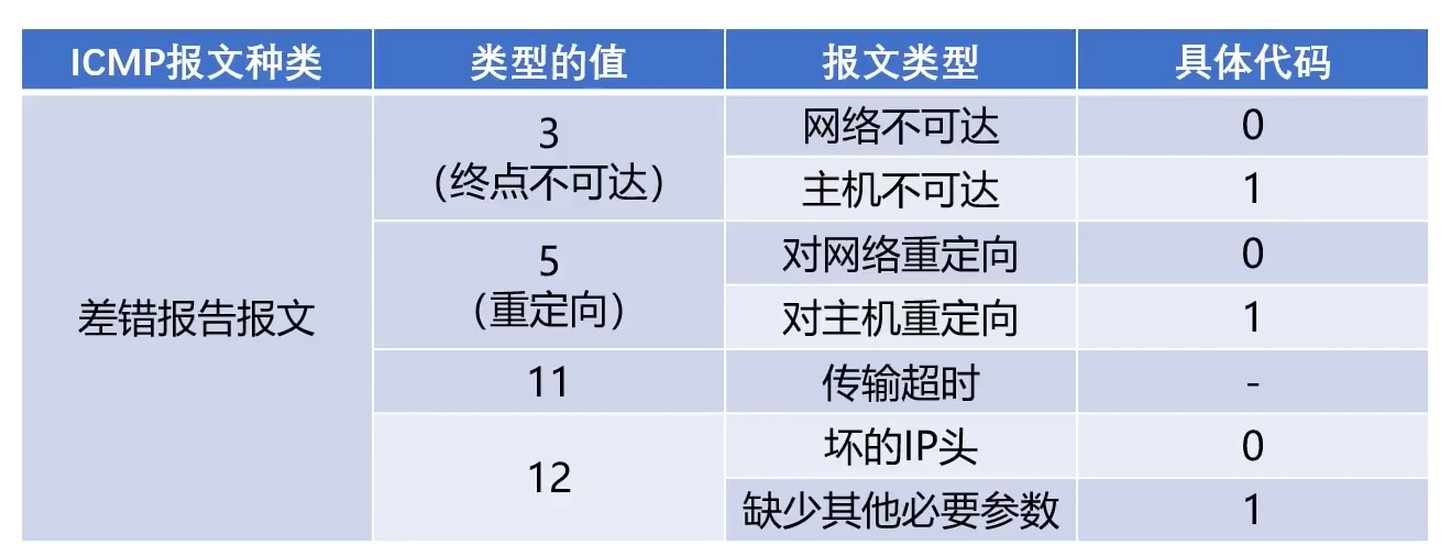
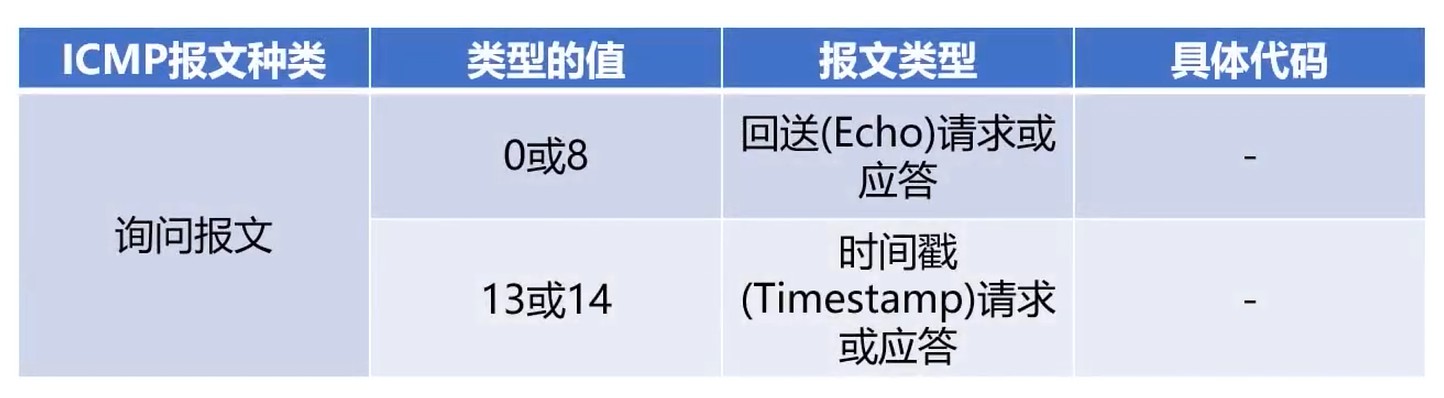
两种报文类型
- 差错报告报文
- 询问报文
ICMP应用
- ping应用
- Traceroute应用
ping应用
原理是利用询问报文.
# 正在 Ping www.a.shifen.com [14.215.177.38] 具有 32 字节的数据:
# 来自 14.215.177.38 的回复: 字节=32 时间=14ms TTL=53
# 来自 14.215.177.38 的回复: 字节=32 时间=7ms TTL=53
# 来自 14.215.177.38 的回复: 字节=32 时间=7ms TTL=53
# 来自 14.215.177.38 的回复: 字节=32 时间=8ms TTL=53
# TTL 如果为零就会被丢弃掉
- ping回环地址
- ping网关地址
- ping远程地址
Traceroute应用
探测IP数据报在网络中走过的路径, 利用差错报文.
TTL等于0, 会发出一个 ICMP终点不可达差错报文.
先封装一个TTL为1的报文发出去, 然后返回不可达差错报文, 然后再发出TTL为2的报文…以此类推.
tracert github.com
路由
路由的算法实际上就是图论的算法.
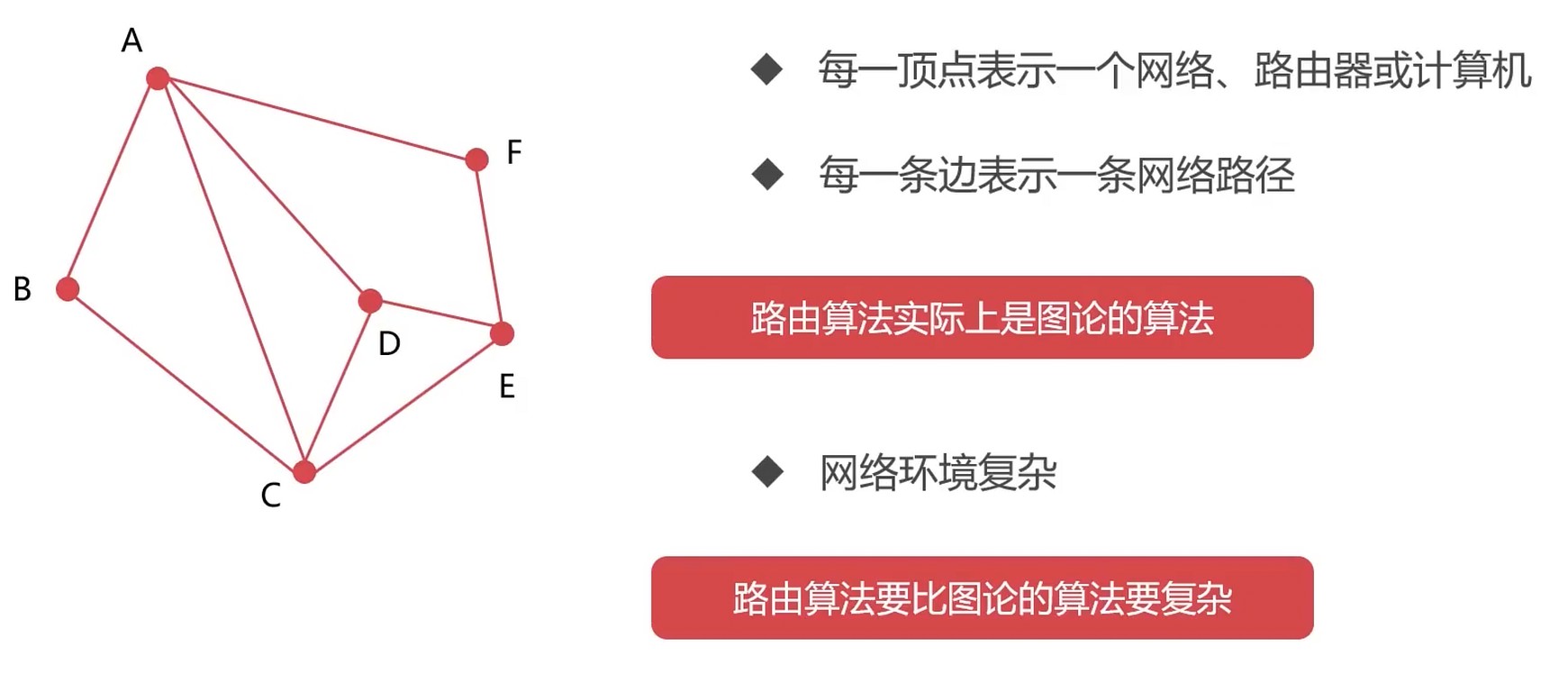
一个理想的路由算法
- 算法是完整的, 正确的
- 算法在计算上应该尽可能简单
- 算法可以适应网络中的变化
- 算法是稳定和公平的
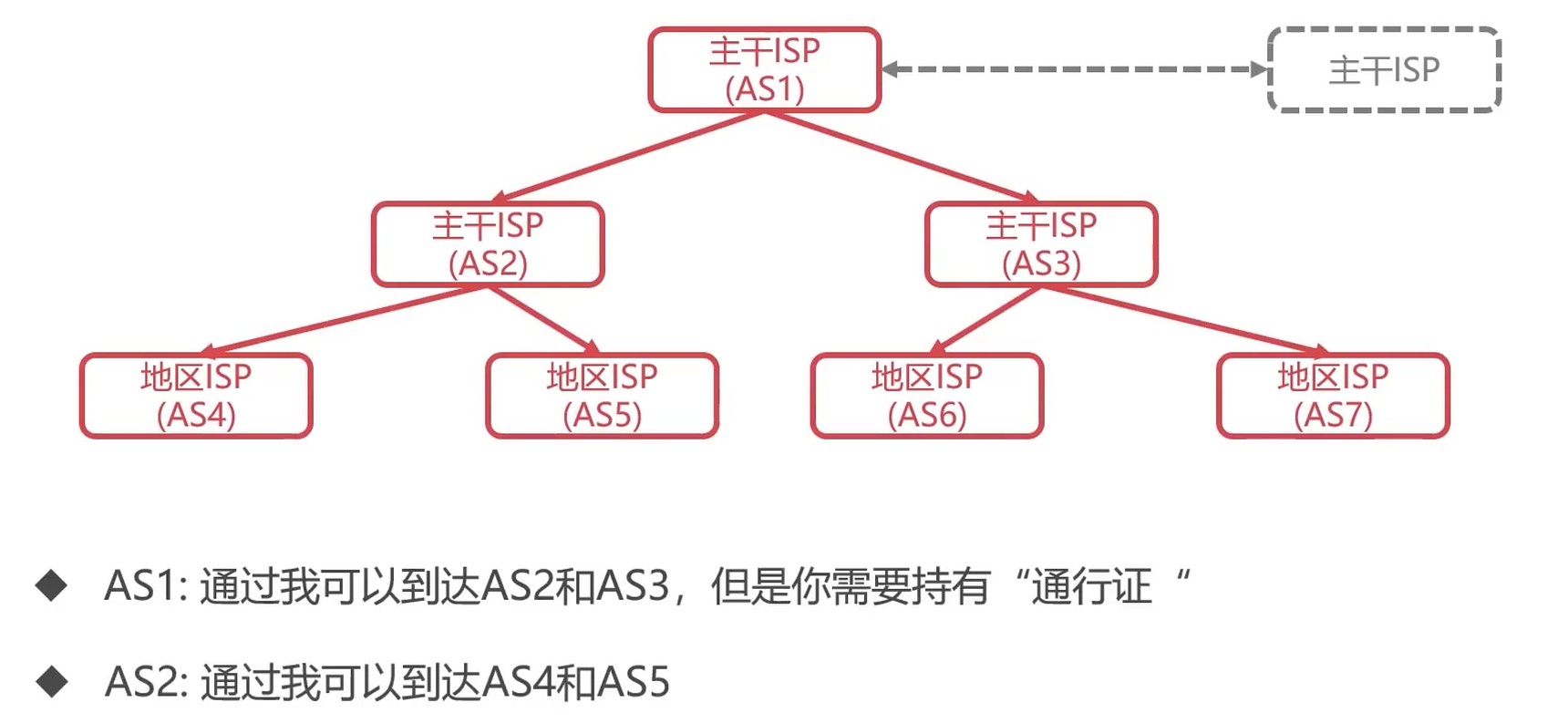
自治系统(Autonomous System)
- 一个自治系统(AS)是处于一个管理机构下的网络设备群
- AS内部网络自行管理, AS对外提供一个或者多个出(入)口
每个ISP都可以认为是一个AS
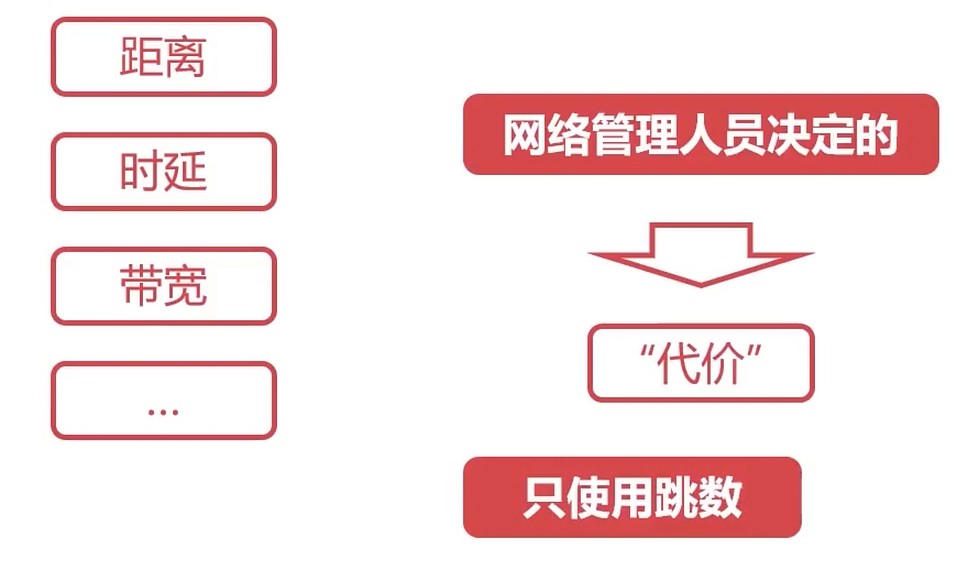
- 自治系统内部路由协议称为: 内部网关协议(RIP, OSPF)
- 自治系统外部路由的协议称为: 外部网关协议(BGP)

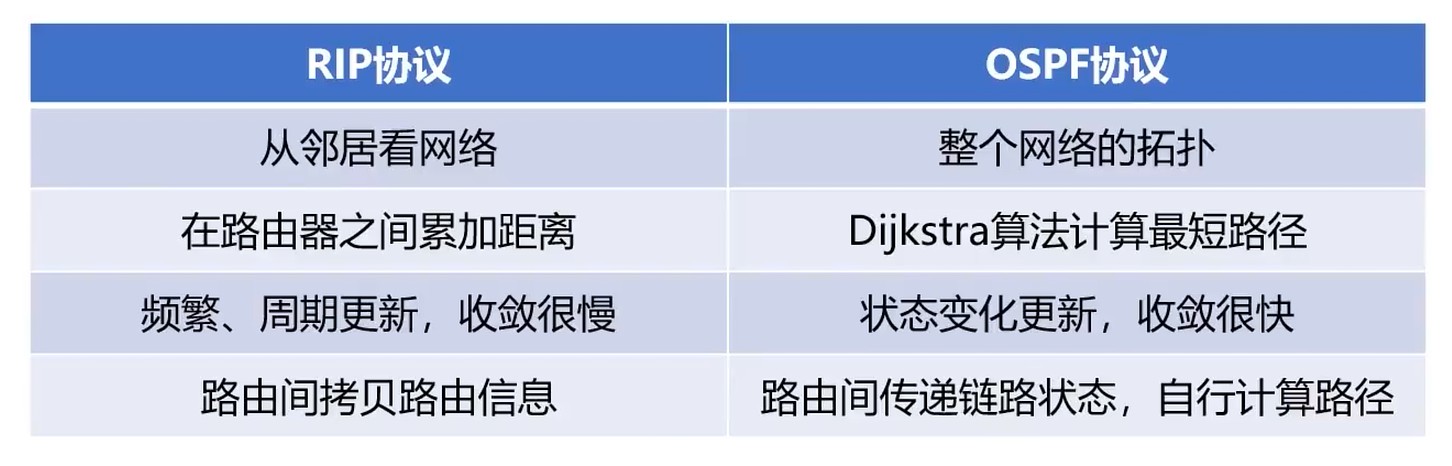
RIP协议
- 距离矢量(DV)算法
- RIP协议过程
距离矢量算法
每个节点使用两个向量Di和Si
Di描述的是当前节点到别的节点的距离
Si描述的是当前节点到别的节点的下一个节点
每一个节点都与相邻的节点交换向量Di和Si的信息
每一个节点根据交换的信息更新自己的节点信息

演示
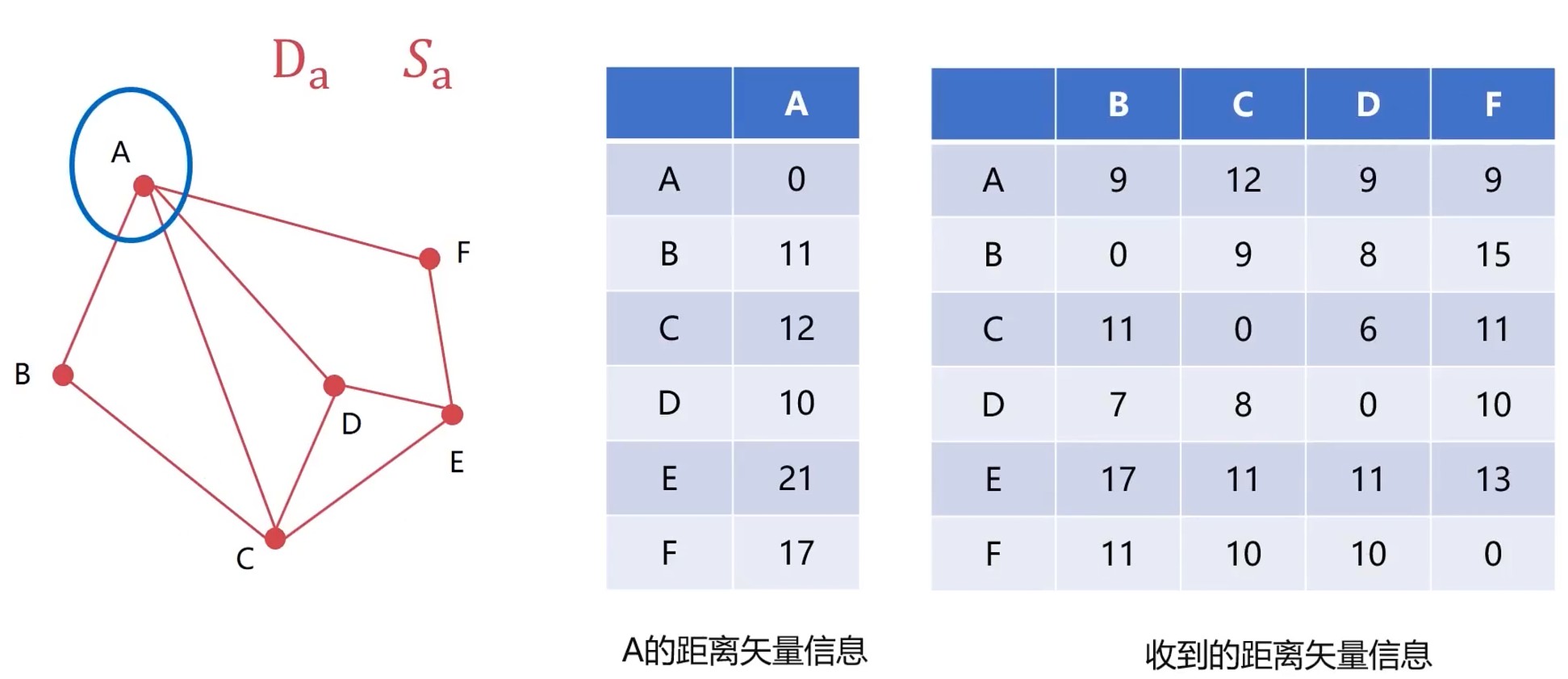
两点记录的记录可能不一样. 因为路线不一样.
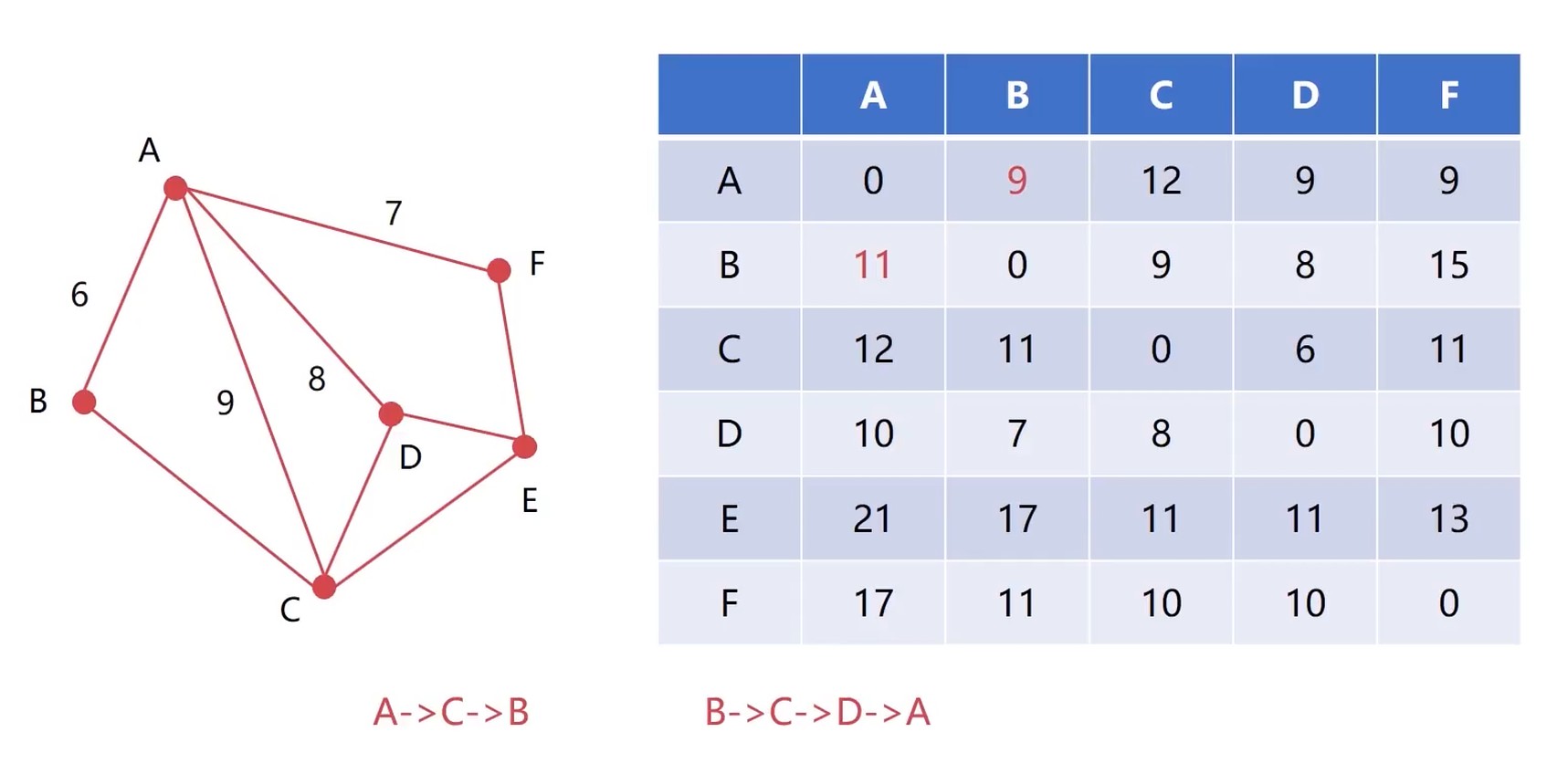
RIP协议过程
RIP – Routing Information Protocol 协议
是使用DV算法的一种路由协议
RIP协议把网络跳数(hop)作为DV算法的距离
RIP协议每隔30s交换一次路由信息
RIP协议认为跳数<15的路由则为不可达路由
- 路由器初始化路由信息(两个向量Di和Si)
- 对相邻路由X发来的信息进行修改(吓一跳地址X加1)
- 检索本地路由, 将信息中新的路由插入到路由表里面
- 检索本地路由, 对于下一跳为X的, 更新为修改后的信息(覆盖旧信息)
- 检索本地路由, 对比相同目的的距离, 如果新信息的距离更小, 则更新本地路由表, 不是则不更新
- 如果3分钟没有收到相邻的路由信息, 则把相邻路由设置为不可达(16跳)
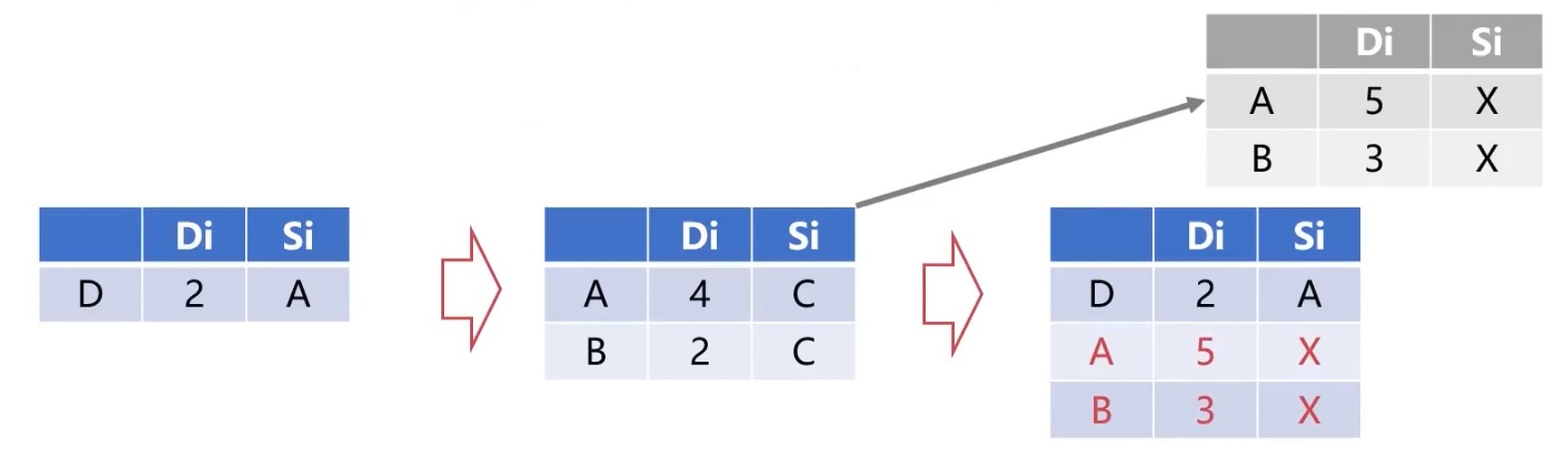
缺点: 故障信息传递慢, 更新收敛时间过长; 限制了网络的规模(跳数大于15都认为不可达)
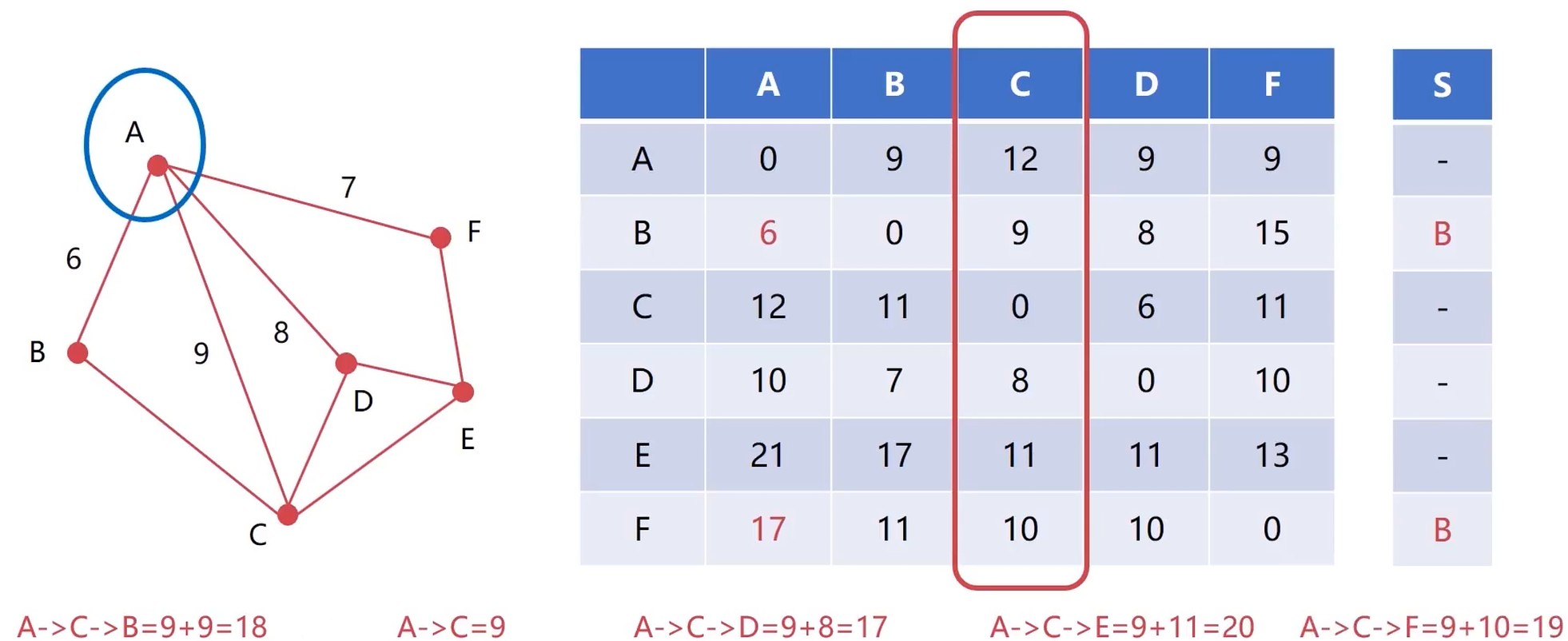
Dijkstra 算法
迪杰斯特拉 算法, 著名的图算法
- 解决有权图从一个节点到其他节点最短路径问题
- “以起始为中心, 向外层层扩展”
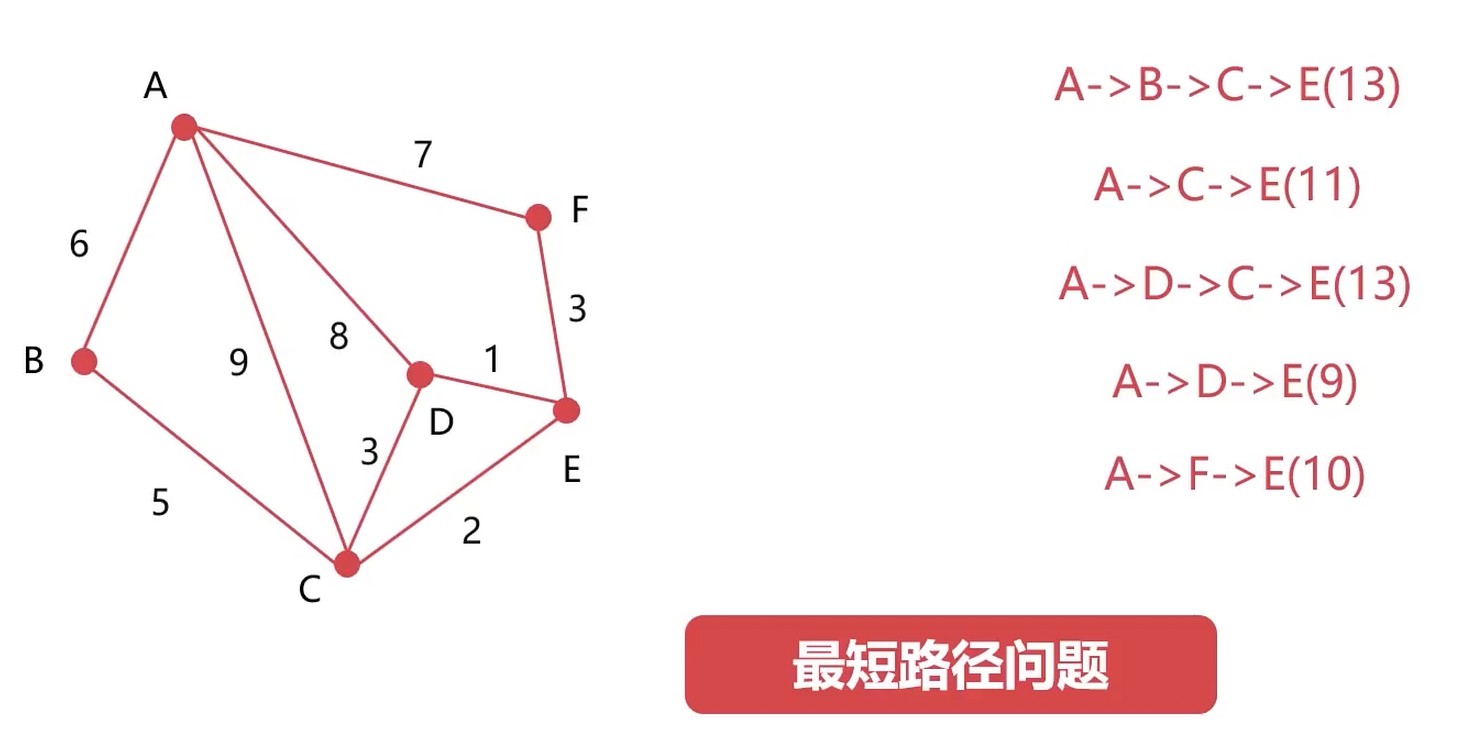
把这个问题转换成计算机语言可以描述的方法.

演示
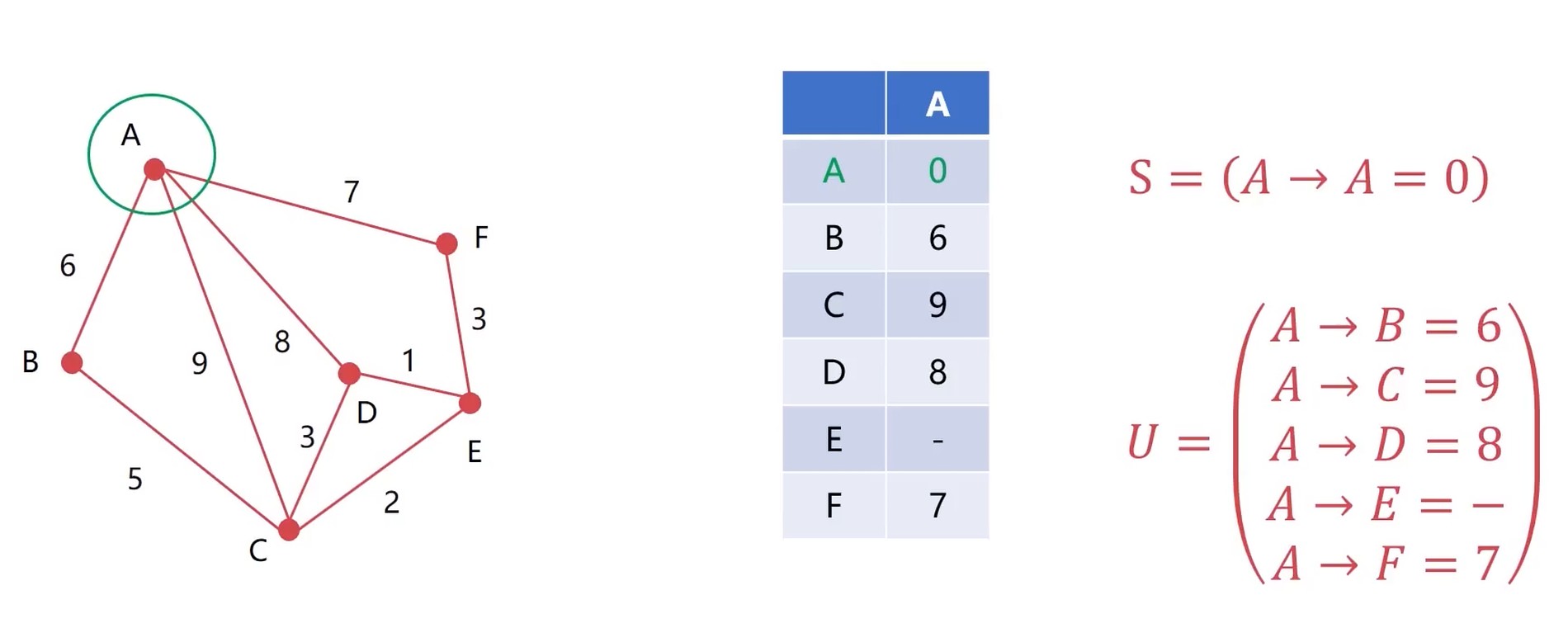
找出了离A最近的 A-B, 然后纳入S集合. 发现可以A-B-C, 然后更新 A-C 节点. 然后排序.
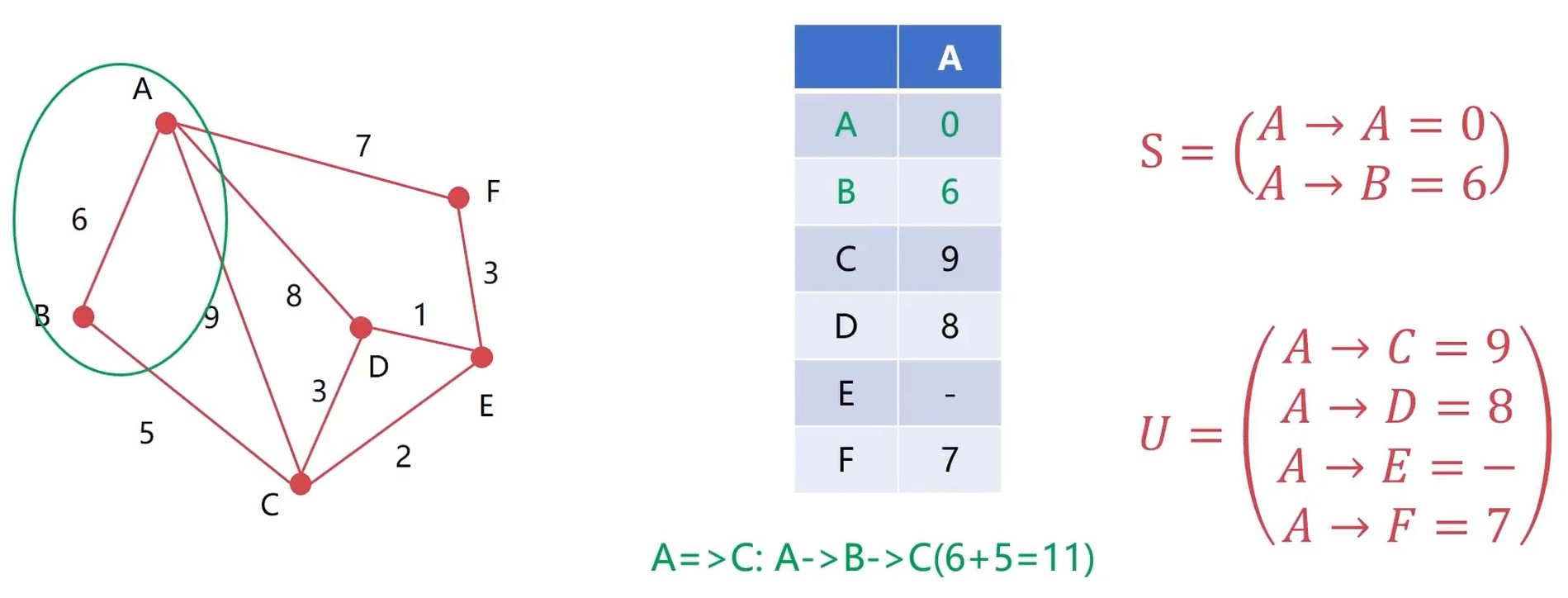
继续, 发现 A-> F 是最短的, 然后纳入 S 集合. 更新 A-E 节点. 然后排序.
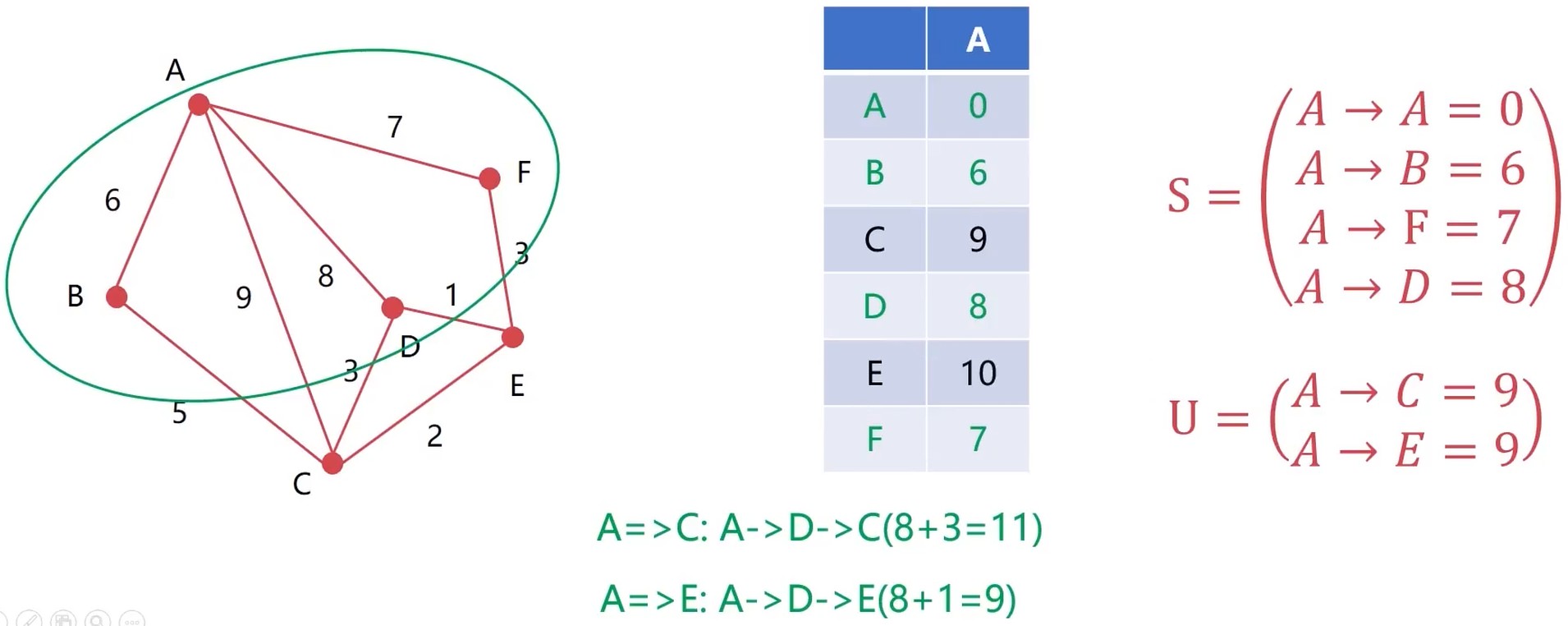
发现 剩下2个都是一样的, 随便挑选一个.
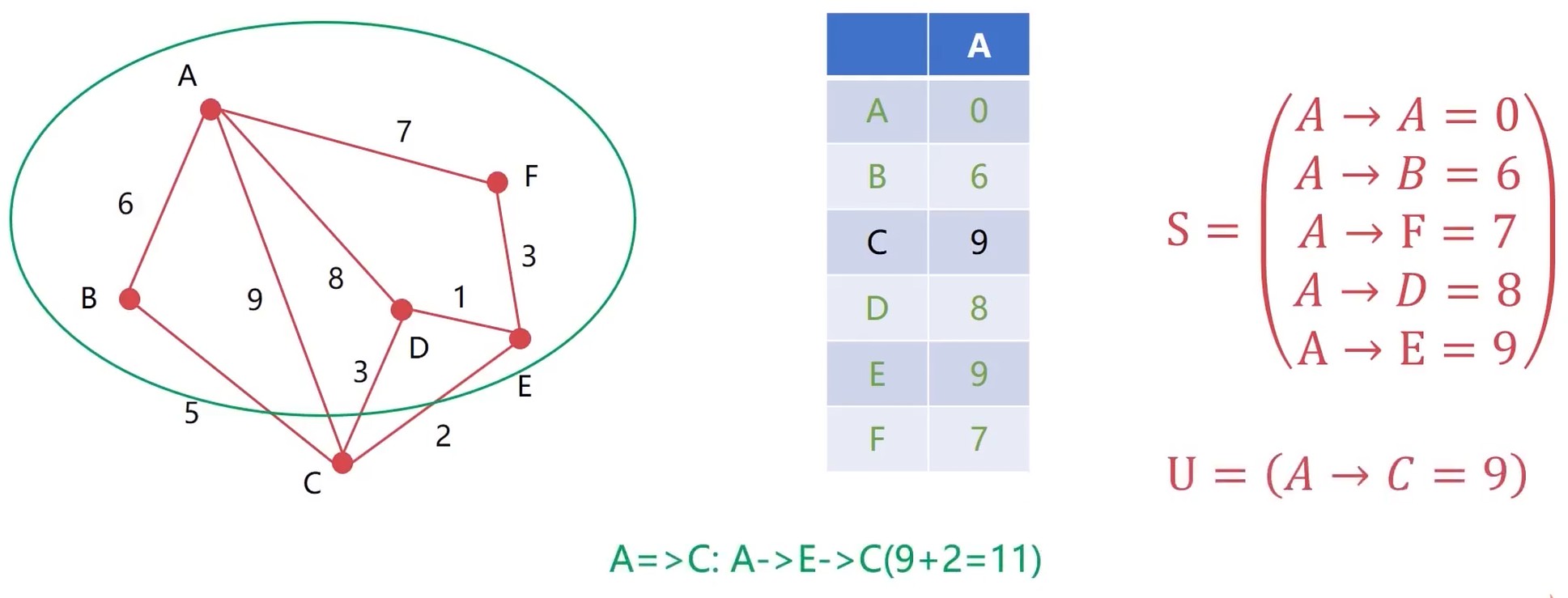
11大于9, 所以把U集合中的 A-C 放入 S 集合.
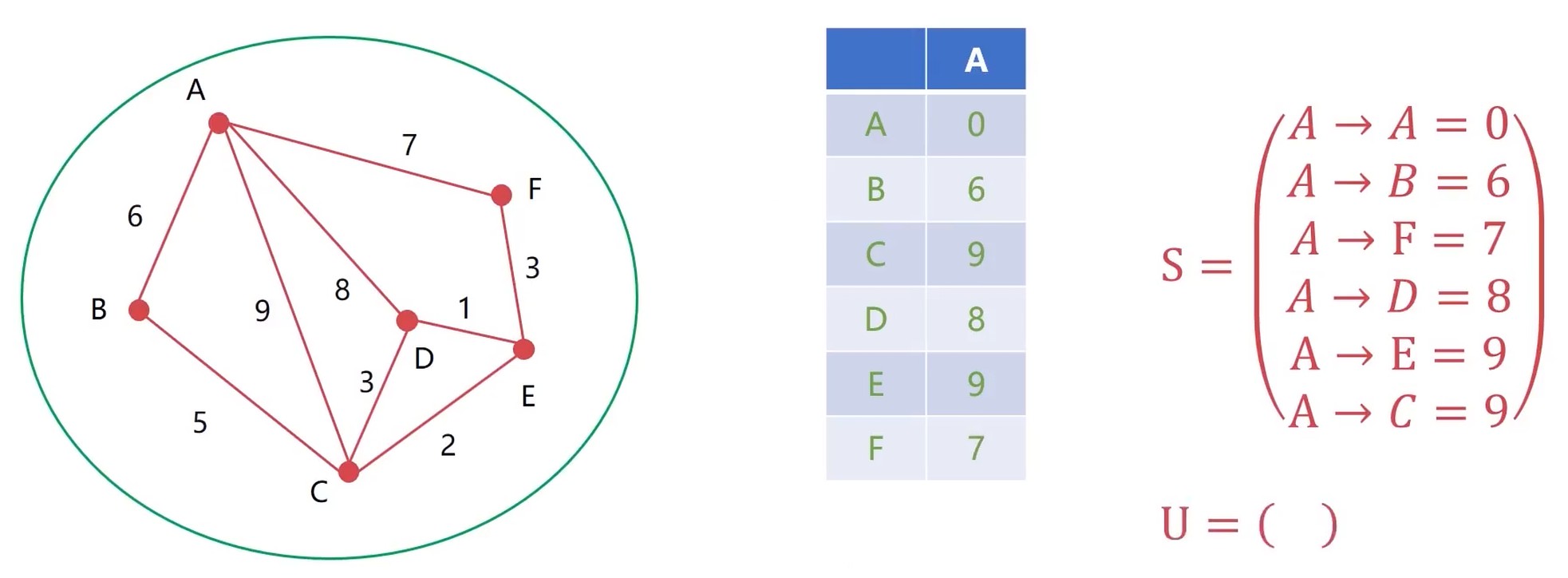
内部网关OSPF协议
OSPF(Open Shortest Path First): 开放最短路径优先
核心算法就是 Dijkstra(迪杰斯特拉) 算法.
链路状态(LS)协议.
- 向所有路由发送消息
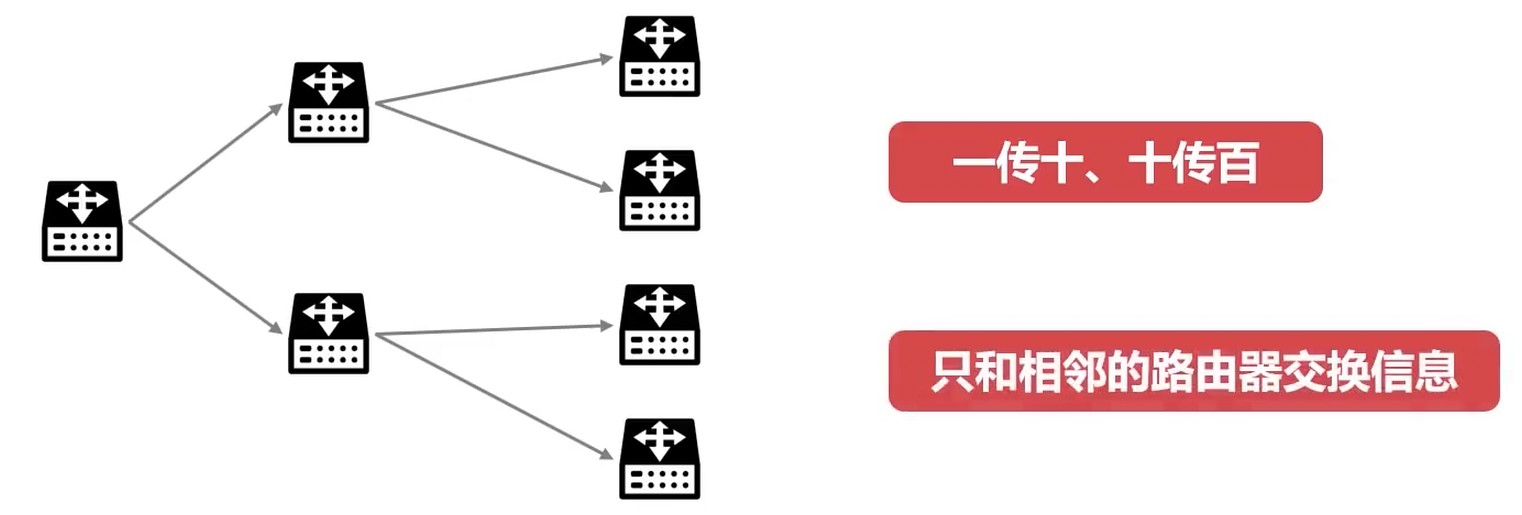
- 获得网络中的所有信息 -> 网络的完整拓扑
- 也称作”链路状态数据库“, 这个数据库是全网一致的
- 消息描述该路由与相邻路由器的链路状态
- 更加客观, 更加先进
- 只有链路状态发生改变时, 才发送更新消息
- 减少了数据的交换, 更快收敛
发送的消息类型
- 问候消息(Hello), 维护路由器之间的可达性
- 链路状态数据库描述信息
- 链路状态请求信息
- 链路状态更新信息(最频繁的消息)
- 链路状态确认信息

与 RIP 协议对比
外部网关BGP协议
BGP(Border Gateway Protocol): 边际网关协议
是运行在 AS 之间的一种协议
使用原因
- 互联网的规模很大
- AS内部使用不同的路由协议(OSPF, RIP)
- AS之间需要考虑除了网络特性以外的一些因素(政治, 安全…)
所以, BGP协议不能找到最好的路由, 但是能找到一条到达目的的比较好的路由
AS 之间通过 BGP 发言人来进行路由信息的交换
BGP发言人

传输层
UDP协议
- UDP(User Datagram Protocol), 用户数据报协议
- UDP协议是一个非常简单的协议
对数据报不会做处理(不合并, 不拆分)
长度由应用层数据决定.
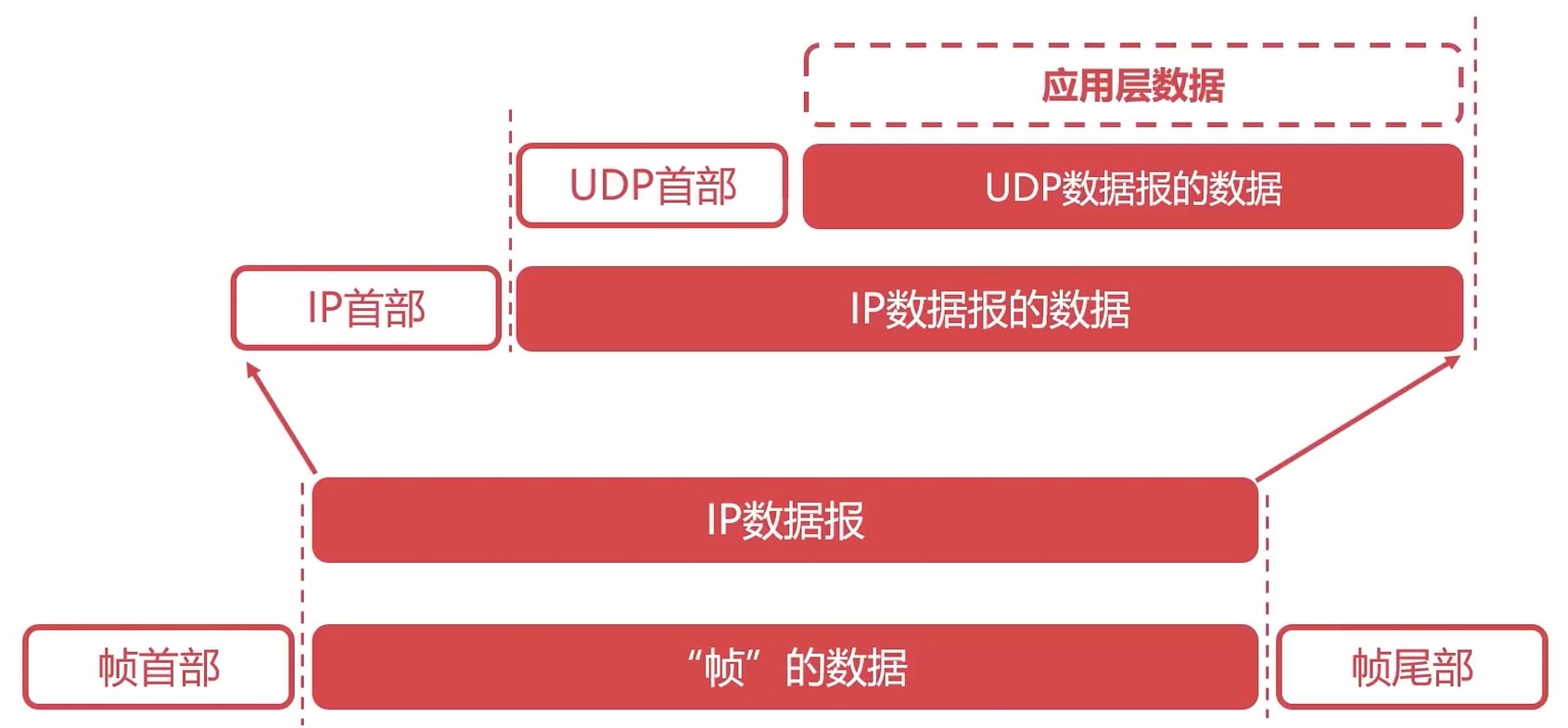
UDP首部
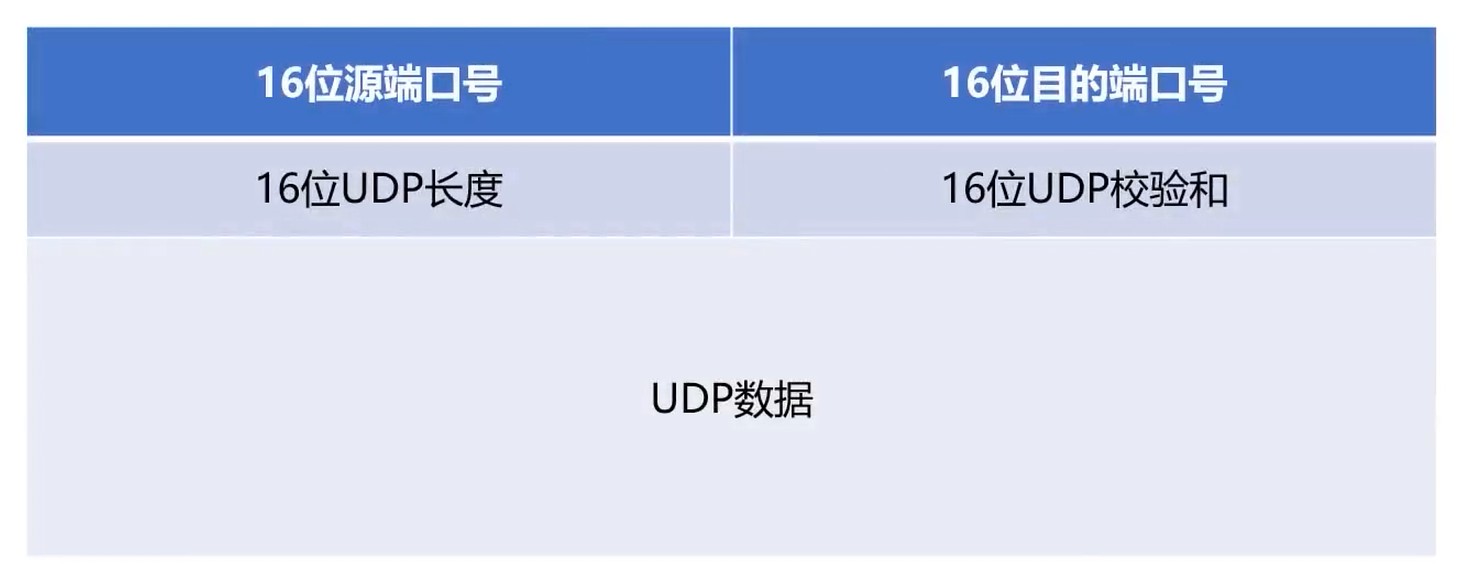
- UDP是无连接协议
- UDP不能保证可靠的交付数据
- UDP是面向报文传输的(应用层传过来的数据直接放进去不做处理)
- UDP没有拥塞控制
- UDP的首部开销很小(8个字节)
TCP协议
- TCP(Transmission Control Protocol): 传输控制协议
- TCP协议是计算机网络中非常复杂的一个协议
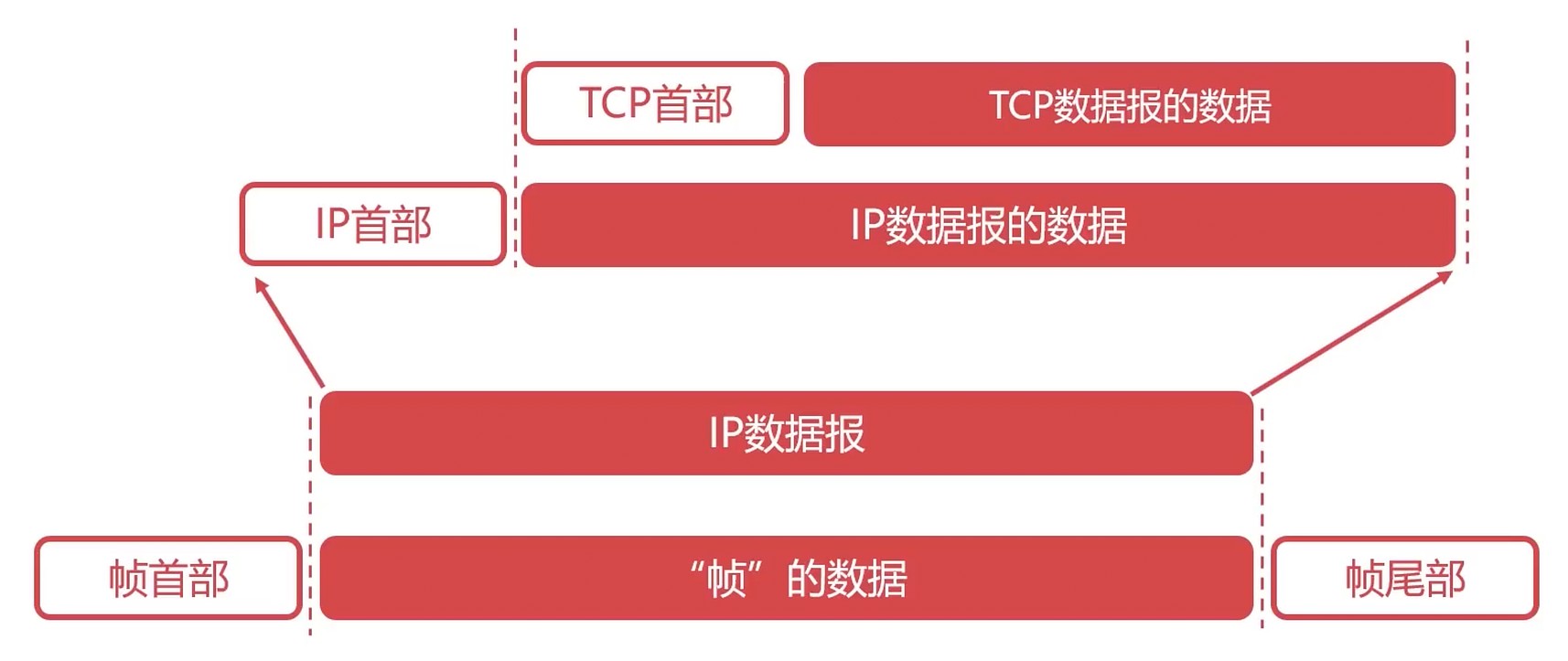
特点
- TCP是面向连接的协议
- TCP的一个连接有两端(点对点通信)
- TCP提供可靠的传输服务
- TCP协议提供全双工的通信
- TCP是面向字节流的协议(不是面向一整块数据进行处理的, 而是面向一个字节一个字节处理, 所以就可以取出一段来进行传输)
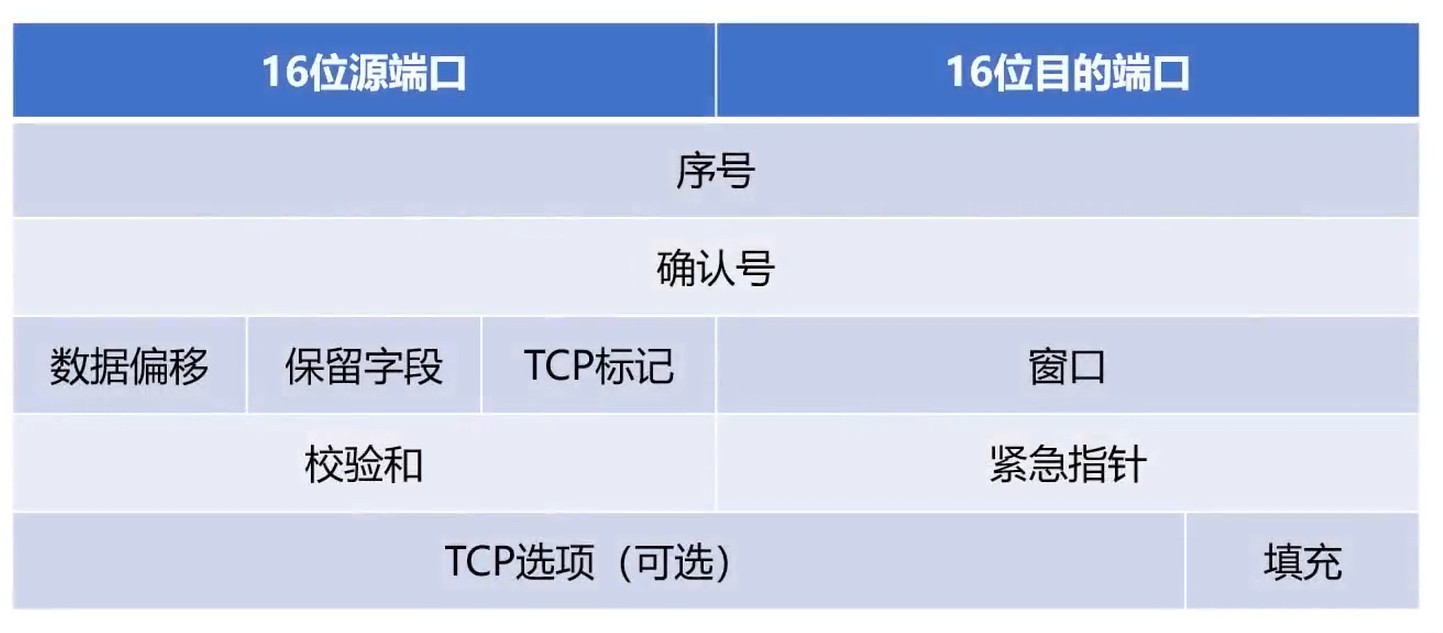
前面5行固定20字节.
序号
- 0~2^32^-1
- 一个字节一个序号
- 数据首个字节序号
确认号
- 0~2^32^-1
- 一个字节一个序号
- 期待收到数据的首字节序号
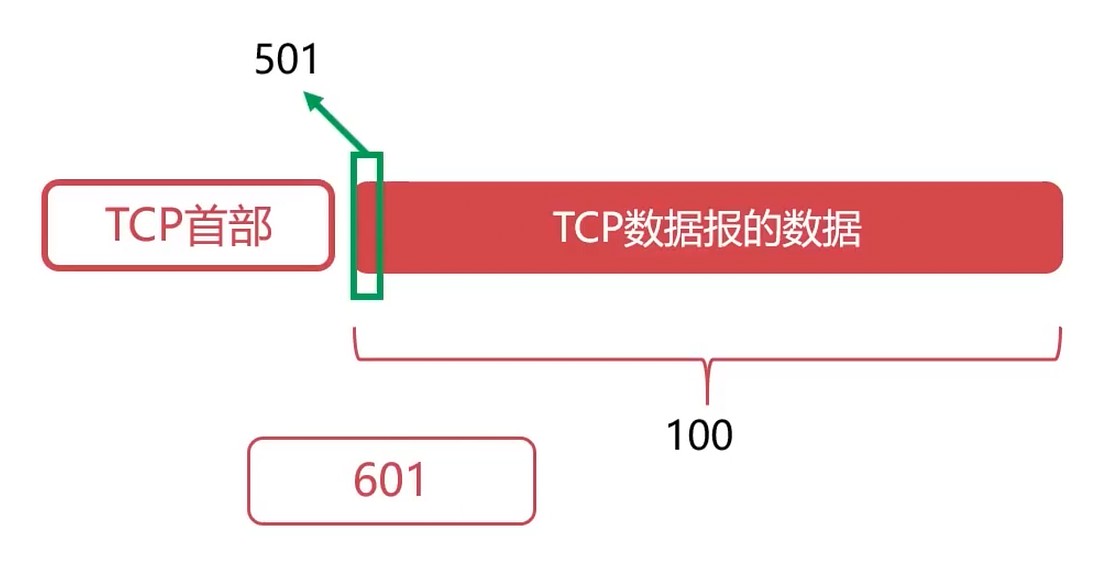
确认号为N: 则表示N-1序号的数据都已经收到了.
数据偏移
- 占4位: 0~15, 单位为: 32位. 每个偏移4个字节.
- 数据偏移首部的距离
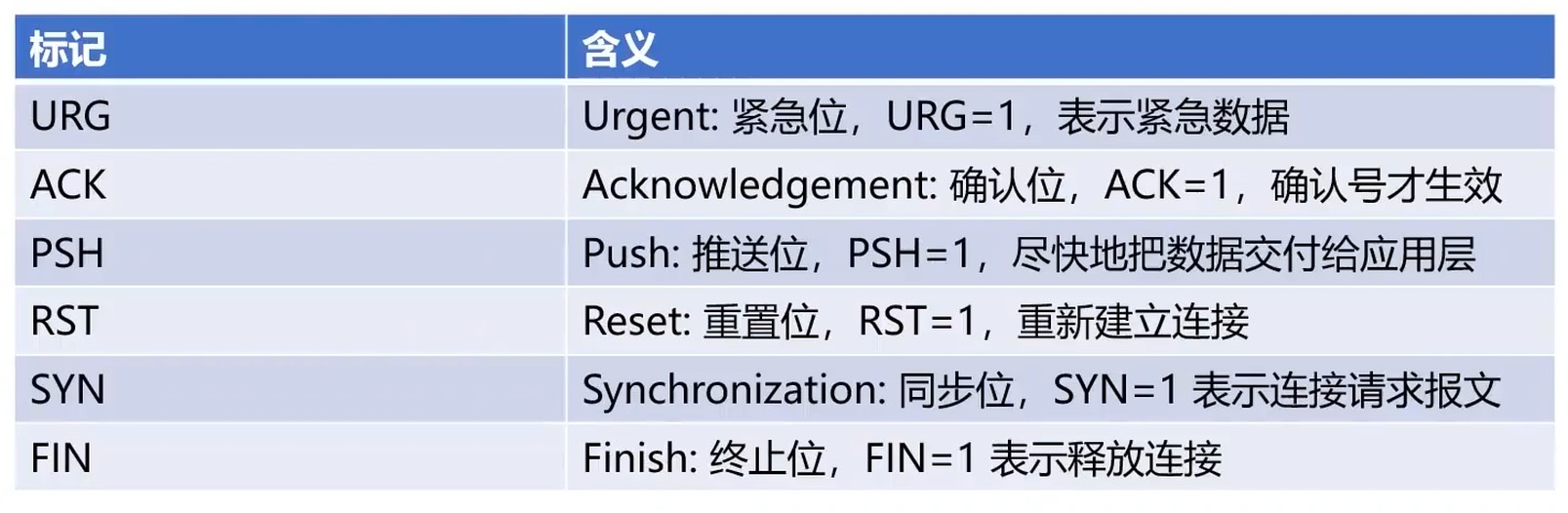
TCP标记位
- 占6位, 每位各有不同意义

窗口
- 占16位: 0~2^16^-1
- 窗口指明对方允许发送的数据量
紧急指针
- 紧急数据(URG=1)
- 指定紧急数据在报文的位置
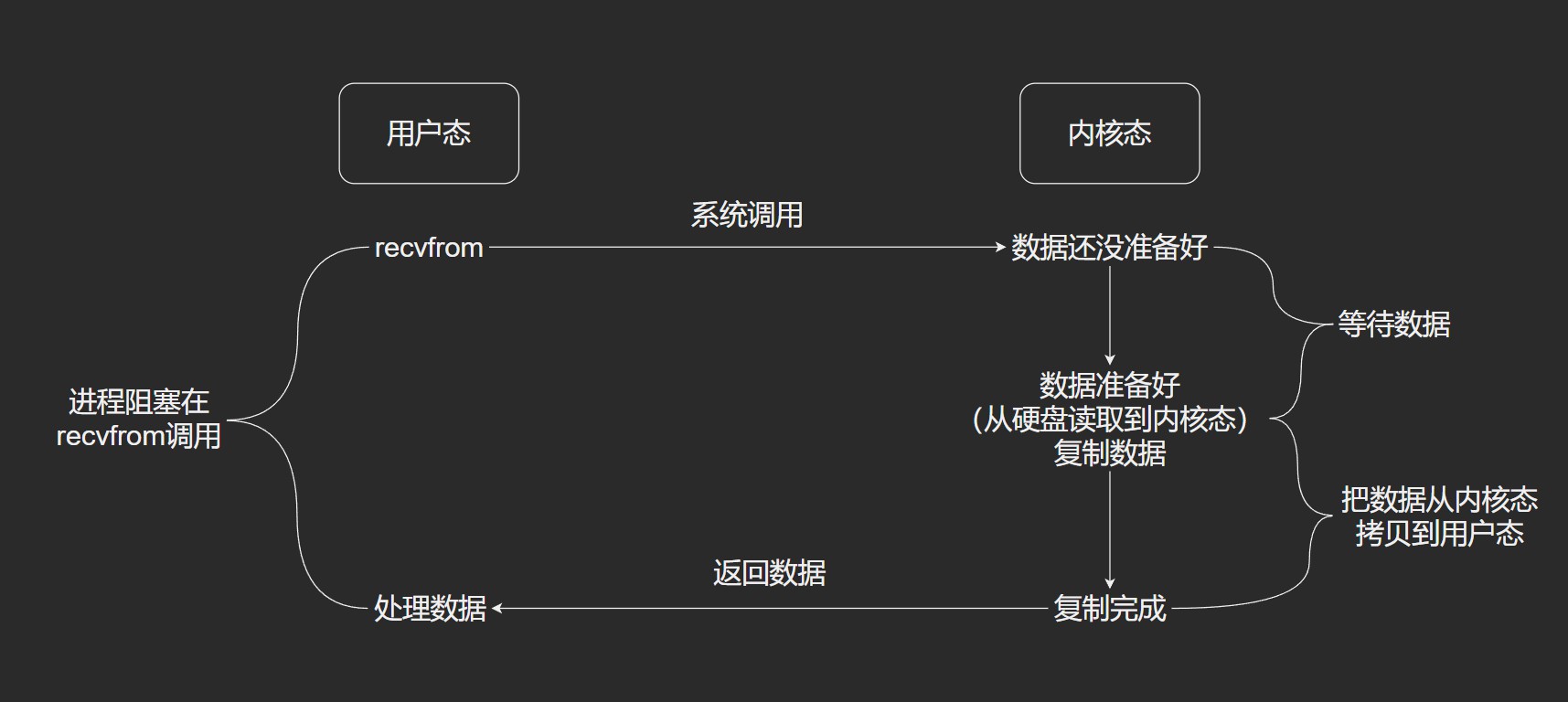
TCP可靠传输的原理
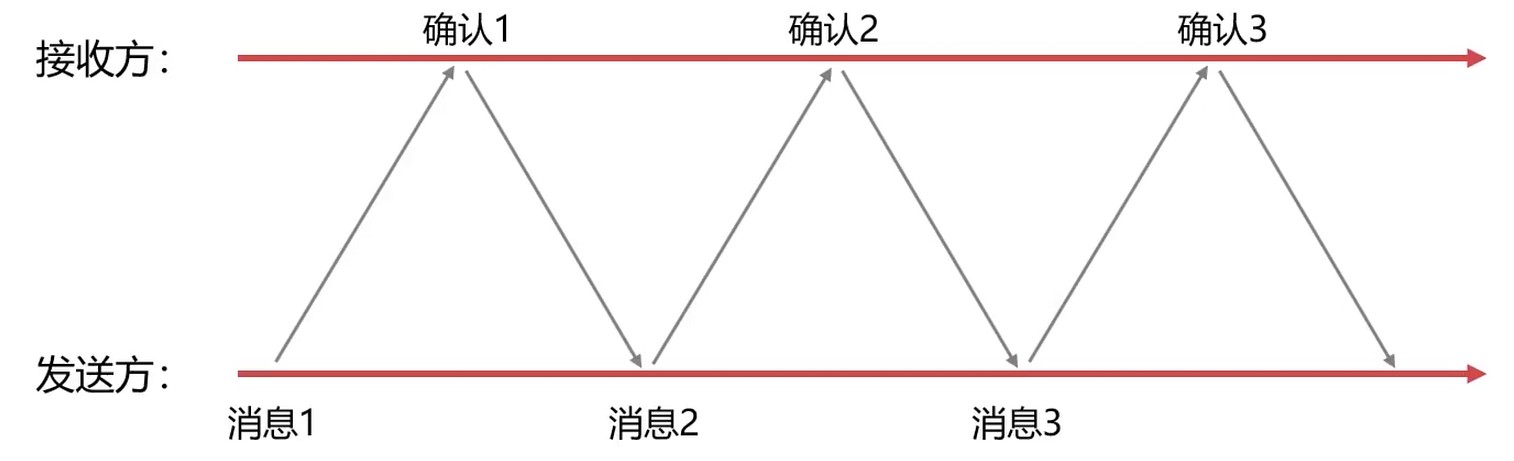
停止等待协议
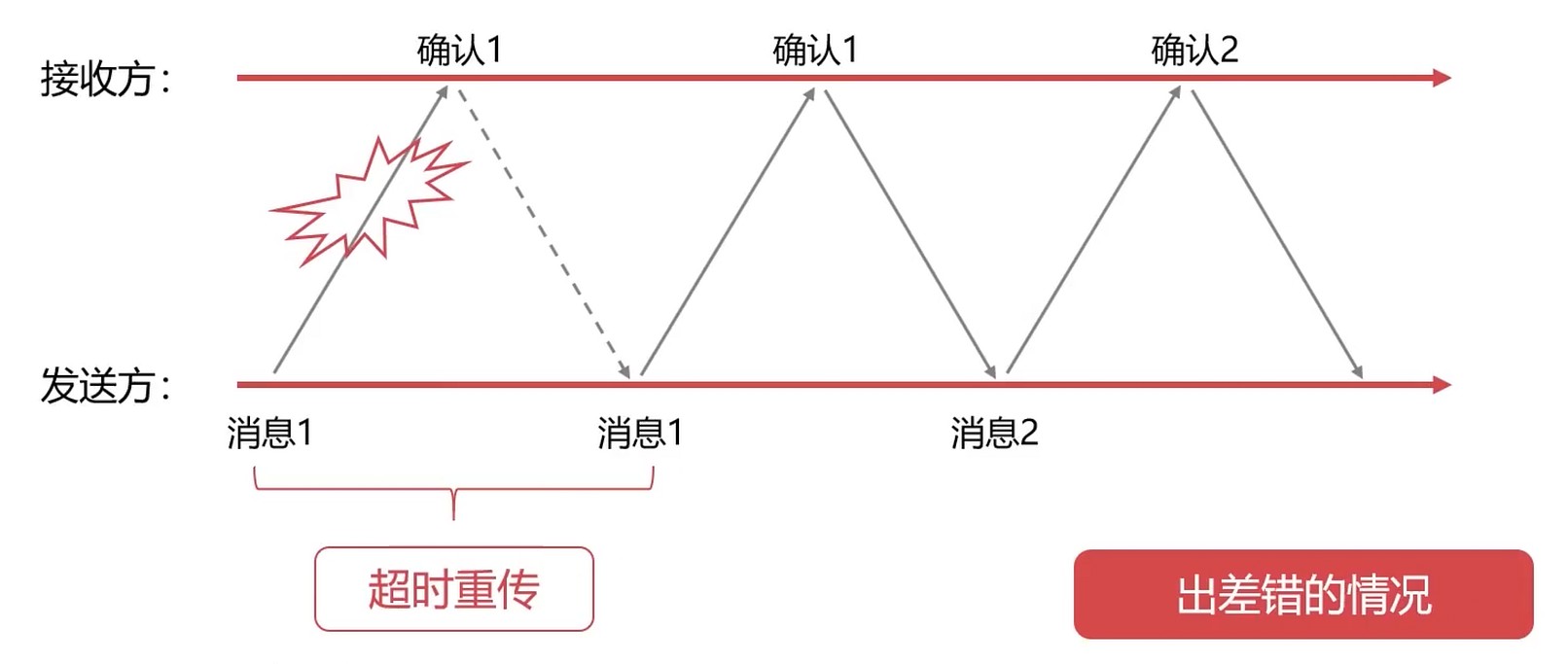
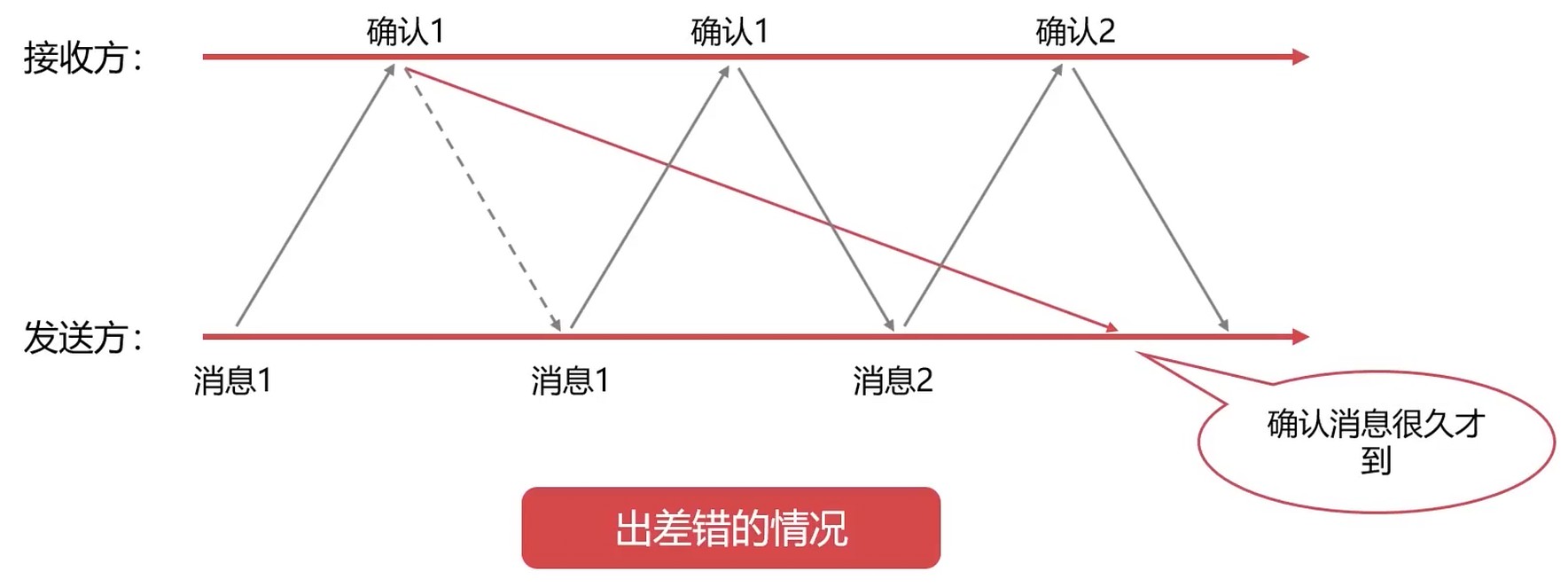
- 发送的消息在路上丢失了
- 确认的消息在路上丢失了
- 确认的消息很久才到
停止等待协议通过 超时重传 保证可靠传输.
每发送一个消息, 都需要设置一个定时器–超时定时器
停止等待协议是最简单的可靠传输协议
问题: 对信号的利用率不高
连续ARQ协议
ARQ: Automatic Repeat Request, 自动重传请求.
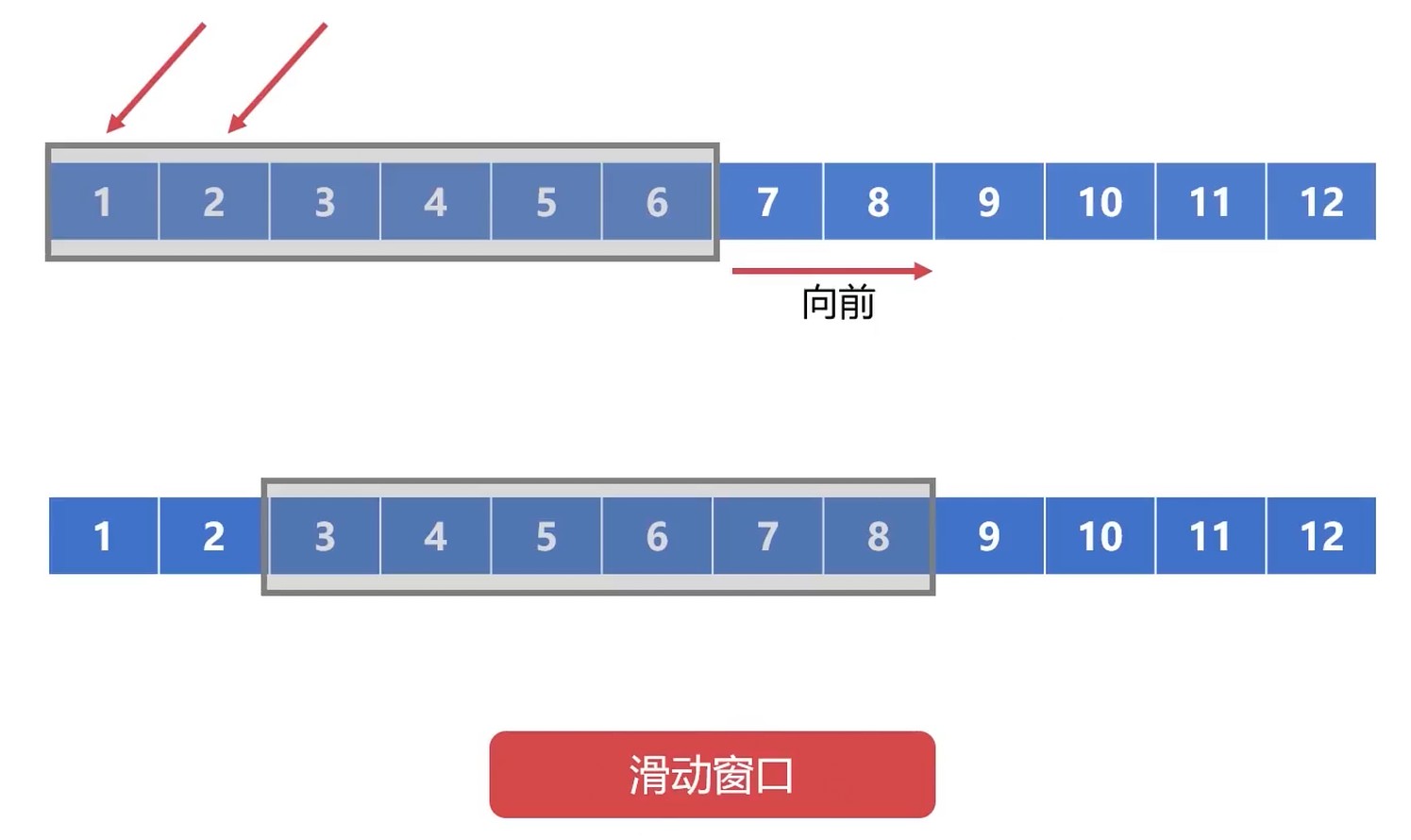
使用 累计确认 的方式确认消息的完整性. 比如说, 确认到 消息5 到达了, 那就说明之前的数据都到了, 就往前推动5格. 这样可以有效减少确认次数, 提高传输效率.
TCP协议的可靠传输
- TCP的可靠传输是基于连续ARQ协议
- TCP的滑动窗口是以字节为单位的
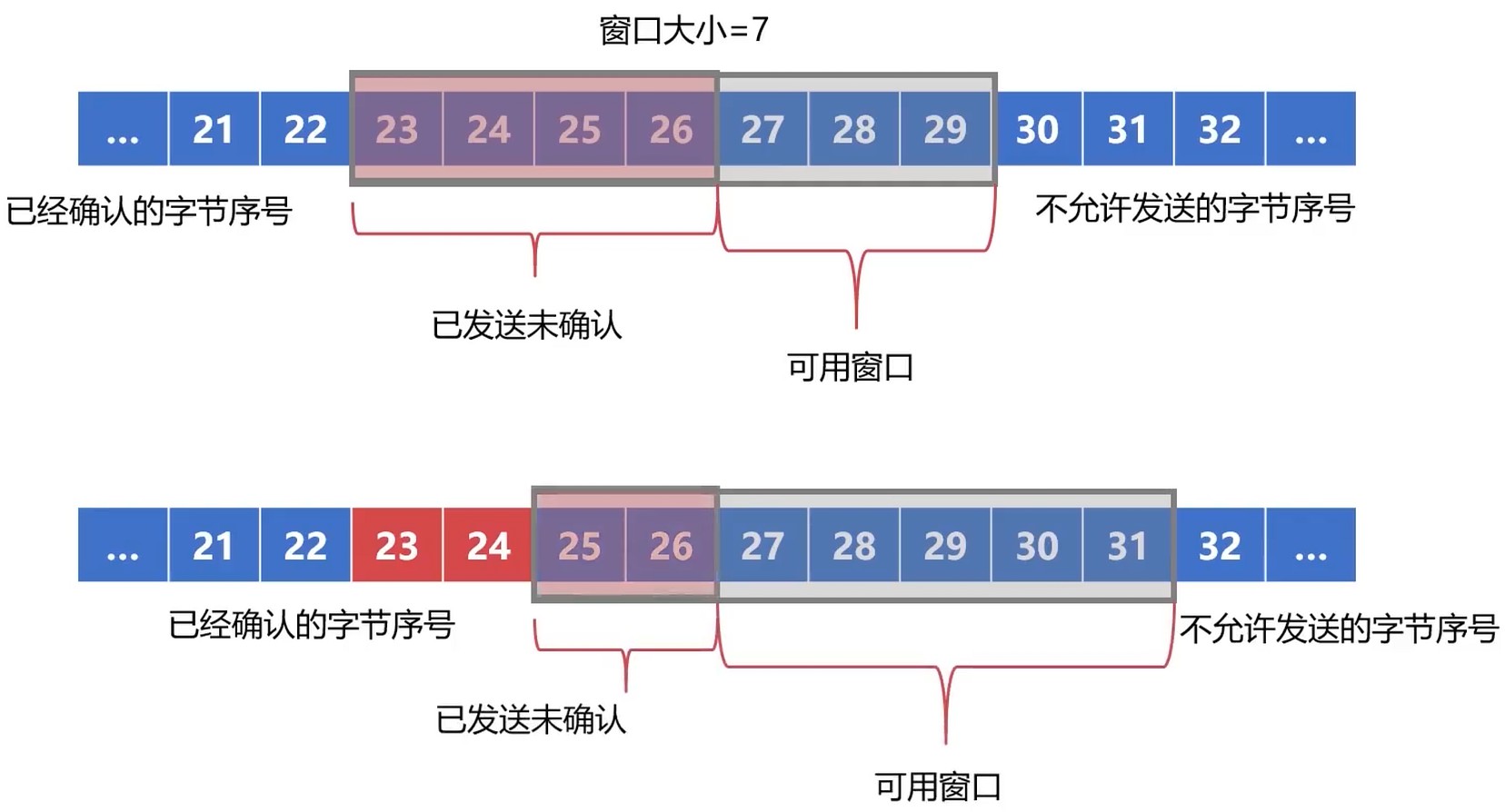
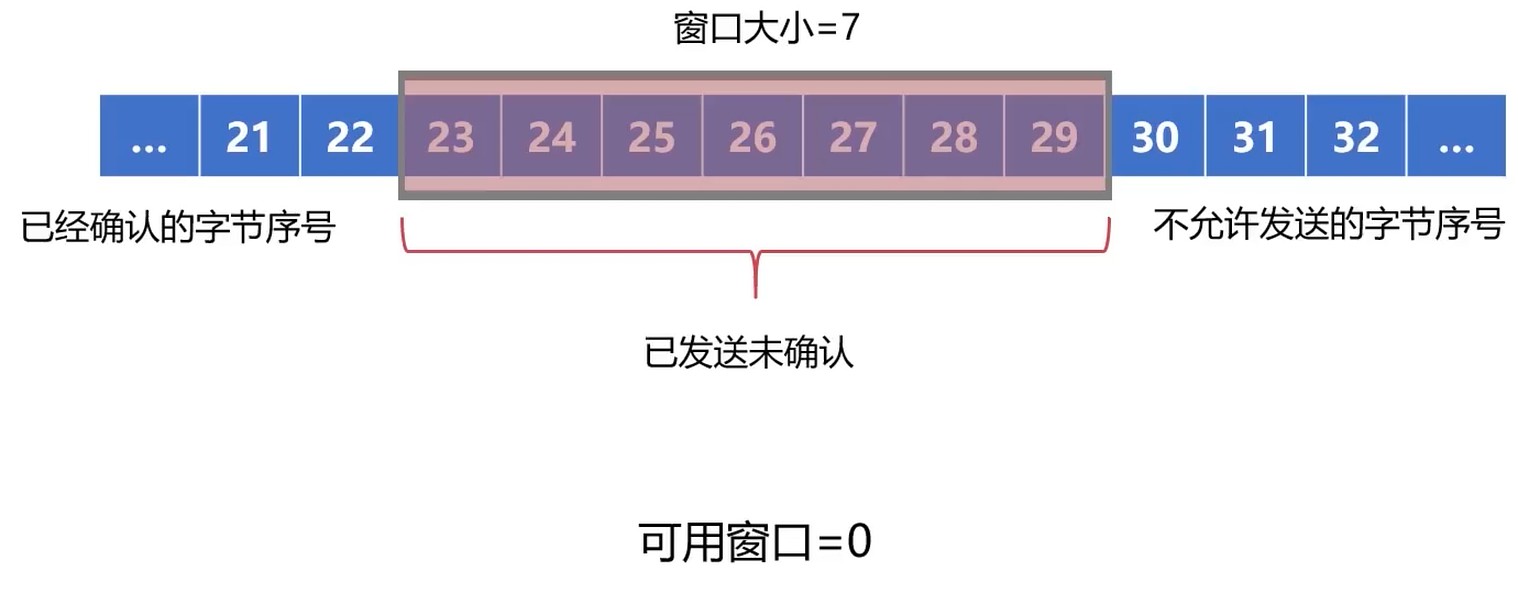
这样效率不高, 选择 重传 解决该问题.
- 选择重传需要指定需要重传的字节
- 每个字节都有唯一的32位序号
TCP选项最多40个字节, 就也是说最多存储10个序号, 而实际上选择重传更多是对一段字节(存储这一段的左右边界)进行重传的.
TCP流量控制
- 流量控制指让对方的发送速率不要太快
- 流量控制是通过滑动窗口来实现的.
窗口指明了允许对方发送的数据量
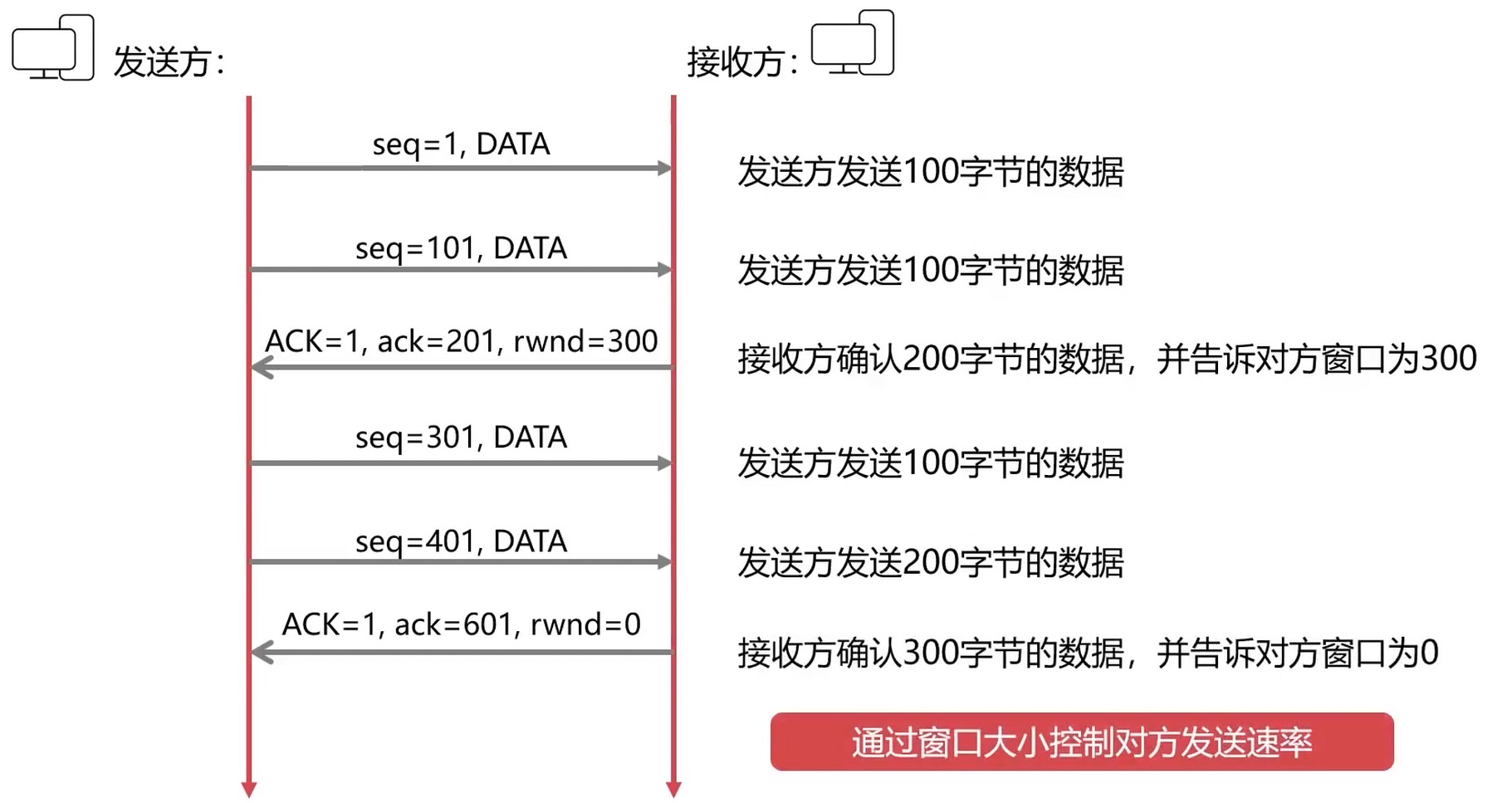
流量控制-双方都在等待, 造成死锁?
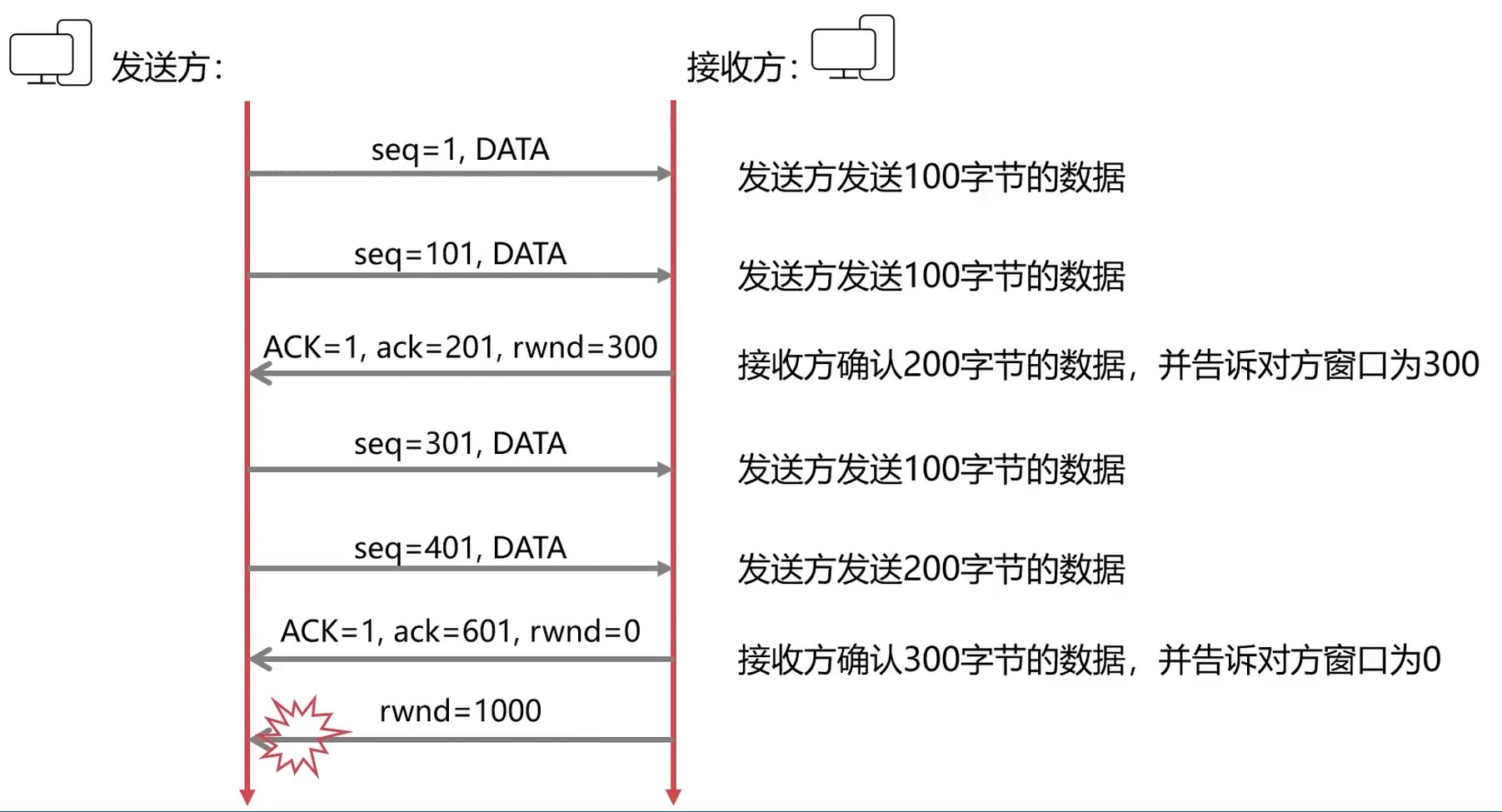
坚持定时器
- 当接收到窗口为0的消息, 则启动坚持定时器
- 坚持定时器每隔一段时间发送一个窗口探测报文
滑动窗口过程
TCP会将数据拆分成段进行发送. 出于效率和传输速度的考虑, 不可能等数据一段一段地发送后确认, 这样效率是非常低的. 所以要实现数据的批量发送, 而要解决可靠传输以及包断续的问题, 要知道网络传输过程中的速率, 这样才不会造成网络阻塞而导致丢包.

中间是发送中的. 浅绿色是已经发送了, 但是还没有确认 ACK 的.


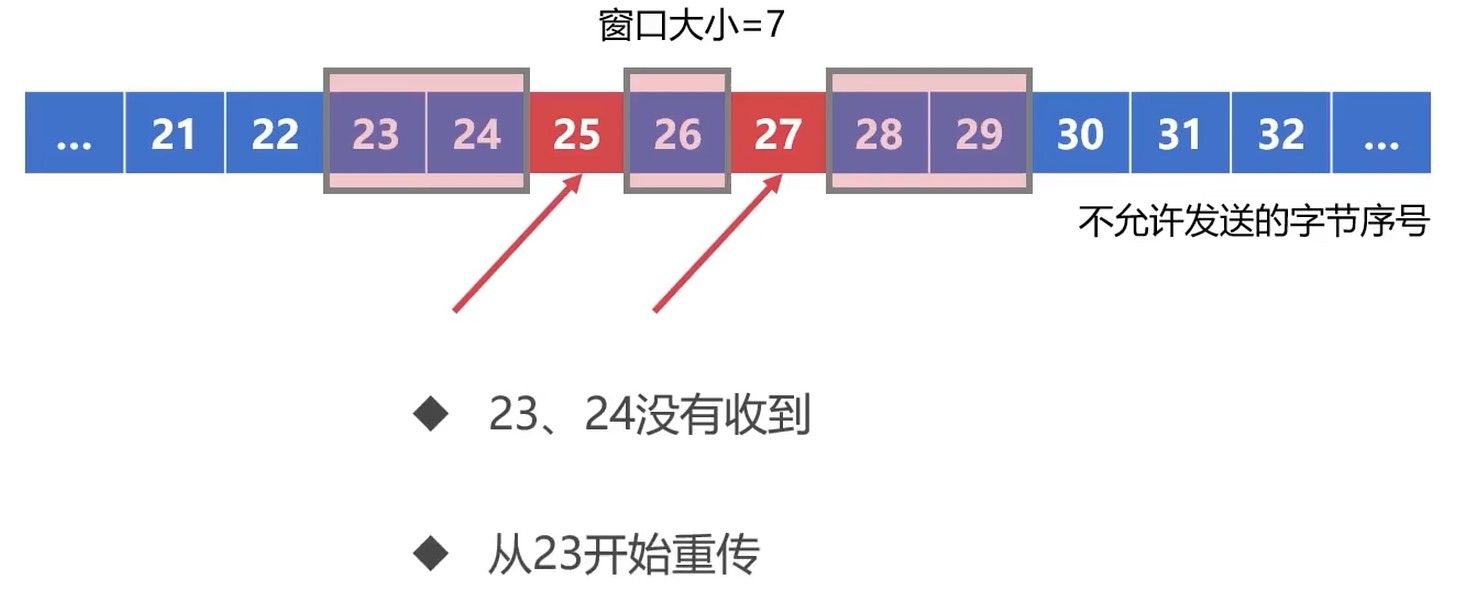
一部分数据丢失, 超时. 这种情况会把整个窗口进行重新发送.

虽然重发了, 但是保证了可靠性.
控制窗口的大小控制了带宽的大小.
滑动窗口解决了可靠性和传输速率(流量控制)的问题.
滑动窗口体现了TCP面向字节流的设计思路.
窗口数据的计算过程
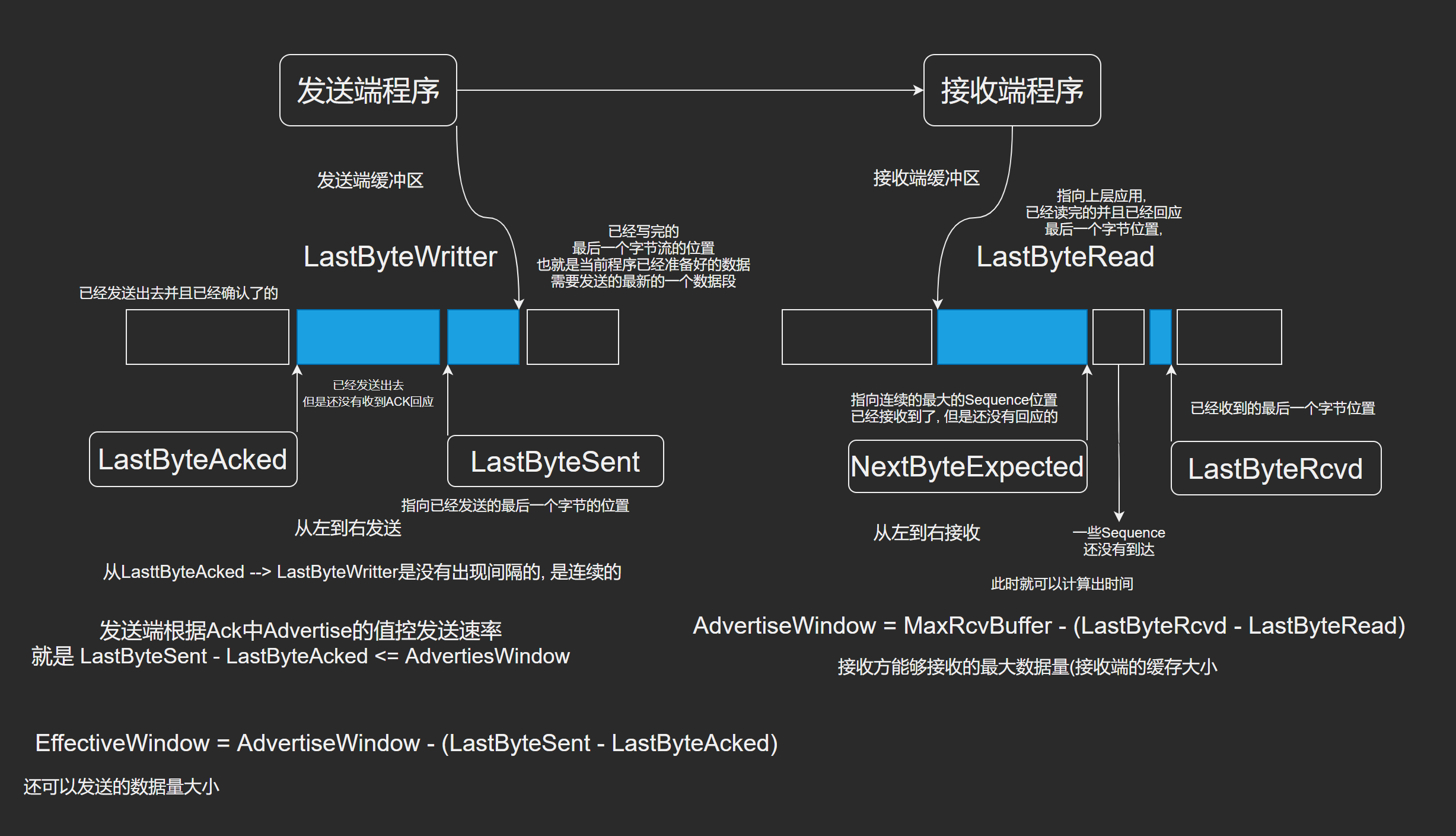
- AdvertiseWindow = MaxRcvBuffer - (LastByteRcvd - LastByteRead)
- EffectiveWindow = AdvertiseWindow - (LastBytSent - LastByteAcked
TCP拥塞控制
需要控制的原因
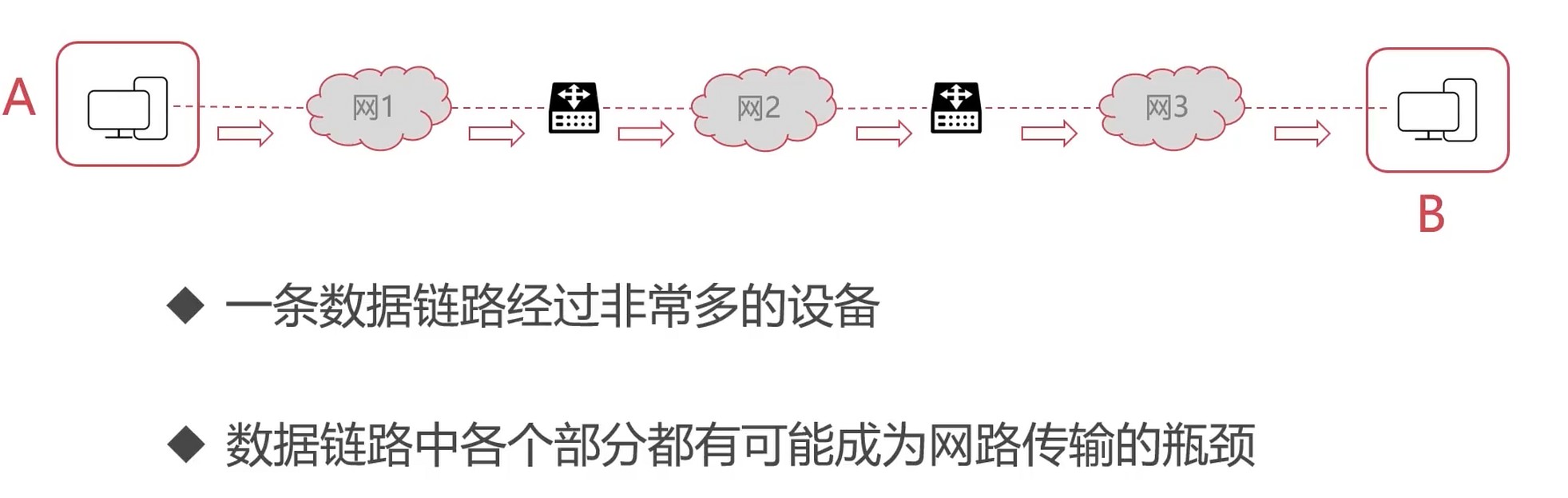
与流量控制的区别
- 流量控制考虑点对点的通信量的控制
- 拥塞控制考虑整个网络, 是全局性的控制
报文超时则认为是拥塞了.
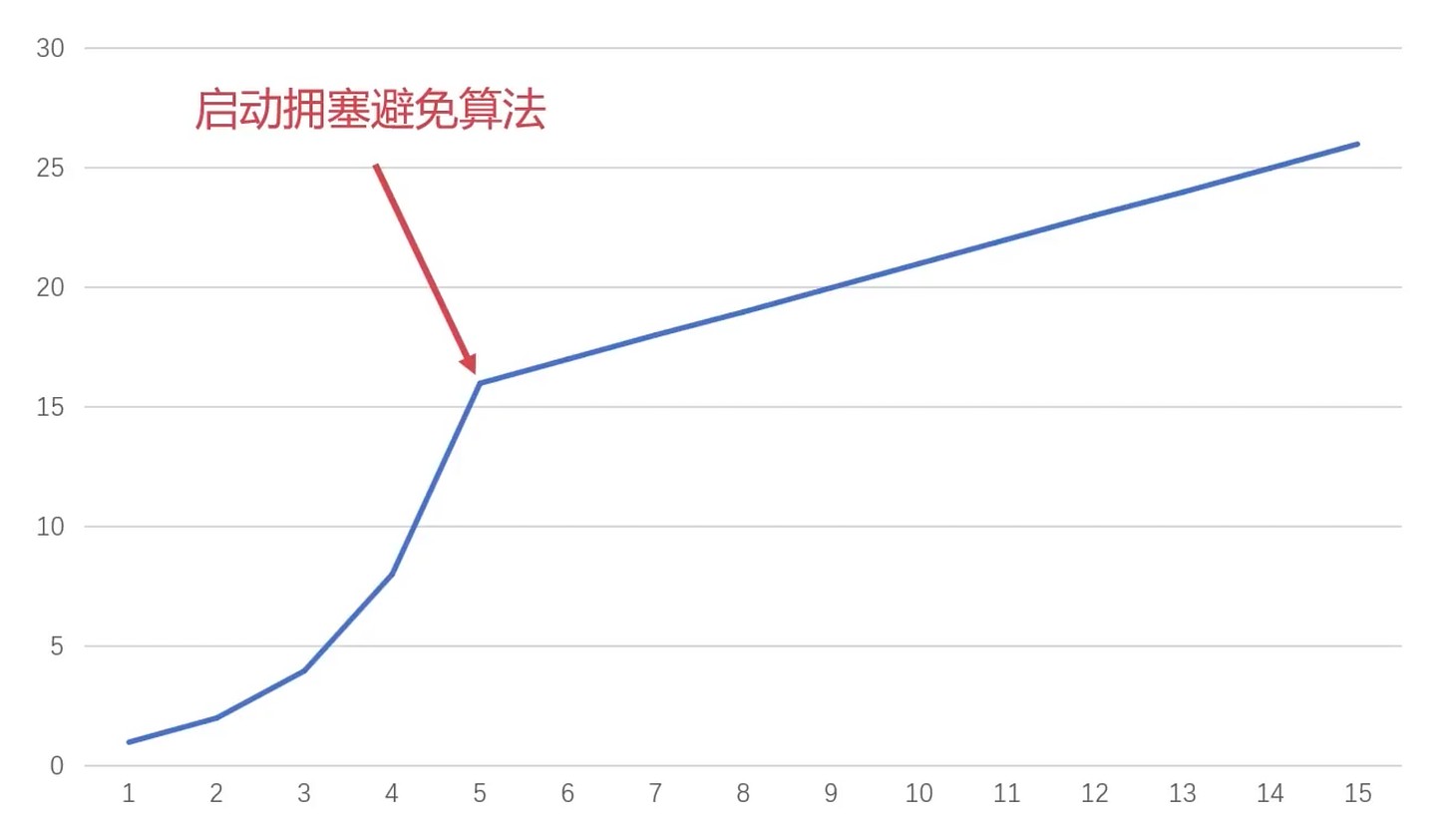
慢启动算法
- 由小到大逐渐增加发送数据量
- 每收到一个报文确认, 就加一(1 2 4 8 16…), 指数增长
增长到阈值, 这个阈值叫做 慢启动阈值(ssthresh)
拥塞避免算法
- 维护一个拥塞窗口的变量
- 只要网络不拥塞, 就试探把拥塞窗口调大
TCP连接
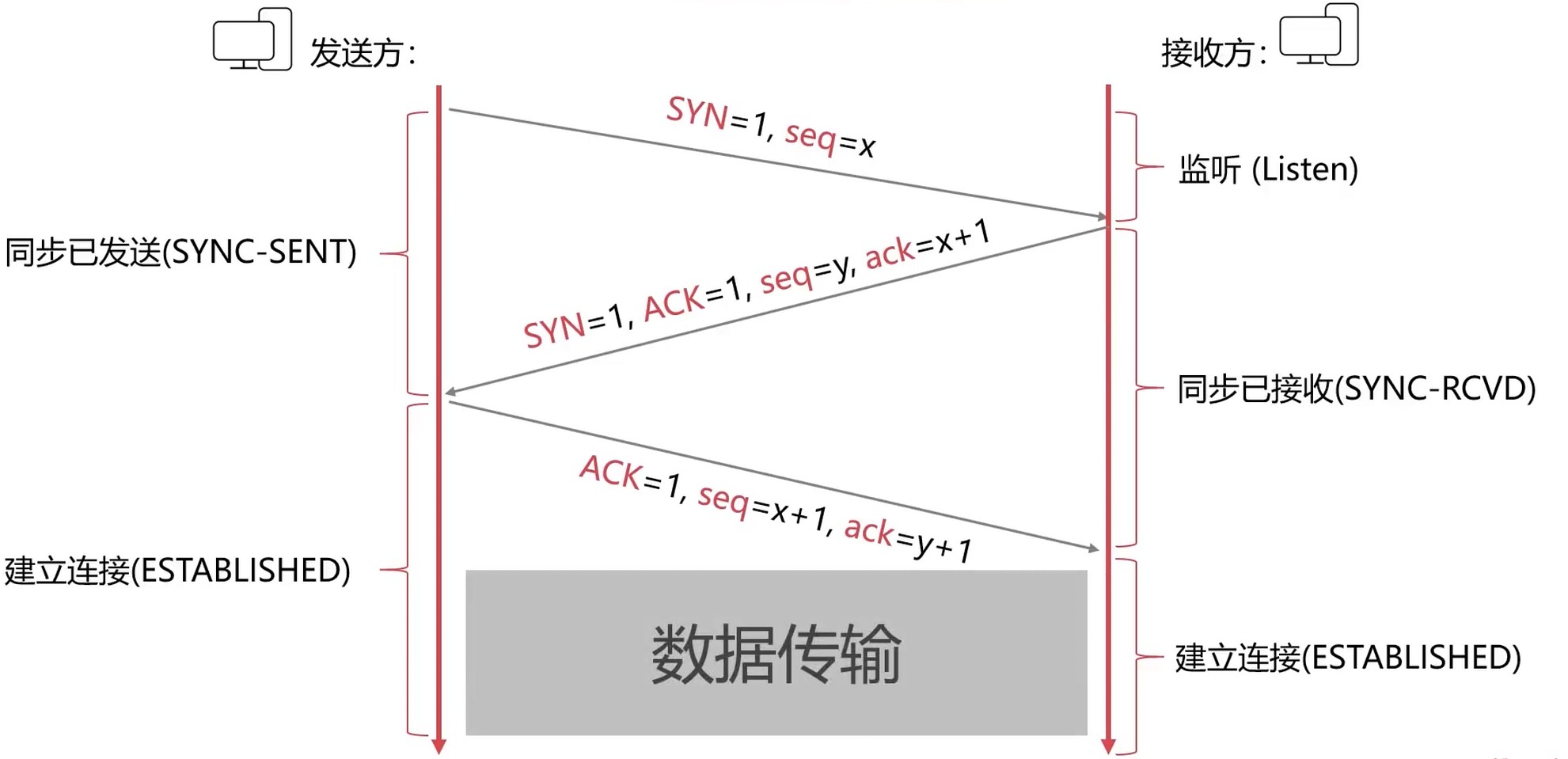
建立–三次握手
TCP标记, 6位各有不同的意义. ACK, SYN, FIN 这几个是TCP进行连接关联到的.
ack=seq+1, seq=ack
对于发送方来说, 第二次握手成功就已经建立连接了; 对于接收方来说, 第三次握手才算建立连接.
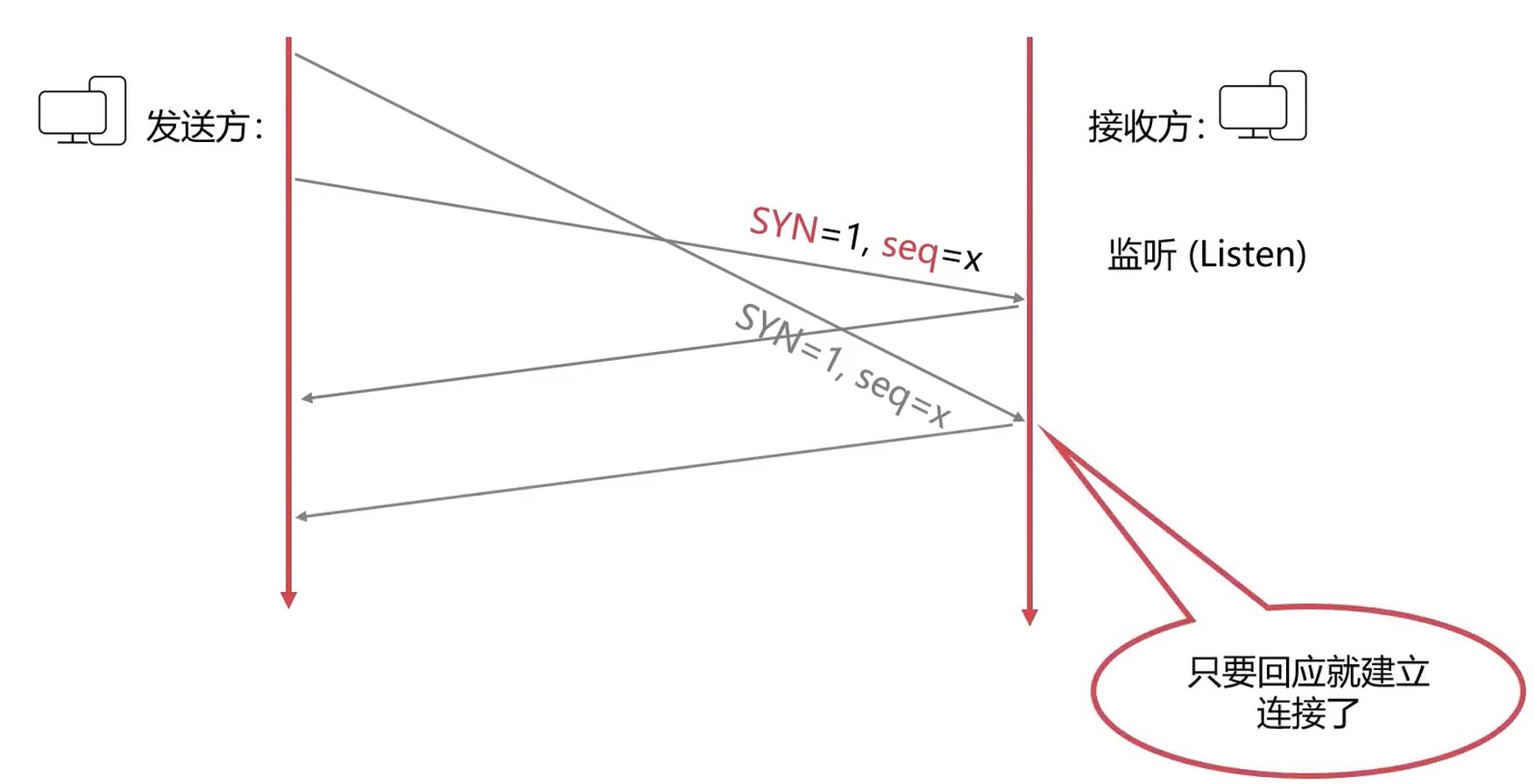
问题: 问什么发送方要发出第三个确认报文?
- 避免已经失效的连接请求报文传到对方, 引起错误
发送方第一次发送很久才到达接收方, 以致于超时了, 第二次再次发送建立连接的请求, 这个请求很快就到达了. 这时候第一个请求就属于 失效的请求报文 了. 而接收方又回复的话, 这样就相当于建立2个连接了.
如果第一个请求收到了ack, 会被忽略掉, 因为第三次握手已经建立连接了.
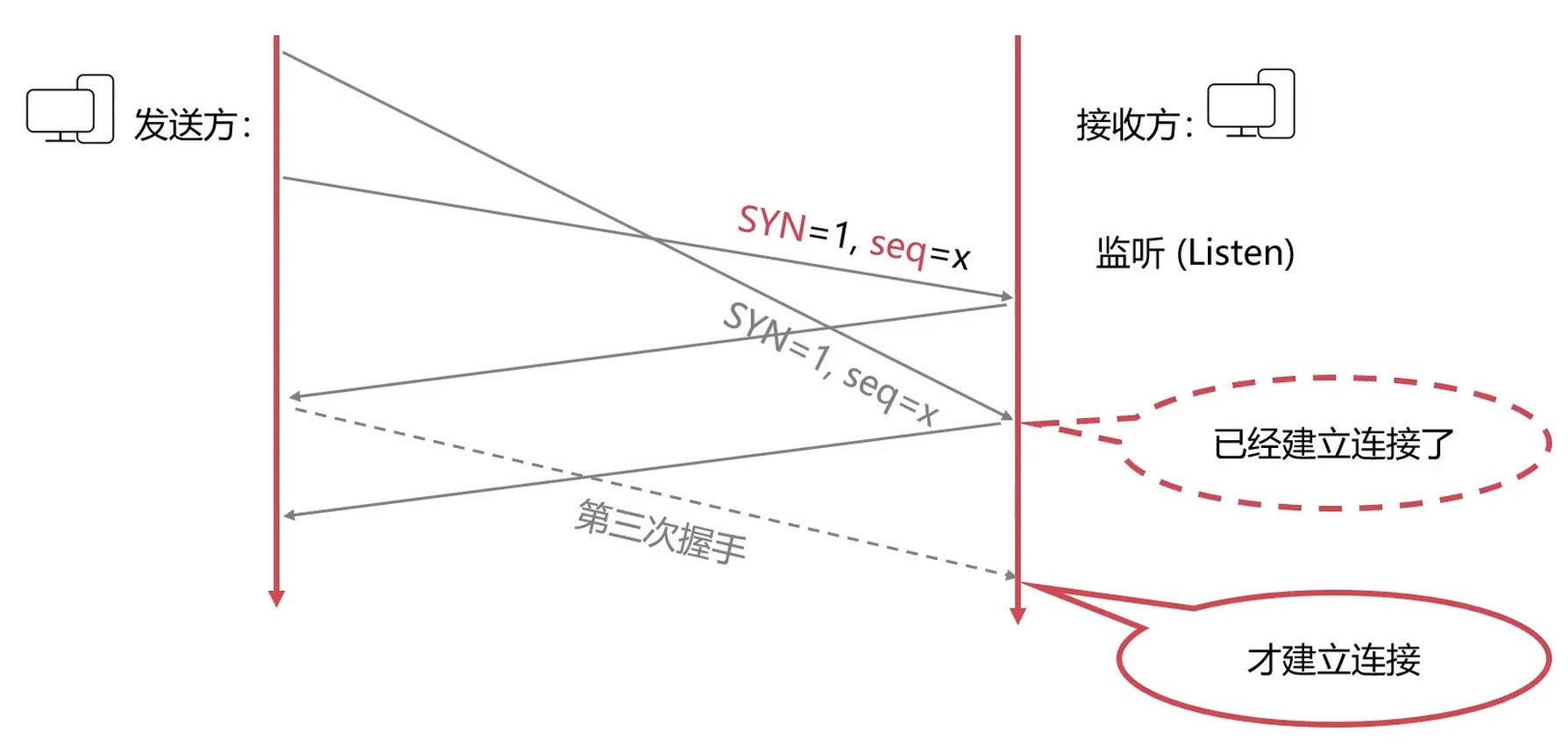
使用 Wireshark 查看三次握手
首先请求一个http, 然后通过http过滤找到目标ip.
再通过表达式 ip.dst==172.67.170.65 or ip.src==172.67.170.65 过滤出完整的请求过程. 关注一个端口号, 观察完整的一个握手流程.
本例子的是 client:8743 -> server:80.
- 客户端发送
SYN包, [SYN]seq=0 - 服务端接收到后发送确认包, [SYN, ACK]seq=0, ack=0+1
- 客户端接收到后回发, [ACK]seq=0+1, ack=0+1, 三次握手完毕, 建立链接

注意: 会发送Win的大小, 用来控制速率的.
握手是为了建立连接.
- 第一次握手: 建立连接时, 客户端发送
SYN包(syn=j)到服务器, 并进入SYN_SEND状态, 等待服务器确认. - 第二次握手: 服务器收到
SYN包, 必须确认客户的SYN(ack=j+1), 同时自己也发送一个SYN包(syn=k), 即SYN+ACK包, 此时服务器进入SYN_RECEIVED状态. - 第三次握手: 客户端收到服务器的
SYN+ACK包, 向服务器发送确认包ACK(ack=k+1), 此包发送完毕, 客户端和服务端进入ESTABLISHED状态, 完成三次握手.
释放–四次挥手
ack=seq+1, seq=ack
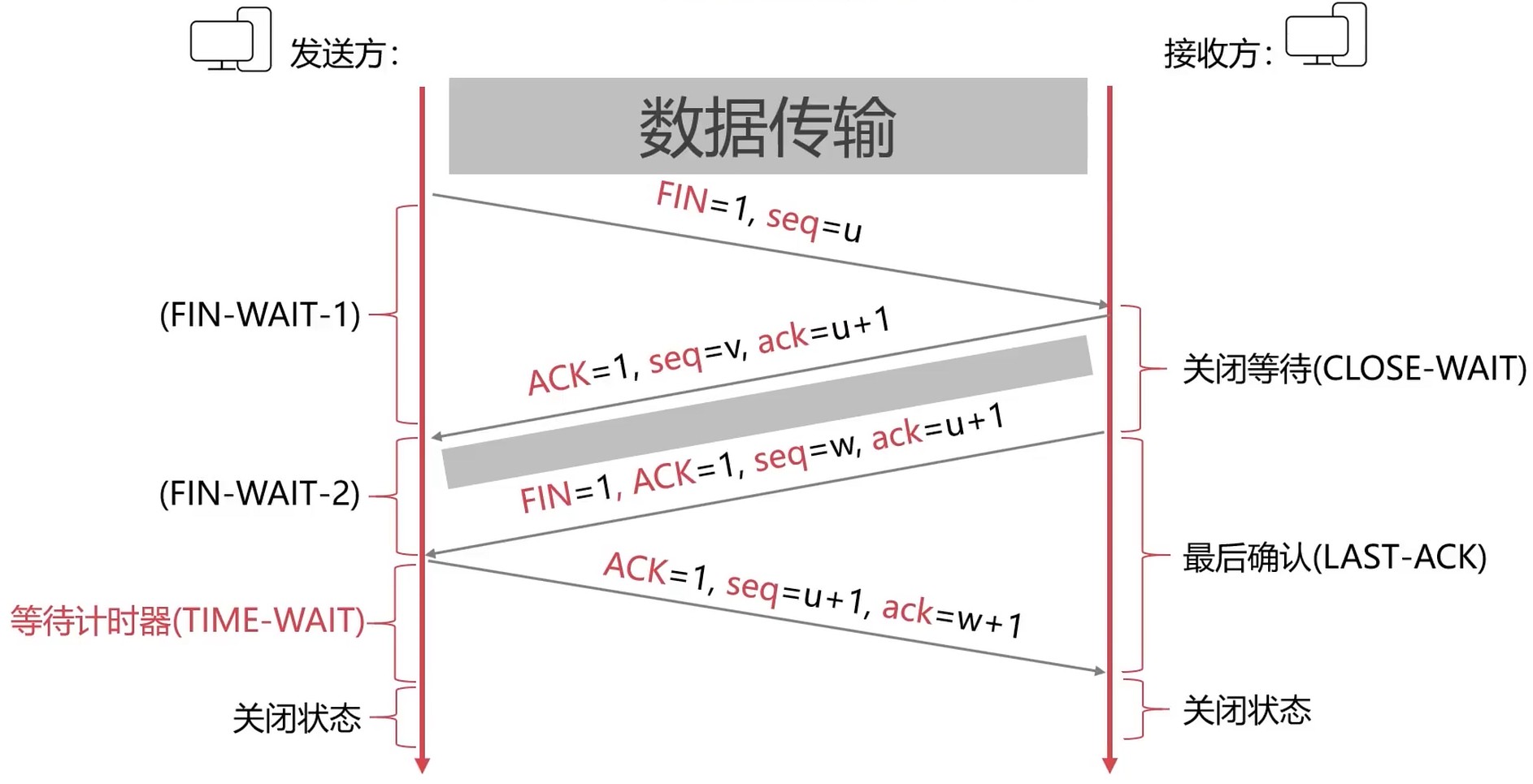
接收方: CLOSE-WAIT 阶段通知应用程序关闭连接. 关闭成功之后, 进行第三次挥手. 发送方收到之后, 进行第四次挥手.
等待计时器
等待 2MSL 时间. MSL: Max Segment Lifetime, 最长报文段寿命.
MSL建议设置为2分钟.
等待阶段是不会释放端口的. 所以会发现, 释放连接后, 马上复用端口是不行的. 只能等待 2MSL 之后才能复用.
为什么需要等待 2MSL?
- 等待最后一个报文可以被接收方确认到
- 确保发送方的 ACK 可以达到接收方, 如果没有收到, 被动关闭方可以重发
FIN包, 这样一来一回2个MSL. - 2MSL 时间内没有接收到, 则接收方会重发
- 确保当前连接的所有报文都已经过期
查看 MSL 的值, 在
/proc/sys/net/ipv4/tcp_fin_timeout这个文件.
为什么需要四次挥手?
因为是全双工的, 数据是两个方向传输的. 本质上就是双端都要挥手2次以确认断开连接, 只不过有一方是被动的.
服务器出现大量CLOSE_WAIT状态的原因
客户端一直在请求, 但是返回给客户端的信息是异常的, 服务端压根就没有收到请求.
看流程图可以知道, 在接收到对端FIN报文之后, 程序没有进一步发送ACK报文, 对端就处于CLOSE_WAIT状态了.
对端关闭socket连接, 我端忙于读或写, 没有及时关闭连接(发送FIN报文).
- 检查代码, 特别是释放资源的代码
- 检查配置, 特别是处理请求的线程配置
linux 下查看连接情况
# 查看各个程序下的连接数
netstat -n | awk '/^tcp/{++S[$NF]}END{for(a in S) print a, S[a]}'
如果查看到的CLOSED_WAIT好多, 那么就需要去排查问题了.
因为对于linux来说, 会为每个用户提供有限的文件句柄数, 而连接和文件句柄是一一对应的, CLOSED_WAIT 状态的保持意味着对应数目的通道被占用着, 一旦达到了上限, 那么新的请求就无法处理了, 接着就是大量的 too many files 异常.`
可能造成软件服务的 crash, Tomcat, Nginx, Apache etc.
套接字
- 使用端口(port)来标记不同的网络进程
- 端口(port)使用16比特位表示(0~65535)
- 套接字是抽象概念. 表示TCP连接的一端
- 通过套接字可以进行数据发送或者接收
TCP={Socket1:Socket2}={{IP:Port}{IP:Port}},TCP连接由两个套接字组成
被动连接的一方
创建套接字 -> 绑定套接字 -> 监听套接字 -> 接收&处理信息
主动连接的一方
创建套接字 -> 连接套接字 -> 发送信息
网络套接字 VS 域套接字

而域套接字, 是通过域套接字文件(s)进行传输的, 数据是不经过TCP/IP协议栈的, 所以单机通信的话, 推荐使用域套接字。
应用层
DNS
DNS: Domain Name System, 域名系统
IP+Port, 可以指定网络中的唯一进程.

- 域名由点, 字母和数字组成
- 点分割不同的域
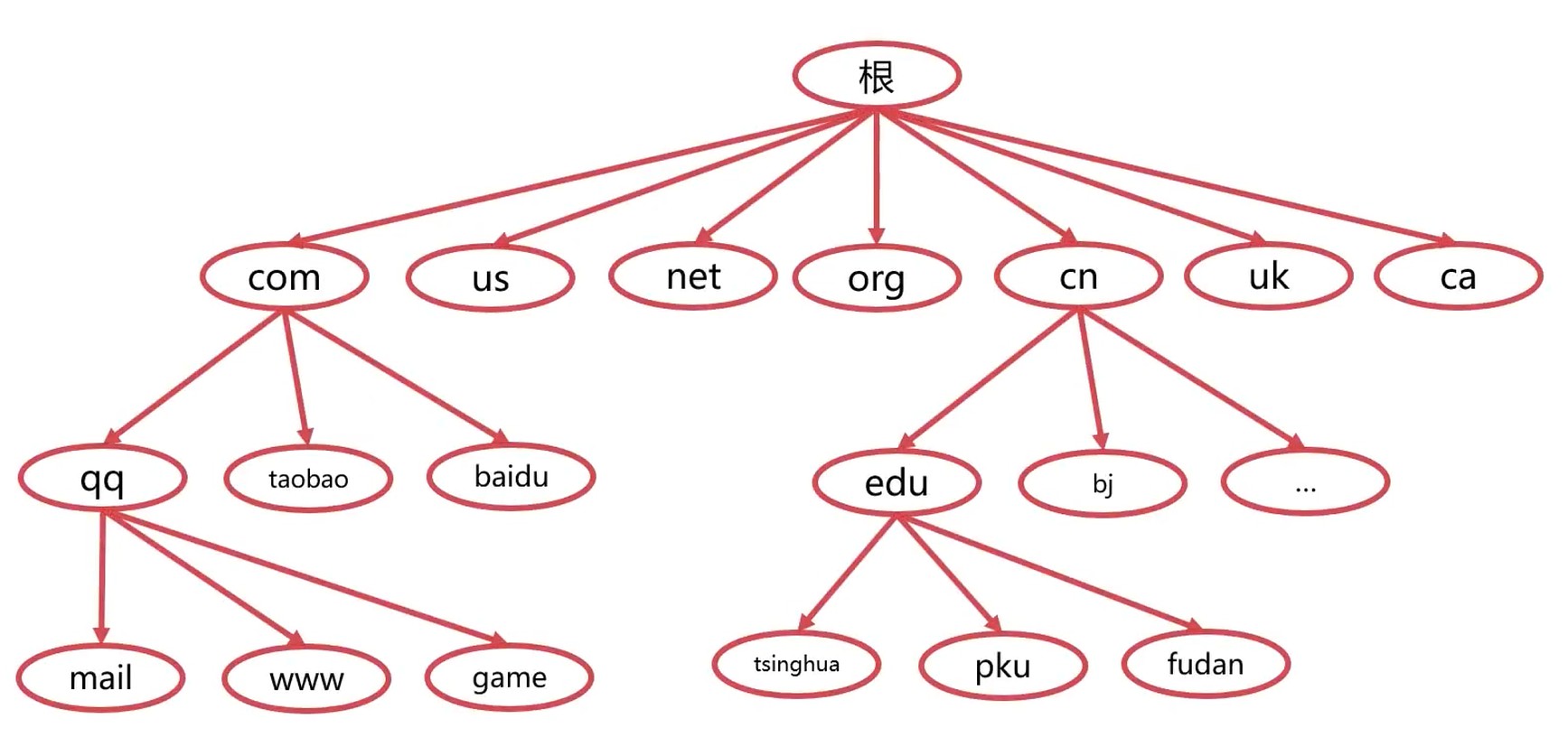
- 域名可以分为顶级域, 二级域, 三级域(www.baidu.com, com顶级域, baidu二级域, www三级域)
顶级域
- 国家
- cn, us, uk, ca
- 通用
- com, net, gov, org
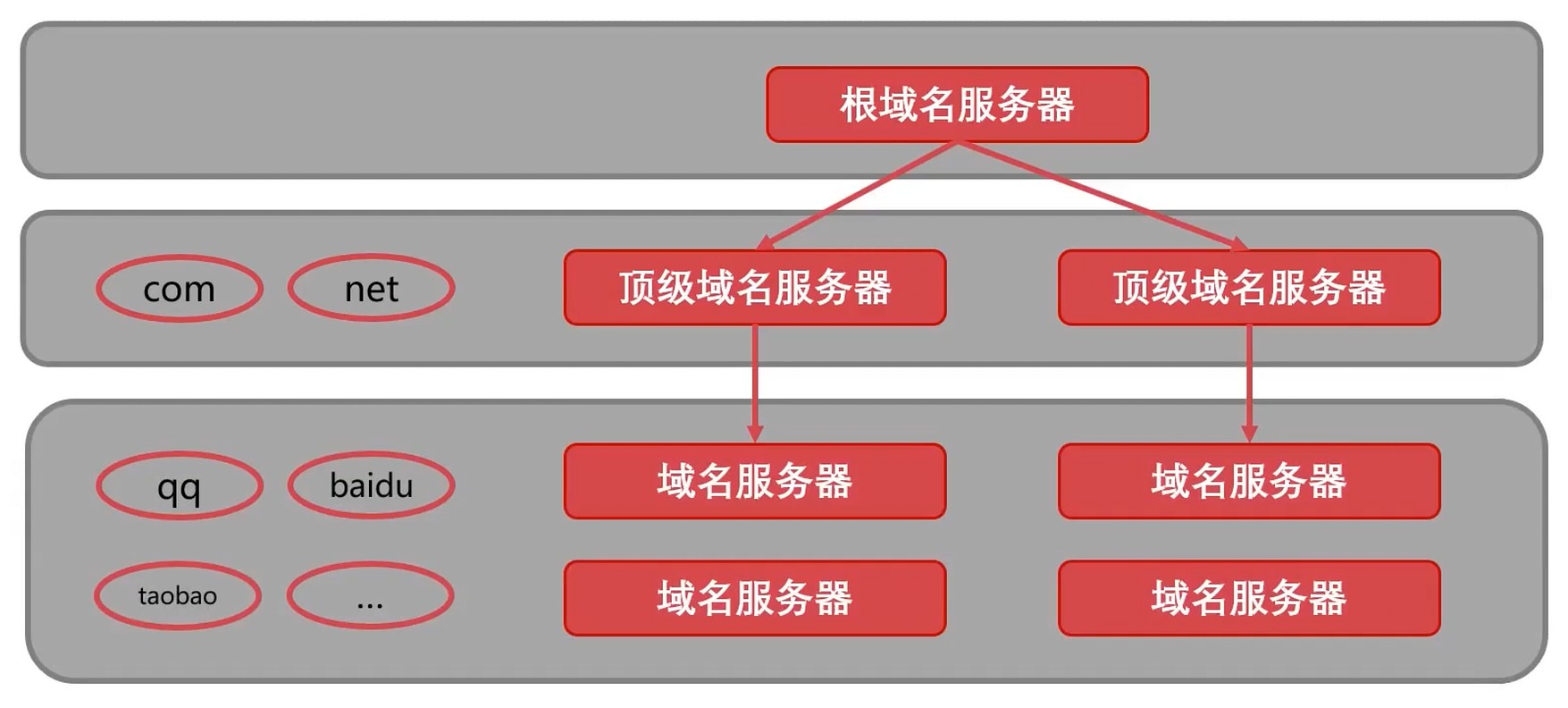
域名服务器
DHCP
DCHP: Dynamic Host Configuration Protocol, 动态主机设置协议
一个局域网的协议; 是应用UDP协议的应用协议.
提供了 即插即用联网 的功能
临时IP
租期
DHCP服务器监听默认端口: 67
主机使用UDP协议广播DHCP发现报文
DHCP服务器发出DHCP提供报文
主机向DHCP服务器发出DHCP请求报文
DHCP服务器回应并提供IP地址
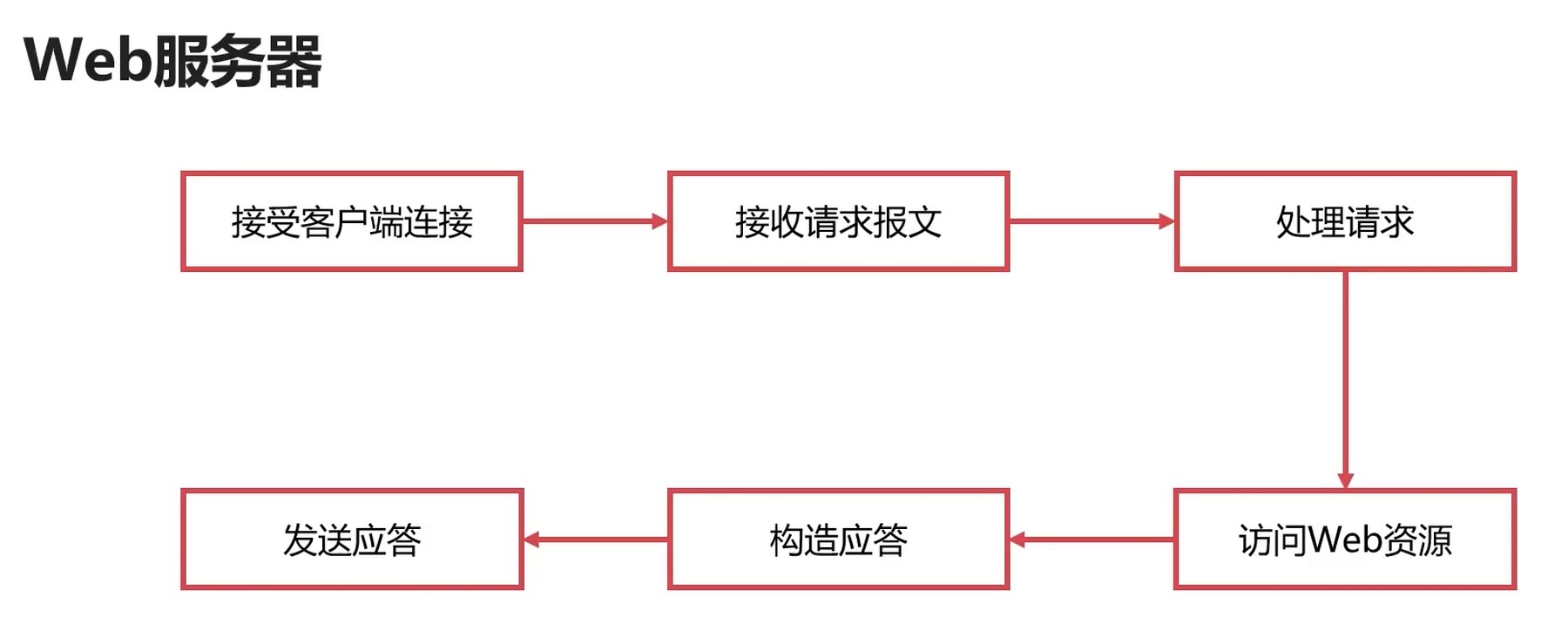
HTTP
HTTP: HyperText Transfer Protocol, 超文本传输协议.
- HTTP协议是可靠的数据传输协议

http方法

http结构–请求报文和应答报文

请求头(多行, 以空行结束)
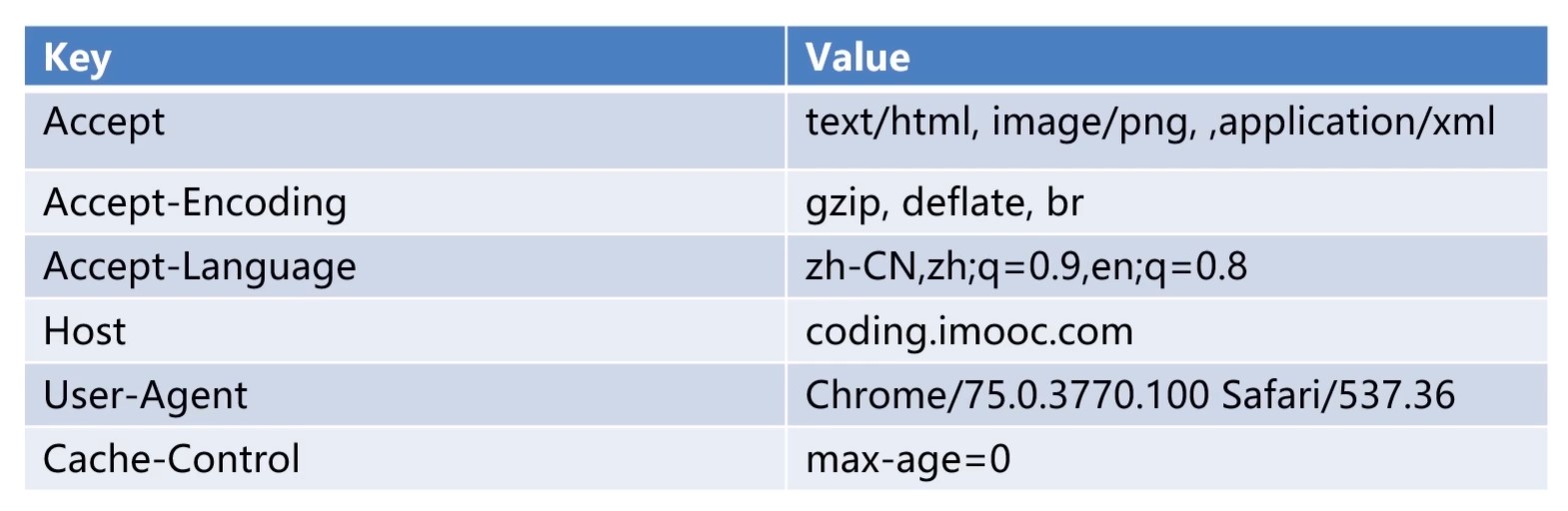
请求内容(不是必须的)
- 发送数据
一个完整的请求

Context-Length 请求内容的长度
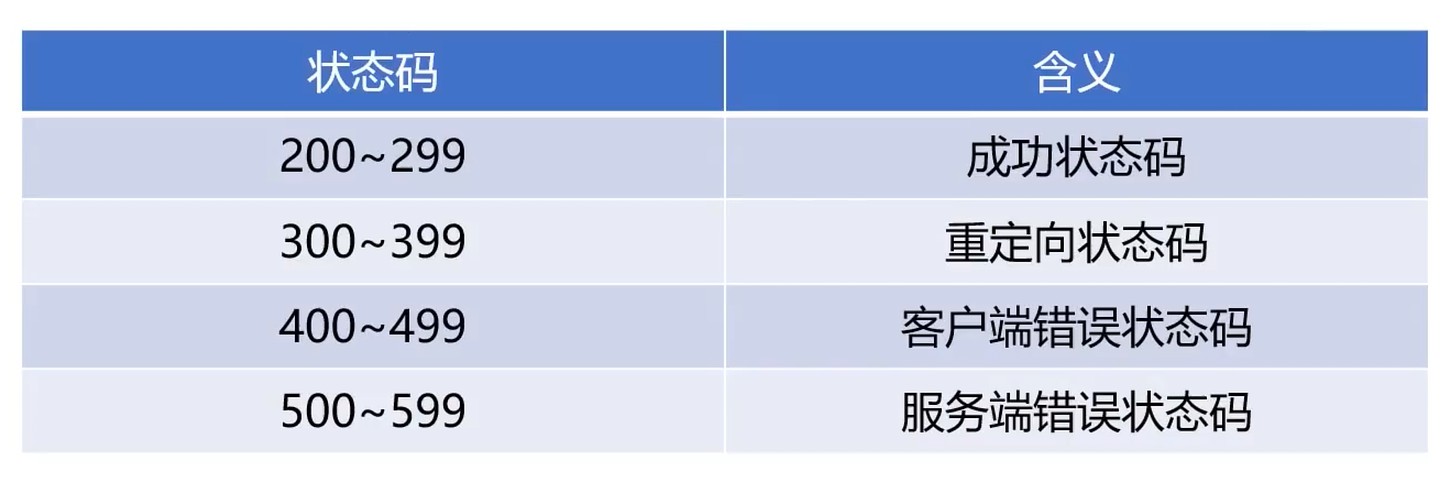
应答状态码
应答头
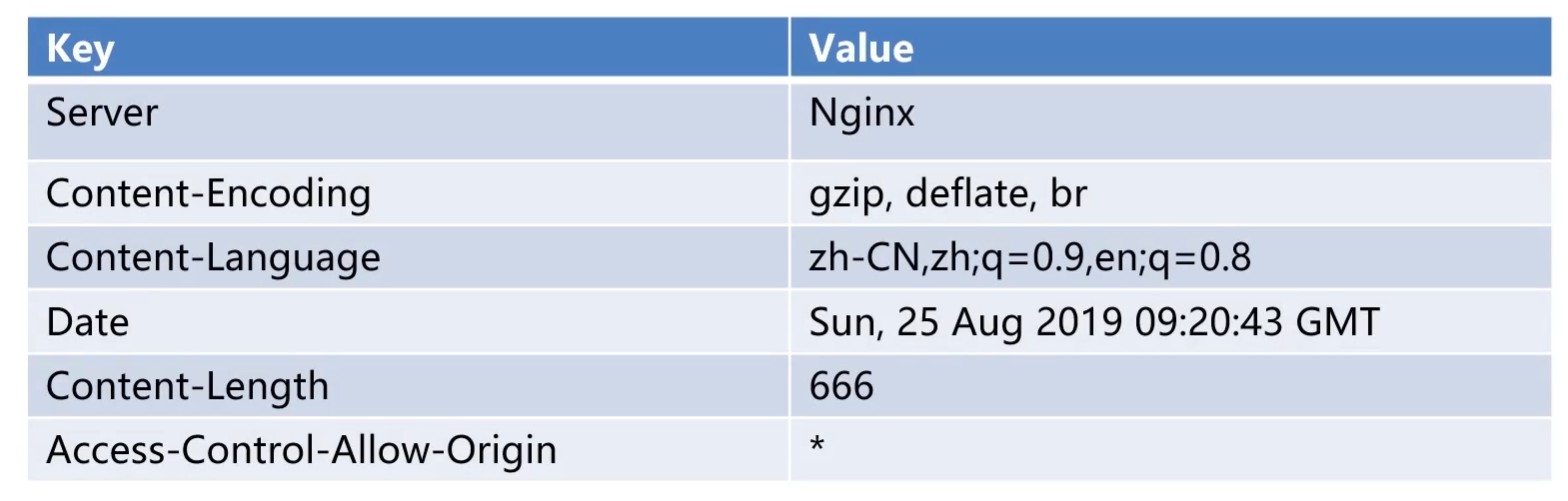
一个完整的应答

GET和POST请求的区别
从三个层面
- Http报文层面: GET请求将请求信息放在URL, POST放在报文体中(要获取信息必须解析报文体), 安全性两者没啥区别. 由于GET请求把信息放在URL中, 而浏览器对URL长度是有限制的.
- 从数据库层面: GET符合幂等性(对数据的操作, 一次或多次获取到的结果是一致的)和安全性(没有改变数据库的数据, 查询操作), POST不符合.
- 其他层面: GET可以被缓存(CDN), 被存储(书签), 而POST不行.
Cookie和Session的区别
HTTP是无状态的. Cookie和Session让HTTP有了状态.
Cookie是客户端的解决方案.
- 由服务器发送给客户端的特殊信息, 以文本形式存在客户端.
- 当用户再次请求的时候, 携带此
Cookie信息, 存放在HTTP请求/响应头. - 当服务器接收到之后, 会生成
Cookie与客户端相对应的内容.
Cookie设置以及发送过程
- Http Request
- Http Response + Set-Cookie
- Http Request + Cookie
- Http Response
Session是服务器端的机制
- 在服务器端保存的信息.
- 解析客户端请求并操作
session id, 按需保存状态信息.
实现方式
- 使用
Cookie实现. 服务器为每个session分配一个唯一的JSESSIONID, 并通过Cookie发送给客户端. 当客户端再次发起请求的时候就把JSSESIONID放在Cookie域中. - 使用URL回写来实现. 指服务器在发送给客户端时所有URL中都携带
JSESSIONID参数.
不管使用哪种方式, 都离不开JSESSIONID.
区别:
Cookie是存放在客户端的, 而Session是存放在服务端的.Session相对于Cookie更安全.- 若考虑减轻服务器的负担, 应该使用
Cookie.
HTTP应用
- Web缓存
- Web代理
- CDN
- 爬虫
Web缓存
Web代理
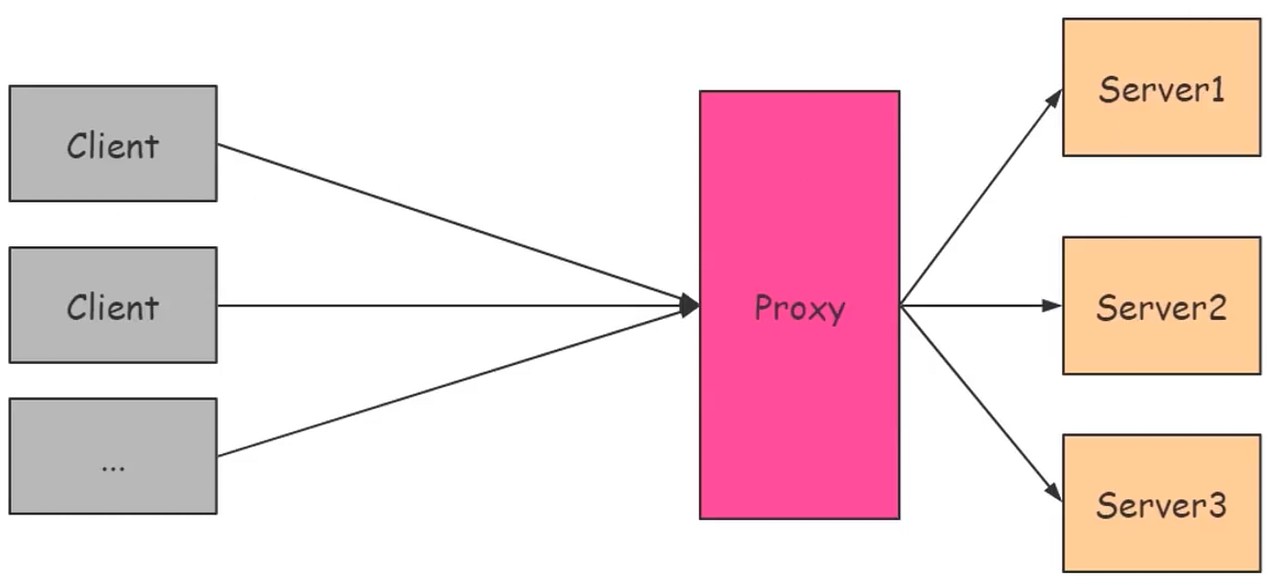
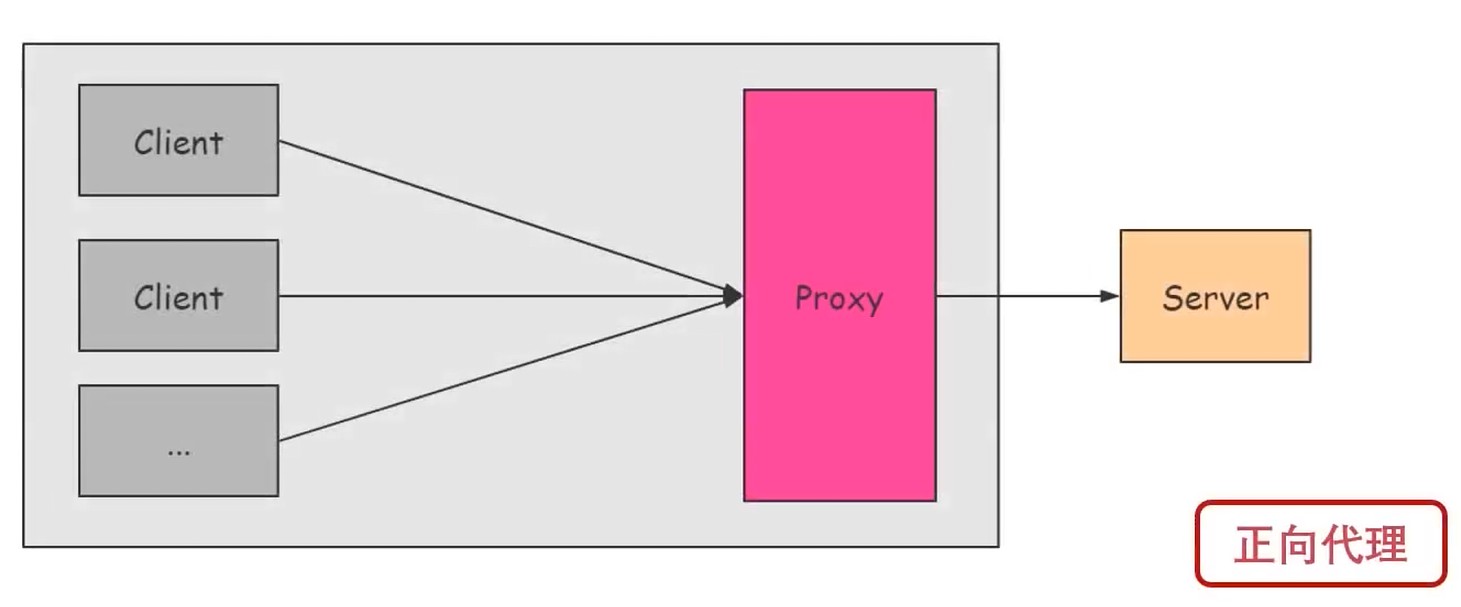
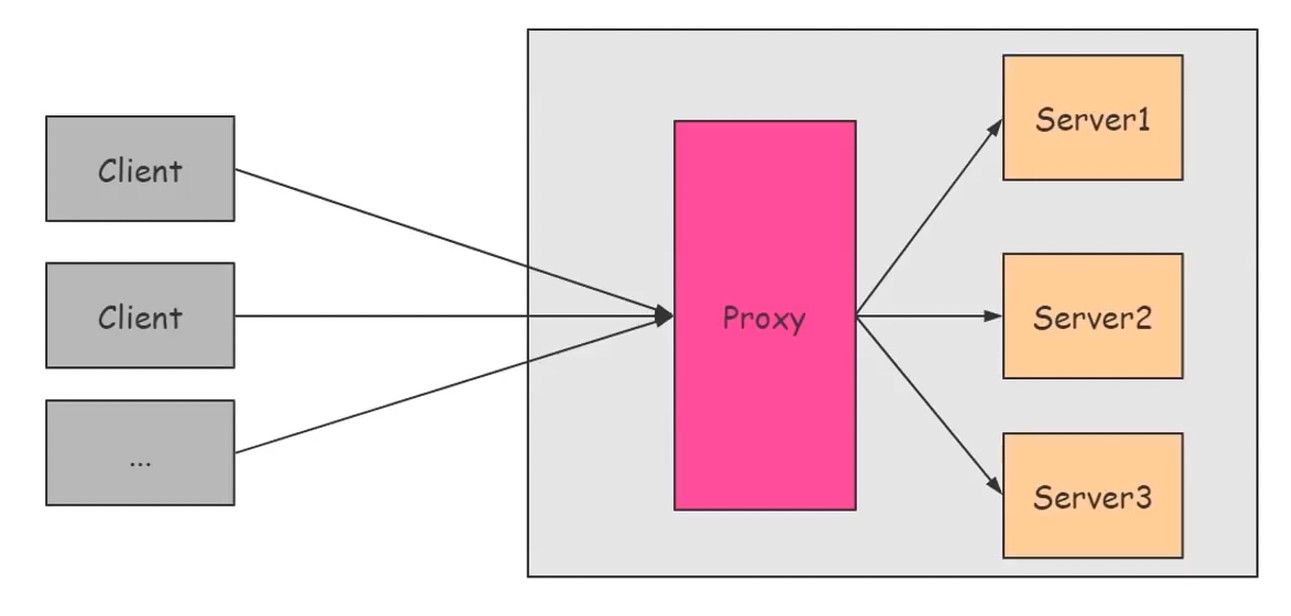
CDN: Content Delivery Network, 内容分发网络
爬虫, 网络机器人
- 增加网络拥塞
- 损耗服务器资源
HTTPS
- HTTP是明文传输的
- HTTPS(Secure)是安全的HTTP协议
加密模型
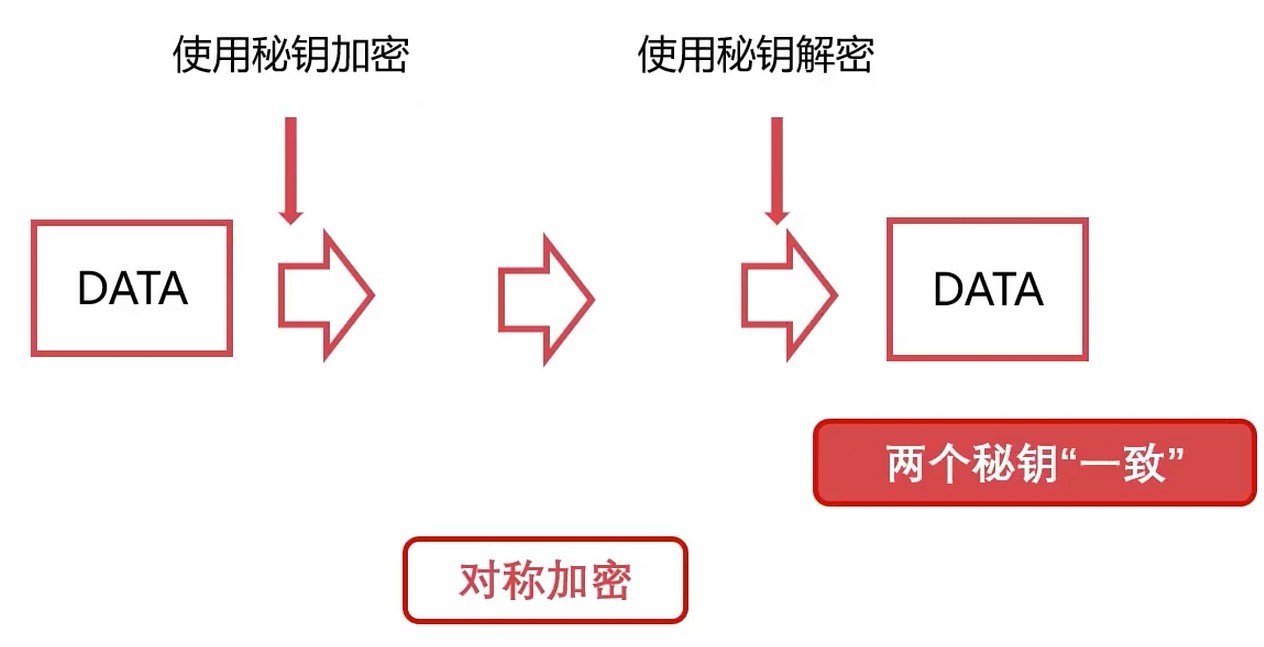
对称加密
非对称加密
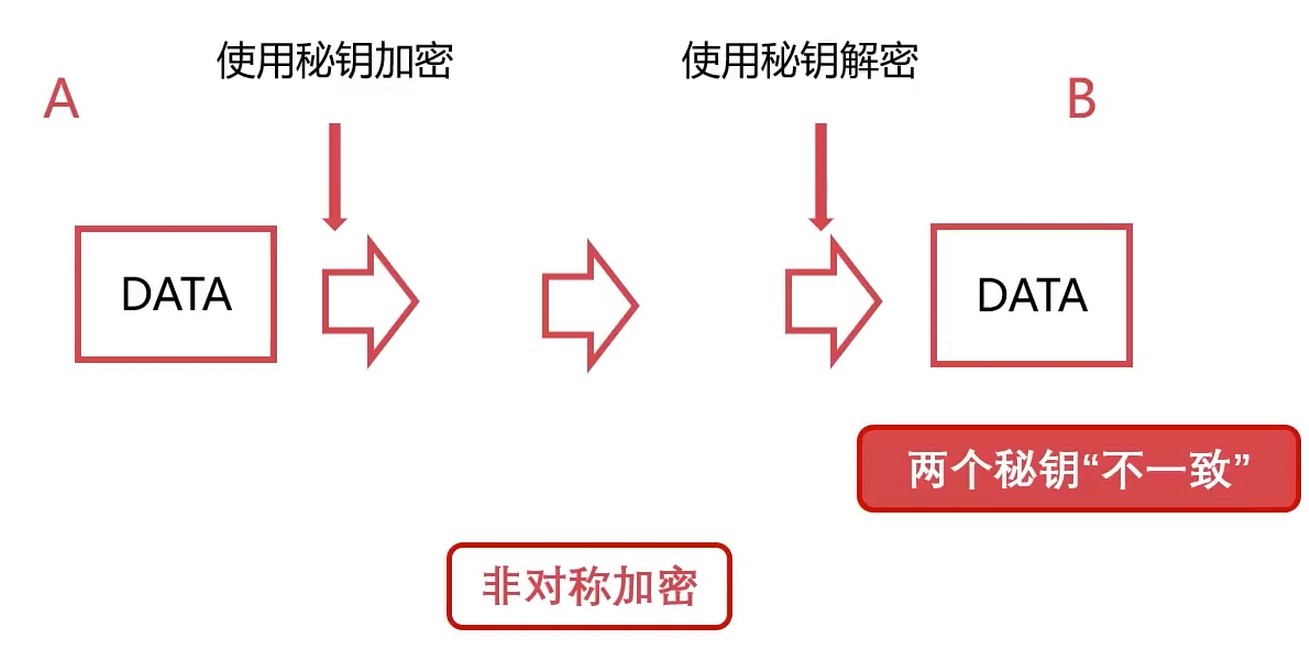
- A, B是拥有一定数学关系的一组密钥
- 私钥: 私钥自己使用, 不对外公开
- 公钥: 公钥对外使用, 对外公开
数字证书
- 由可信任组织颁发给特定对象的认证

SSL: Secure Sockets Layer, 安全套接层. SSL 3.0 之后叫 TLS.

- 数据安全和数据完整
- 对传输层的数据进行加密后传输
https通信过程
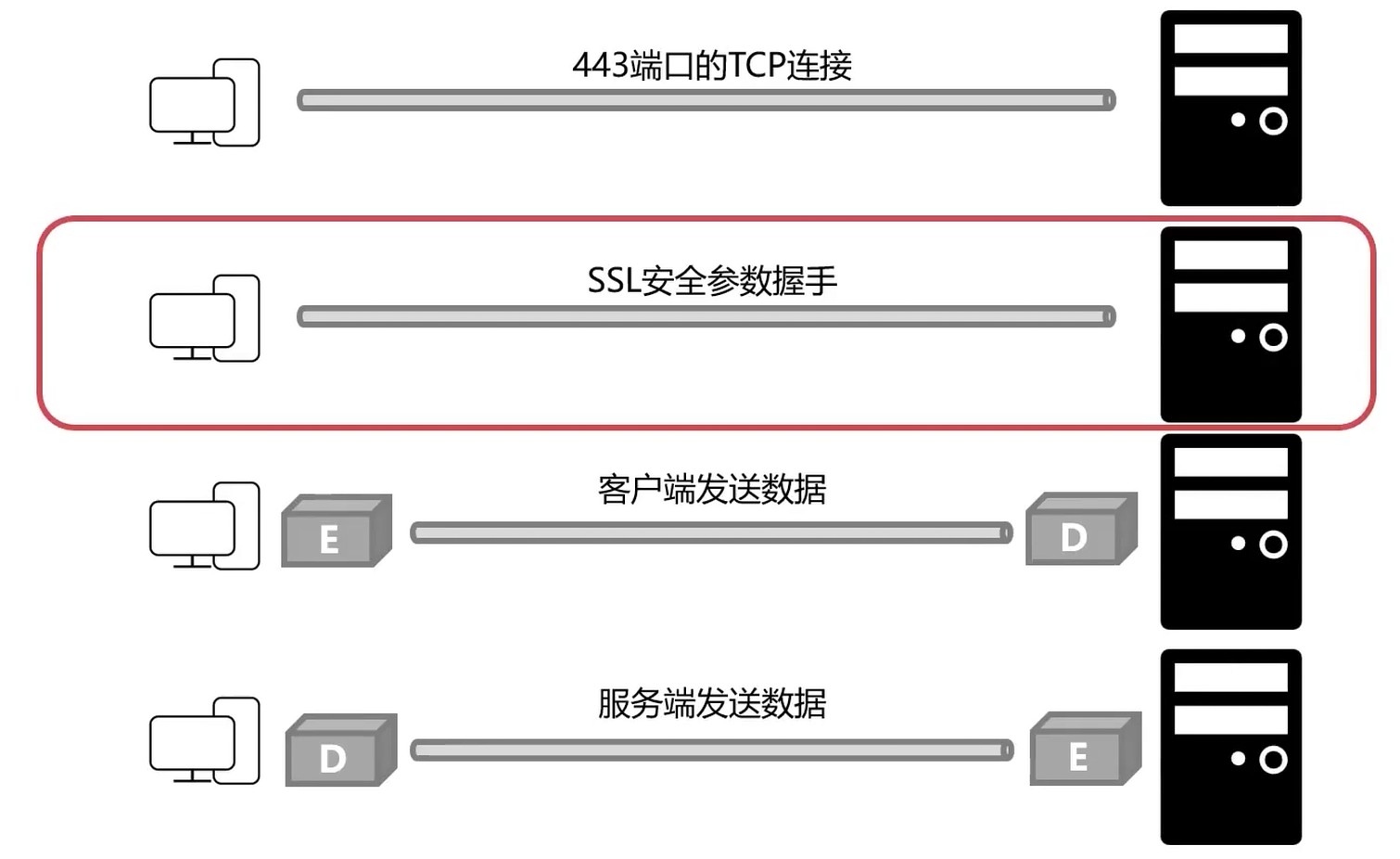
SSL安全参数握手
- 客户端发送 随机数1, 协议版本, 支持的机密算法 到 服务端
- 服务端发送 确认要使用的加密算法, 数字证书, 随机数2
- 客户端验证证书是否有效
- 如果有效的话, 从证书中取出公钥
- 生成随机数3, 并使用公钥加密随机数3
- 然后把 随机数1, 随机数2, 随机数3 发送给服务端
- 双端使用确认的加密算法对 随机数1, 随机数2, 随机数3 生成对称密钥
- 之后双端使用对称密钥进行加密通信

这时候, 服务端和客户端之间的信息是对称的. 然后根据随机数1, 2, 3用相同的算法生成一个对称密钥.

之后, 双方就可以使用对称密钥进行通信.

博客内容遵循 署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0) 协议
本文永久链接是:https://blog.lgq51233.xyz/2019/09/27/%E8%AE%A1%E7%AE%97%E6%9C%BA%E7%BD%91%E7%BB%9C/